







目录
Three aspects of Deep RL: noise, overestimation and exploration深度强化学习的三个方面:噪声、高估和探索
Part 1. In efforts to overcome overestimation第 1 部分。努力克服高估
Part 2. Exploration as a major challenge of learning第 2 部分。探索是学习的一大挑战
App. Hill-Climbing algorithm with adaptive noise具有自适应噪声的爬山算法
Three aspects of Deep RL: noise, overestimation and exploration
深度强化学习的三个方面:噪声、高估和探索
Two faces of noise. Noise can be harmful, it can lead to a systematic overestimation. However, noise can be useful, such as noise for exploration.
噪音的两面。噪音可能是有害的,它可能导致系统性的高估。但是,噪声可能很有用,例如用于探索的噪声。

We touch on various sides of noise in Deep Reinforcement Learning models. Part 1 discusses overestimation, that is the harmful property resulting from noise. Parts 2 deals with noise used for exploration, this is the useful noise. In the appendix, we will look at one more example of noise: adaptive noise.
我们触及了深度强化学习模型中噪声的各个方面。第 1 部分讨论了高估,即噪声产生的有害属性。第 2 部分涉及用于勘探的噪声,这是有用的噪声。在附录中,我们将再看一个噪声示例:自适应噪声。
Part 1. We will see how researchers tried to overcome overestimation in models. First step is decoupling of the action selection from action evaluation. It was realized in Double DQN. The second step relates to the Actor-Critic architecture: here we decouple the value neural network (critic) from the policy neural network (actor). DDPG and TD3 use this architecture.
第 1 部分。我们将看到研究人员如何试图克服模型中的高估。第一步是将a ction 选择与行动评估脱钩。它是在双重 DQN 中实现的。第二步与 Actor-Critic 架构有关:这里我们将价值神经网络 (critic) 与策略神经网络 (actor) 解耦。DDPG 和 TD3 使用此体系结构。
Part 2. Exploration as a major challenge of learning. The main issue is exploration noise. We relate to models DQN, Double DQN, DDPG and TD3. Neural network models using some noise parameters have more capabilities for exploration and are more successful in Deep RL algorithms.
第 2 部分。探索是学习的一大挑战。主要问题是勘探噪声。我们涉及模型 DQN、Double DQN、DDPG 和 TD3。使用一些噪声参数的神经网络模型具有更多的探索能力,并且在深度强化学习算法中更成功。
Appendix. We consider the Hill-Climbing, the simple gradient-free algorithm. This algorithm adds adaptive noise directly to input variables, namely to the weight matrix determining the neural network.
附录。我们考虑 Hill-Climbing,一种简单的无梯度算法。该算法将自适应噪声直接添加到输入变量中,即添加到确定神经网络的权重矩阵中。
Part 1. In efforts to overcome overestimation
第 1 部分。努力克服高估
DQN and Double DQN algorithms turned out to be very successful in the case of discrete action spaces. However, it is known that these algorithms suffer from overestimation. This harmful property is much worse than underestimation, because underestimation does not accumulate. Let us see how researchers tried to overcome overestimation.
DQN 和 Double DQN 算法在离散动作空间的情况下非常成功。然而,众所周知,这些算法存在高估的问题。这种有害的性质比低估要糟糕得多,因为低估不会累积。让我们看看研究人员如何试图克服高估。
Overestimation in DQN.
DQN 中的高估。
The problem is in maximization operator using for the calculation of the target value Gt. Suppose, the evaluation value for Q(S_{t+1}, a) is already overestimated. Then from DQN key equations (see below) the agent observes that error also accumulates for Q(S_t, a) .
问题出在最大化算子用于计算目标值 Gt 时。假设 Q(S_{t+1}, a) 的评估值已经被高估了。然后,根据 DQN 关键方程(见下文),智能体观察到 Q(S_t, a) 的误差也会累积。
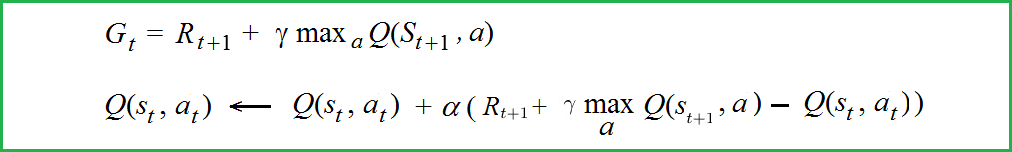
DQN key equation Q(s_t, a_t)
DQN 关键方程 Q(s_t, a_t)
Here, Rt is the reward at time t; Gt is the cumulative reward also know as TD-target; Q(s, a) is the Q-value table of the shape [space x action].
