






ubuntu安装和配置hadoop,java环境及项目运行
参考博主
Ubuntu 20.0.4 Hadoop3.3.2 安装与配置全流程保姆教程_hadoop unbuntu 保姆_NEKO!的博客-CSDN博客
- 安装包准备
- JDK安装包:镜像下载链接(for linux x64 Compressed Archive):Index of java-local/jdk
- hadoop安装包:下载链接:Hadoop 压缩包(Binary download) Apache Hadoop
- Ubuntu安装包,下载链接:ubuntu 虚拟机 https://ubuntu.com/download/desktop
- 安装JDK和配置(JDK-11)
- 找到下载的JDK的路径并进入此路径:/usr/lib/jvm/java-11-openjdk-amd64
- 在此路径下解压:tar -zxvf jdk-11_linux-x64_bin.tar.gz(自己下载的JDK包的名字)
- 配置环境变量:找到并打开文件.barsh:在最后一行添加JDK路径
#jdk
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
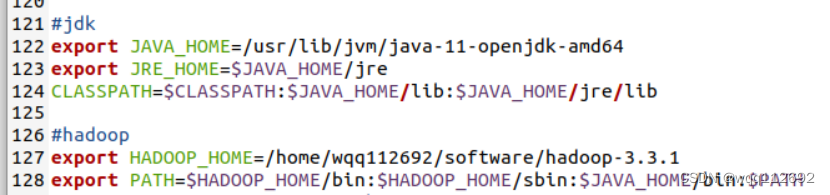
3安装hadoop和配置(hadoop 3.3.1)
3.1找到自己下载的hadoop压缩包并解压,放入自己的另外一个文件夹(我自己建了一个/home/wqq112692/software)路径存放JDK和hadoop :
#hadoop
export HADOOP_HOME=/home/wqq112692/software/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH
-
- 配置hadoop的环境变量:找到并打开文件.barsh:在最后一行添加hadoop路径:如下命令
- 在/home/wqq112692/software/hadoop-3.3.1/etc/hadoop找到core-site.xml文件并配置,加入如下内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/wqq112692/software/hadoop-3.3.1/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
-
- 在/home/wqq112692/software/hadoop-3.3.1/etc/hadoop找到hdfs-site.xml文件并配置,加入如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/wqq112692/software/hadoop-3.3.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/wqq112692/software/hadoop-3.3.1/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
-
- 在/home/wqq112692/software/hadoop-3.3.1/etc/hadoop找到mapred-site.xml文件并配置,加入如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/wqq112692/software/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/wqq112692/software/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/wqq112692/software/hadoop-3.3.1</value>
</property>
</configuration>
-
- 在/home/wqq112692/software/hadoop-3.3.1/etc/hadoop找到yarn-site.xml文件并配置,加入如下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ubuntu1</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/home/wqq112692/software/hadoop-3.3.1/etc/hadoop:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/common/lib/*:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/common/*:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/hdfs:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/hdfs/*:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/mapreduce/*:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/yarn:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/yarn/lib/*:/home/wqq112692/software/hadoop-3.3.1/share/hadoop/yarn/*
</value>
</property>
</configuration>
-
- 在/home/wqq112692/software/hadoop-3.3.1/etc/hadoop/hadoop-env.sh找到hadoop-env.sh文件并配置,加入如下内容:

- 启动hadoop
- 打开任意终端,进入 /hadoop/bin 路径 cd /usr/hadoop/bin。执行指令 ./hdfs namenode -format 进行格式化。
- 进入 /hadoop/sbin 路径 cd /usr/hadoop/sbin,执行指令 ./start-all.sh 启动 hadoop。
- 执行指令 jps 查看运行的进程,必须要有6个才是正确的。
- 打开浏览器输入 http://localhost:50070 进入 web 管理页面。
- 打开浏览器输入 http://localhost:8088进入 web 管理页面.
- 利用hadoop实现项目
- start-all.sh启动hadoop。
- 创建HDFS文件:hdfs dfs -mkdir /user/hadoop/test
- 虚拟机文件传到HDFS命令:hdfs dfs -put ~/.bashrc /user/hadoop/test/
- 删除文件夹命令:hdfs dfs -rm -r /user/hadoop/mydir
- 查看文件内容命令:hdfs dfs -cat /user/hadoop/test/file.txt
- 在虚拟机中创建java文件,用javac 项目名称.java运行。调试成功后打包成jar包。Jar -cvfm scores.jar MANIFEST.MF StudentScores
- 在虚拟机存放输入数据的那个路径下(/home/wqq112692/bigdata/work1/input)打开终端。输入命令:
hadoop jar wc.jar WordCountPerFile /user/hadoop/work1/in /user/hadoop/work1/out1
hadoop jar scores.jar StudentScores /user/hadoop/work2/in /user/hadoop/work2/out2
运行wc.jar/scores.jar项目。
scores.jar:虚拟机存放的项目jar包
StudentScores:项目包名.项目类名称
/user/hadoop/work2/in:HDFS中存放输入数据的路径
/user/hadoop/work2/out2:HDFS中存放输出数据的路径,此路径不能存在。
查看运行结果命令:
hdfs dfs -cat /user/hadoop/work1/out1/part-r-00000
hdfs dfs -cat /user/hadoop/work2/out2/part-r-00000
其他命令:(4)hdfs dfs -mkdir (-p) /user/hadoop 创建文件夹
hdfs dfs -ls /user/hadoop 查看文件是否创建
hdfs dfs -put file_1.txt /user/hadoop/Hadoop/WordNum/input(hdfs中创建的保存数据的目录),这一步将虚拟机中的数据文件上传到HDFS保存数据的目录中
参考博主:
你有想过,如何用Hadoop实现【倒排索引】?_hadoop倒排索引jar包运行结果截图-CSDN博客
- 免密登录(自己选择)
设置免密登录免密命令:
参考博主:
https://www.cnblogs.com/hanwen1014/p/9048717.html
终端输入命令:
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub localhost
jps后无法显示namenode和datanod解决办法
参考博主:
https://blog.csdn.net/weixin_51737266/article/details/117523282
https://blog.csdn.net/qq_44176343/article/details/109584039
name-version
clusterID=CID-c9c13e6e-8b34-4dfa-9266-34200203fed0
http://localhost:50070















 3347
3347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









