







 本文探讨了2023年RAG系统中分块技术的改进、数据检索技术的飞跃发展,包括查询增强、层次结构和知识图谱的应用。重点在于如何通过这些技术提高数据相关性和检索效率,以实现更精准的信息处理和回答用户查询。
本文探讨了2023年RAG系统中分块技术的改进、数据检索技术的飞跃发展,包括查询增强、层次结构和知识图谱的应用。重点在于如何通过这些技术提高数据相关性和检索效率,以实现更精准的信息处理和回答用户查询。
本文将重新审视分块技术以及其他方法,包括查询增强、层次结构和知识图谱。
一、简单RAG架构快速概览
在2023年年初,我的主要关注点集中在Vector DB及其在更广泛的设计领域中的表现上。然而,随着2023年的收尾,这一领域出现了重大进展。在RAG系统的设计中,需要考虑以下一些事情:
- LLM模型领域正在进行的开源和开源之间的斗争,那么在实际使用中最好的模型是什么?
- 应该微调LLM还是直接对数据集进行嵌入?
- 文件处理有了新的突破。之前仅依靠文档块,现在拥有一系列技术,包括层次结构、句子窗口、自动合并等。
- 数据检索技术也突飞猛进。今年年初,只使用了k-相似性技术,现在我们有递归、混合搜索、重新排序、元数据过滤器、多智能体等。
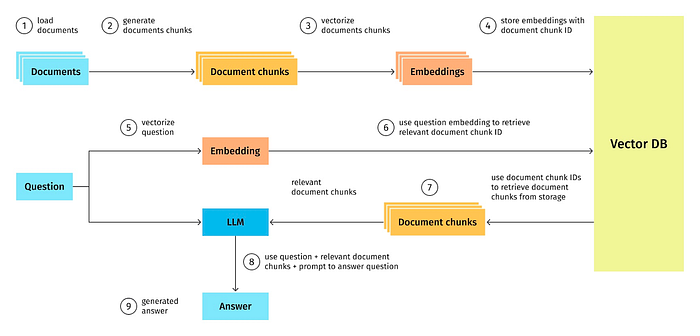
那么,是什么造就了一个好的数据检索系统呢?
两个词:相关性和相似性。
相关性是指检索到的信息与用户的查询相关的相关性或重要性,而相似性在数据检索的上下文中是指用户的查询与可用数据之间的相似性或相似性。
similarity = word matching,relevancy = context matching.
矢量数据库有助于识别语义相近的内容(相似性),但识别相关性或检索相关内容更复杂的方法(可以参考:https://www.youtube.com/watch?v=TRjq7t2Ms5I)。
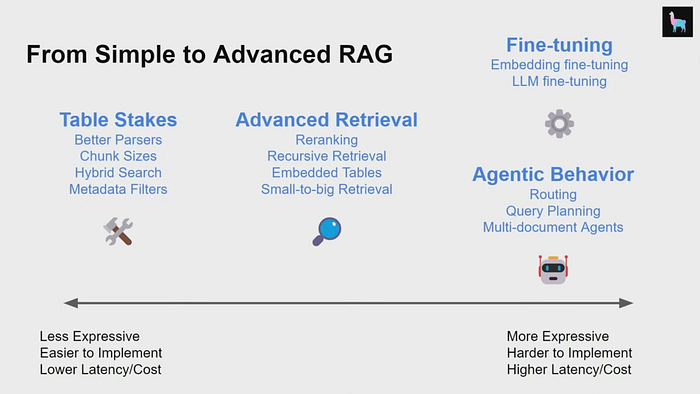
二、高级数据处理实现更好的数据检索
2.1 分块策略
在自然语言处理的背景下,“分块”是将文本分解为可管理、清晰和重要的块的过程。在这种情况下,使用较小的文本片段而不是较大的文档可以使RAG系统更快、更准确地发现相关上下文。
确保选择的分块是合适的,这对分块策略的成功至关重要。这些文本段落的水平和组织对这种策略的效果有很大影响。为了找到和提取捕捉RAG系统所需的基本细节或上下文的文本段落,需要仔细检查内容和上下文。智能分块策略提高了系统遍历和理解自然语言的能力,最终实现了更准确、更有效的信息处理。
在本文中,块大小为1024似乎会产生更好的结果
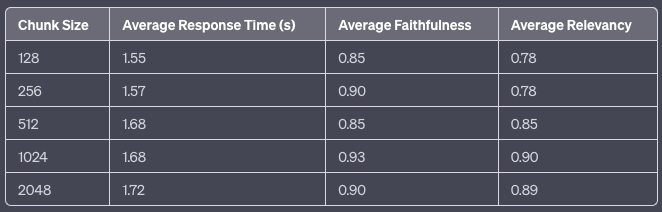
较大的块可以捕获更多的上下文,但由于它们产生的噪声,处理它们需要更长的时间和更多的钱。虽然较小的片段可能无法完全传达必要的上下文,但它们的噪音确实较小。平衡这两个要求的一种方法是具有重叠部分。组合块的查询可能能够从各种向量中获得足够的相关信息,以产生适当的上下文化答案。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6093
6093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