这里,Rt 是时间 t 的奖励;Gt 是累积奖励,也称为 TD-target; Q(s, a) 是形状 [space x action] 的 Q 值表。
Thrun and Schwartz in “Issues in Using Function Approximation for Reinforcement Learning” (1993) observed that using function approximators (i.e, neural networks) instead of just lookup tables (this is the basic technique of Q-learning) causes some noise on the output predictions. They gave an example in which the overestimation asymptotically lead to suboptimal policies.
Thrun 和 Schwartz 在“使用函数近似进行强化学习的问题”(1993 年)中观察到,使用函数近似器(即神经网络)而不仅仅是查找表(这是 Q 学习的基本技术)会在输出预测上产生一些噪声。他们举了一个例子,在这个例子中,高估渐近地导致了次优政策。
Decoupling in Double DQN.
双DQN中的去耦。
In 2015, Haselt et. al. in “Deep Reinforcement Learning with Double Q-learning” shown that estimation errors can drive the estimates up and away from the true optimal values. They supposed the solution that reduces the overestimation: Double DQN.
2015 年,Haselt 等人。在“Deep Reinforcement Learning with Double Q-learning”中指出,估计误差可以使估计值上升并远离真正的最优值。他们认为可以减少高估的解决方案:双倍 DQN。
The important thing that has been done in Double DQN is decoupling of the action selection from action evaluation. Let us make this clear.
在双重 DQN 中所做的重要事情是将动作选择与动作评估解耦。让我们明确一点。

Gt formula for DQN and Double DQN
DQN 和双倍 DQN 的 Gt 公式
- Gt formula for DQN: the Q-value
Q(S_t, a)used for the action selection (in red) and the Q-valueQ(S_t, a)used for the action evaluation (in blue) are determined by the same neural network with the weight vectorθ_t.
DQN 的 Gt 公式:用于动作选择的 Q 值Q(S_t, a)(红色)和用于动作评估的 Q 值Q(S_t, a)(蓝色)由具有权重向量的同一神经网络确定θ_t。 - Gt formula for Double DQN: the Q-value used for the action selection and the Q-value used for the action evaluation are determined by two different neural networks with weight vectors
θ_tandθ'_t.These networks are called current and target.
Double DQN 的 Gt 公式:用于动作选择的 Q 值和用于动作评估的 Q 值由两个不同的神经网络确定,权重向量为θ_t和θ'_t。这些网络称为“电流”和“目标”。
However, due to the slowly changing policy, estimates of the value of the current and target neural networks are still too similar, and this still causes a consistent overestimation.
然而,由于政策的缓慢变化,对当前神经网络和目标神经网络值的估计仍然过于相似,这仍然导致了持续的高估。
Actor-Critic architecture in DDPG.
DDPG 中的 Actor-Critic 架构。
DDPG is one of the first algorithms that tried to use the Q-learning technique of DQN models for continuous action spaces. DDPG stands for Deep Deterministic Policy Gradient. In this case, we cannot use the maximization operator of Q-values over all actions, however, we can use the function approximator, a neural network representing Q-values. We presume that there exists a certain function Q(s, a) which is differentiable with respect to the action argument a.However, finding argmax(Q(S_t, a)) on all actions a for the given state S_t means that we must solve the optimization task at every time step. This is a very expensive task. To overcome this obstacle, a group of researchers from DeepMind in the work “Continuous control with deep reinforcement learning” used the Actor-Critic architecture. They used two neural networks: one, as before, in DQN: Q-network representing Q-values; another one is the actor function 𝜋(s) which provides a*, the maximum for the value function Q(s, a) as follows:
DDPG 是最早尝试将 DQN 模型的 Q 学习技术用于连续动作空间的算法之一。DDPG 代表 深度确定性策略梯度。在这种情况下,我们不能在所有动作上使用 Q 值的最大化运算符,但是,我们可以使用函数近似器,一个表示 Q 值的神经网络。我们假设存在一个特定的函数 Q(s, a),该函数相对于动作参数 a 是可微分的。然而,在给定状态的所有动作 a 上找到 argmax(Q(S_t, a))S_t意味着我们必须在每个时间步骤中解决优化任务。 这是一项非常昂贵的任务。为了克服这个障碍,DeepMind 的一组研究人员在“Continuous control with deep reinforcement learning”一文中使用了 Actor-Critic 架构。他们使用了两个神经网络:一个和以前一样,在DQN中:Q网络代表Q值;另一个是 Actor 函数 π(s),它提供 a*,即值函数 Q(s, a) 的最大值,如下所示:
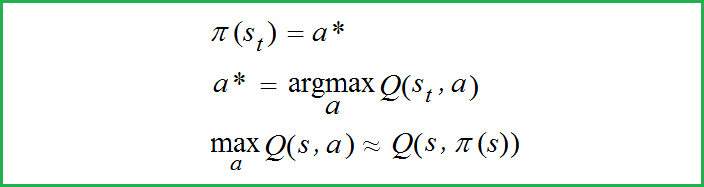
Actor function 𝜋(s)
Actor 函数 π
Part 2. Exploration as a major challenge of learning
第 2 部分。探索是学习的一大挑战
Why explore? 为什么要探索?
In addition to overestimation, there is another problem in Deep RL, no less difficult. This is exploration. We cannot unconditionally believe in maximum values of the Q-table or in the value of a* = 𝜋(s). Why not? Firstly, at the beginning of training, the corresponding neural network is still “young and stupid”, and its maximum values are far from reality. Secondly, perhaps not the maximum values will lead us to the optimal strategy after hard training.
除了高估之外,Deep RL还存在另一个问题,同样困难。这就是探索。我们不能无条件地相信 Q 表的最大值或 a* = π(s) 的值。为什么不呢?首先,在训练之初,对应的神经网络还是“年轻而愚蠢”的,其最大值与现实相去甚远。其次,也许不是最大值会在艰苦训练后引导我们找到最优策略。
In life, we often have to solve the following problem: to follow the beaten path — there is little risk and little reward; or to take a new unknown path with great risk — but, with some probability, a big win is possible there. Maybe it will be just super, you don’t know.
在生活中,我们常常要解决以下问题:走人迹罕至的路——风险小,回报少;或者冒着巨大的风险走上一条新的未知道路——但是,有一定的可能性,在那里可能会取得巨大的胜利。也许它会超级棒,你不知道。
Exploration vs. exploitation
探索与开采
Exploitation means, that the agent uses the accumulated knowledge to select the following action. In our case, this means that for the given state, the agent finds the following action that maximizes the Q-value. The exploration means that the following action will be selected randomly.
利用意味着,代理使用积累的知识来选择以下操作。在我们的例子中,这意味着对于给定的状态,代理会找到以下最大化 Q 值的操作。探索意味着将随机选择以下操作。
There is no rule that determines which strategy is better: exploration or exploitation. The real goal is to find a true balance between these two strategies. As we can see, the balance strategy changes in the learning process.
没有规则可以确定哪种策略更好:探索还是开发。真正的目标是在这两种策略之间找到真正的平衡。正如我们所看到的,平衡策略在学习过程中会发生变化。
Exploration in DQN and Double DQN
DQN和双重DQN的探索
One way to ensure adequate exploration in DQN and Double DQN is to use the annealingε-greedy mechanism. For the first episodes, exploitation is selected with a small probability, for example, 0.02 (i.e., the action will be chosen very randomly) and the exploration is selected with a probability 0.98. Starting from a certain number of episode Mε, the exploration will be performed with a minimal probability ε_m, for example, ε_m= 0.01, and the exploitation is chosen with probability 0.99. The probability formula of exploration ε can be realized as follows:
确保在 DQN 和双重 DQN 中进行充分探索的一种方法是使用退火ε贪婪机制。对于第一集,选择剥削的概率很小,例如,0.02(即,行动将非常随机地选择),而探索的选择概率为 0.98。从一定数量的集数 Mε 开始,将以最小概率进行探索,例如ε_m ε_m= 0.01,选择开发的可能性为 0.99。 探索ε的概率公式可以按如下方式实现:
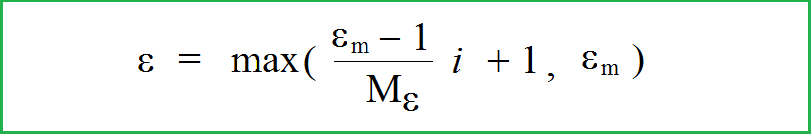
Annealing ε-greedy mechanism, probability formula of exploration ε
退火ε贪婪机理、勘探ε概率公式
where i is the episode number. Let Mε = 100, ε_m = 0.01. Then the probability ε of exploration looks as follows:
其中 i 是剧集编号。设 Mε = 100,ε_m = 0.01。 然后,探索的概率ε如下所示:

Gradual decrease in probability from 1 to ε_m = 0.01
概率从 1 逐渐减少到 ε_m = 0.01
Exploration in DDPG
DDPG的探索
In RL models with continuous action spaces, instead of ε-greedy mechanism undirected exploration is applied. This method is used in DDPG , PPO and other continuous control algorithms. Authors of DDPG (Lillicrap et al., 2015) constructed undirected exploration policy 𝜋’ by adding noise sampled from a noise process N to the actor policy 𝜋(s):
在具有连续动作空间的 RL 模型中,应用了无向探索,而不是ε贪婪机制。这种方法用于DDPG、PPO等连续控制算法。DDPG 的作者 (Lillicrap et al., 2015) 通过将从噪声过程 N 采样的噪声添加到参与者策略π(s)中来构建无定向勘探策略 π':
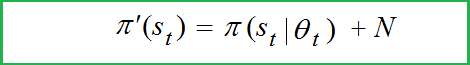
Policy 𝜋(s) with exploration noise有勘探噪音的政策 π
where N is the noise given by Ornstein-Uhlenbeck, correlated noise process. In the TD3 paper authors (Fujimoto et. al., 2018) proposed to use the classic Gaussian noise, this is the quote:
其中 N 是 Ornstein-Uhlenbeck 给出的噪声,即相关噪声过程。在TD3论文中,作者(Fujimoto et al., 2018)提出使用经典的高斯噪声,是这样引用的:
…we use an off-policy exploration strategy, adding Gaussian noise N(0; 0:1) to each action. Unlike the original implementation of DDPG, we used uncorrelated noise for exploration as we found noise drawn from the Ornstein-Uhlenbeck (Uhlenbeck & Ornstein, 1930) process offered no performance benefits.
…我们使用非策略探索策略,将高斯噪声N(0; 0:1)添加到每个动作中。与DDPG的原始实现不同,我们使用不相关的噪声进行探索,因为我们发现从Ornstein-Uhlenbeck(Uhlenbeck&Ornstein,1930)过程中提取的噪声没有提供任何性能优势。
A common failure mode for DDPG is that the learned Q-function begins to overestimate Q-values, then the policy (actor function) leads to significant errors.
DDPG 的常见故障模式是学习的 Q 函数开始高估 Q 值,然后策略(actor 函数)导致重大错误。
Exploration in TD3
TD3的勘探
The name TD3 stands for Twin Delayed Deep Deterministic. TD3 retains the Actor-Critic architecture used in DDPG, and adds 3 new properties that greatly help to overcome overestimation:
TD3 这个名字代表 Twin Delayed Deep Deterministic。TD3 保留了 DDPG 中使用的 Actor-Critic 架构,并添加了 3 个新属性,这些属性极大地帮助克服了高估:
- TD3 maintains a pair of critics Q1 amd Q2 (hence the name “twin”) along with a single actor. For each time step, TD3 uses the smaller of the two Q-values.
TD3 拥有一对评论家 Q1 和 Q2(因此得名“双胞胎”)以及一位演员。对于每个时间步长,TD3 使用两个 Q 值中较小的一个。 - TD3 updates the policy (and target networks) less frequently than the Q-function updates (one policy update (actor) for every two Q-function (critic) updates)
TD3 更新策略(和目标网络)的频率低于 Q-Function 更新的频率(每两次 Q-Function(批评)更新一次策略更新(参与者)) - TD3 adds exploration noise to the target action. TD3 uses Gaussian noise, not Ornstein-Uhlenbeck noise as in DDPG.
TD3 将勘探噪声添加到目标动作中。 TD3 使用高斯噪声,而不是 DDPG 中的 Ornstein-Uhlenbeck 噪声。
Exploration noise in trials with PyBullet Hopper
使用 PyBullet Hopper 进行试验中的探索噪声
PyBullet is a Python module for robotics and Deep RL based on the Bullet Physics SDK. Let us look at HopperBulletEnv, one of PyBullet environments associated with articulated bodies:
PyBullet 是一个用于机器人和 Deep RL 的 Python 模块,基于 Bullet Physics SDK。 让我们看一下 HopperBulletEnv,它是与关节体相关的 PyBullet 环境之一:

Trained agent for HopperBulletEnv训练有素的 HopperBulletEnv 代理
The HopperBulletEnv environment is considered solved if the achieved score exceeds 2500. In TD3 trials with the HopperBulletEnv environment, I got, among others, the following results for std = 0.1 and std = 0.3:
如果获得的分数超过 2500,则认为 HopperBulletEnv 环境已解决。在使用 HopperBulletEnv 环境的 TD3 试验中,我得到了 std = 0.1 和 std = 0.3 的以下结果:
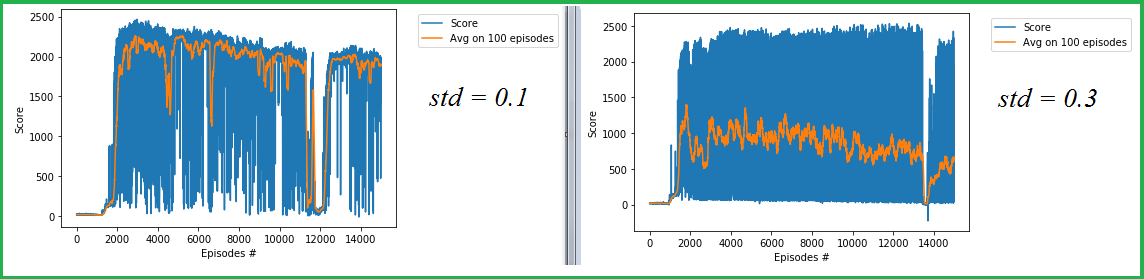
Two trials for HopperBulletEnv with TD3, std of noise= 0.1 and 0.3
使用 TD3 的 HopperBulletEnv 的两项试验,噪声标准 = 0.1 和 0.3
Here, std is the standard deviation of exploration noise in TD3. In both trials, threshold 2500 was not reached. However, I noticed the following oddities.
其中,std 是 TD3 中勘探噪声的标准偏差。在两项试验中,均未达到阈值2500。但是,我注意到以下奇怪之处。
- In trial
std = 0.3, there are a lot of values near 2500 (however less than 2500) and at the same time, the average value decreases all the time. This is explained as follows: the number of small values prevails over the number of large values, and the difference between these numbers increases.
在试验std = 0.3中,在 2500 附近有很多值(但小于 2500),同时,平均值一直在减少。对此解释如下:小值的数量优先于大值的数量,并且这些数字之间的差异会增加。 - In trial
std = 0.1, the average values reach large values but in general, the values decrease. The reason of this, again, is that the number of small values prevails over the number of large values.
在试验std = 0.1中,平均值达到较大值,但一般来说,值会降低。同样,其原因是小值的数量优先于大值的数量。 - It seemed to me that the prevalence of very small values is associated with too big noise standard deviation. Then I decide to reduce
stdto0.02, it was enough to solve the environment.
在我看来,非常小的值的普遍性与过大的噪声标准差有关。然后我决定将std降低到0.02,这足以解决环境问题。
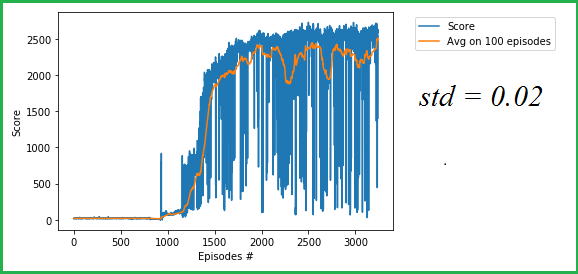
HopperBulletEnv with TD3, std of noise = 0.02使用 TD3 的 HopperBulletEnv,噪声标准 = 0.02
App. Hill-Climbing algorithm with adaptive noise
具有自适应噪声的爬山算法
Forerunner of tensors 张量的先驱
We illustrate the properties of the Hill-Climbing algorithm applied to the Cartpole environment. The neural network model here is so simple that does not use tensors (no PyTorch, no Tensorflow), the neural network uses only the simplest matrix of shape [4 x 2], that is the forerunner of tensors.
我们展示了应用于 Cartpole 环境的 Hill-Climbing 算法的属性。这里的神经网络模型非常简单,不使用张量(没有 PyTorch,没有 Tensorflow),神经网络只使用最简单的形状矩阵 [4 x 2],即张量的先驱。
Class Policy in Hill-Climbing algorithm
Hill-Climbing算法中的班级策略
The Hill-Climbing algorithm seeks to maximize a target function Go, which in our particular case is the cumulative discounted reward:
Hill-Climbing 算法旨在最大化目标函数 Go,在我们的特定情况下,它是累积折扣奖励:

Cumulative discounted reward
累计折扣奖励
where γ is the discount factor, 0 < γ < 1, and Rk is the reward obtained at the time step k of the episode. The target function Go looks in Python as follows:
其中 γ 是折扣因子,0 < γ < 1,Rk 是在剧集的时间步长 k 获得的奖励。目标函数 Go 在 Python 中如下所示:
<span style="background-color:#f2f2f2"><span style="color:#242424"><strong>discounts </strong><strong>= [gamma**i for i in range(len(rewards)+1)]
Go = sum([a*b for a,b in zip(discounts, rewards)])</strong></span></span>As always in Deep RL, we try to exceed a certain threshold. For Cartpole-v0, this threshold score is 195, and for Cartpole-v1 it is 475. Hill-Climbing is a simple gradient-free algorithm (i.e., we do not use the gradient ascent/gradient descent methods). We try to climb to the top of the curve by only changing the arguments of the target function Go using a certain adaptive noise. However, what is the argument of our target function?
像往常一样,在Deep RL中,我们试图超过某个阈值。对于 Cartpole-v0,此阈值分数为 195,对于 Cartpole-v1,此阈值分数为 475。Hill-Climbing是一种简单的无梯度算法(即,我们不使用梯度上升/梯度下降方法)。我们试图通过仅使用一定的自适应噪声更改目标函数 Go 的参数来爬升到曲线的顶部。但是,我们的目标函数的论点是什么?
The argument of Go is the weight matrix determining the neural network that underlies in our model. The weight matrix example for episodes 0–5 are presented here:Go 的论点是权重矩阵,它决定了我们模型中的基础神经网络。此处显示了第 0-5 集的权重矩阵示例:

Weight vectors [4 x 2] of the neural network for episodes 0–5
第 0-5 集神经网络的权重向量 [4 x 2]
Adaptive noise scale 自适应噪声标度
The adaptive noise scaling for our model is realized as follows. If the current value of the target function is better than the best value obtained for the target function, we divide the noise scale by 2, and this noise is added to the weight matrix. If the current value of the target function is worse than the best obtained value, we multiply the noise scale by 2, and this noise is added to the best obtained value of the weight matrix. In both cases, a noise scale is added with some random factor different for any element of the matrix.
我们模型的自适应噪声缩放实现如下。如果目标函数的当前值优于目标函数获得的最佳值,我们将噪声标度除以 2,并将该噪声添加到权重矩阵中。如果目标函数的当前值差于获得的最佳值,我们将噪声刻度乘以 2,并将该噪声添加到权重矩阵的最佳获得值中。在这两种情况下,都会添加一个噪声标度,其中包含一些随机因子,适用于矩阵的任何元素。
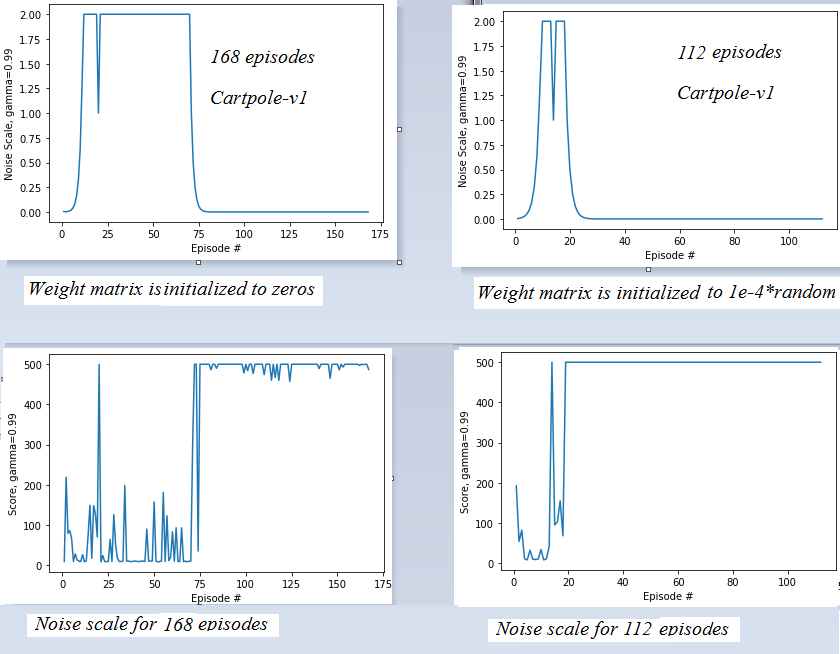
Noise Scale and Score graphs by episodes
按情节划分的噪声量表和评分图
For Cartpole-v1, if the weight matrix is initialized to non-zero small values (see above the left top matrix), the number of episodes = 112. Note that if the weight matrix is initialized to zeros then the number of episodes is increased from 112 to 168. The same for Cartpole-v0.
对于 Cartpole-v1,如果权重矩阵初始化为非零小值(请参阅左上角矩阵上方),则集数 = 112。请注意,如果权重矩阵初始化为零,则集数将从 112 增加到 168。Cartpole-v0 也是如此。
For more information on Cartpole-v0/Cartpole-v1 with adaptive noise scaling, see the project on Github.
有关具有自适应噪声缩放功能的 Cartpole-v0/Cartpole-v1 的更多信息,请参阅 Github 上的项目。
A more generic formula for the noise scale
噪声标度的更通用公式
As we saw above, the noise scale adaptively increases or decreases depending on whether the target function is lower or higher than the best obtained value. The noise scale in this algorithm is 2. In the paper “Parameter Space Noise for Exploration” authors considers more generic formula:
正如我们上面所看到的,噪声标度会根据目标函数是小于还是高于获得的最佳值而自适应地增加或减少。该算法中的噪声刻度为 2。在论文“Parameter Space Noise for Exploration”中,作者考虑了更通用的公式:
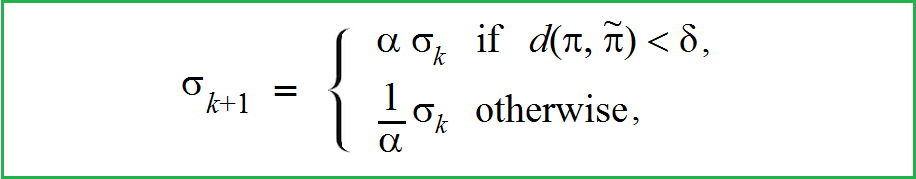
Adaptive noise scale 自适应噪声标度
where α is a noise scale, d is a certain distance measure between perturbed and non-perturbed policy, and δ is a threshold value. In Appendix C, authors consider the possible forms of the distance function d for algorithms DQN, DDPG and TPRO.
其中 α 是噪声标度,D 是受扰动策略和非受扰动策略之间的一定距离度量,δ 是阈值。在附录 C 中,作者考虑了算法 DQN、DDPG 和 TPRO 的距离函数 d 的可能形式。
References 引用
[1] S.Thrun and A.Schwartz, Issues in Using Function Approximation for Reinforcement Learning, (1993), Carnegie Mellon University, The Robotics Institute
[1] S.Thrun 和 A.Schwartz,使用函数近似进行强化学习的问题,(1993 年),卡内基梅隆大学,机器人研究所
[2] H.van Hasselt et. al., Deep Reinforcement Learning with Double Q-learning (2015), arXiv:1509.06461
[2] H.van Hasselt 等人。等,Deep Reinforcement Learning with Double Q-learning (2015),arXiv:1509.06461
[3] T.P. Lillicrap et.al., Continuous control with deep reinforcement learning (2015), arXiv:1509.02971
[3] T.P. Lillicrap et.al.,深度强化学习的持续控制 (2015),arXiv:1509.02971
[4] Yuxi Li, Deep Reinforcement Learning: An Overview (2018), arXiv:1701.07274v6
[4] Yuxi Li, 深度强化学习: An Overview (2018), arXiv:1701.07274v6
[5] S.Fujimoto et.al, Addressing Function Approximation Error in Actor-Critic Methods (2018), arXiv: arXiv:1802.09477v3
[5] S.Fujimoto et.al,Addressing Function Approximation Error in Actor-Critic Methods(2018),arXiv:arXiv:1802.09477v3
[6] Better Exploration with Parameter Noise, OpenAI.com, https://openai.com/blog/better-exploration-with-parameter-noise/
[6] 利用参数噪声更好地探索, OpenAI.com, https://openai.com/blog/better-exploration-with-parameter-noise/
[7] M.Plappert et.al. , Parameter Space Noise for Exploration, OpenAI, arXiv:1706.01905v2, ICLR 2018
[7] M.Plappert et.al., 用于探索的参数空间噪声, OpenAI, arXiv:1706.01905v2, ICLR 2018
[8] B.Mahyavanshi, Introduction to Hill Climbing | Artificial Intelligence, Medium, 2019
[8] B.Mahyavanshi,登山导论 |人工智能, 中, 2019
[9] Deep Deterministic Policy Gradient, OpenAI, Spinning Up, Deep Deterministic Policy Gradient — Spinning Up documentation
[9] 深度确定性政策梯度,OpenAI,Spinning Up,https://spinningup.openai.com/en/latest/algorithms/ddpg.html
[10] What Does Stochastic Mean in Machine Learning? (2019), Machine Learning Mastery,
[10] 随机振荡在机器学习中是什么意思?(2019),机器学习掌握,
https://machinelearningmastery.com/stochastic-in-machine-learning/
[11] C. Colas et. al., GEP-PG: Decoupling Exploration and Exploitation in Deep Reinforcement Learning Algorithm (2018), arXiv:1802.05054
[11] C.科拉斯等人。等, GEP-PG: Decoupling Exploration and Exploitation in Deep Reinforcement Learning Algorithm (2018), arXiv:1802.05054
[12]https://en.wikipedia.org/wiki/Ornstein–Uhlenbeck_process, Ornstein–Uhlenbeck process
[12]https://en.wikipedia.org/wiki/Ornstein-Uhlenbeck_process, Ornstein-Uhlenbeck 过程
[13] E.Lindwurm, Intuition: Exploration vs Exploitation (2019), TowardsDataScience
[13] E.Lindwurm,直觉:探索与开发(2019),TowardsDataScience
[14] M.Watts, Introduction to Reinforcement Learning (DDPG and TD3) for News Recommendation (2019), TowardsDataScience
[14] M.Watts,强化学习(DDPG 和 TD3)简介,用于新闻推荐 (2019),TowardsDataScience
[15] T.Stafford, Fundamentals of learning: the exploration-exploitation trade-off (2012), https://tomstafford.staff.shef.ac.uk/?p=48
[15] T.Stafford,《学习基础:探索-开发权衡》(2012),https://tomstafford.staff.shef.ac.uk/?p=48
[16] Bullet Real-Time Physics Simulation (2020), Bullet Real-Time Physics Simulation | Home of Bullet and PyBullet: physics simulation for games, visual effects, robotics and reinforcement learning.
[16] 子弹实时物理仿真 (2020), Bullet Real-Time Physics Simulation | Home of Bullet and PyBullet: physics simulation for games, visual effects, robotics and reinforcement learning.
[17] R.Stekolshchik, A pair of interrelated neural networks in DQN (2020), TowardsDataScience
[17] R.Stekolshchik,DQN 中的一对相互关联的神经网络 (2020),TowardsDataScience
[18] R.Stekolshchik, How does the Bellman equation work in Deep RL? (2020), TowardsDataScience
[18] R.Stekolshchik,贝尔曼方程在深度强化学习中是如何工作的?(2020), TowardsDataScience

















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











