







 本文介绍如何通过后退提示技术(如StepBackPrompting)以及多查询和交叉编码重排序策略来优化RAG在矢量数据库中的检索性能,特别关注在信息不完整时提升文档的相关性和准确性。
本文介绍如何通过后退提示技术(如StepBackPrompting)以及多查询和交叉编码重排序策略来优化RAG在矢量数据库中的检索性能,特别关注在信息不完整时提升文档的相关性和准确性。
RAG有时无法从矢量数据库中检索到正确的文档。比如我们问如下问题:
从1980年到1990年,国际象棋的规则是什么?
RAG在矢量数据库中进行相似性搜索,来查询与国际象棋规则问题相关的相关文档。然而,在某些情况下,我们的向量数据库没有存储完整的信息,例如,我们的矢量数据库没有存储不同年份的规则。这样,数据库可以返回与国际象棋规则相关但与特定问题不直接相关的文档。
针对上述情况,我们可以采用查询扩展技术,该技术可以对用户的原始查询生成更全面、信息更丰富的搜索。这个新生成的查询将从矢量数据库中获取更多相关文档。
本文,我们将介绍三种查询扩展方法:
一、后退提示(Step Back Prompting)
Step back prompting来自论文《Take A Step Back: Evoking Reasoning Via Abstraction In Large Language Models》[1]
Step back prompting是谷歌deepmind开发的一种方法,它首先使用LLM创建用户查询的抽象(从用户具体查询到通用查询的转换,因此称为后退提示),然后根据生成的通用查询来生成答案。
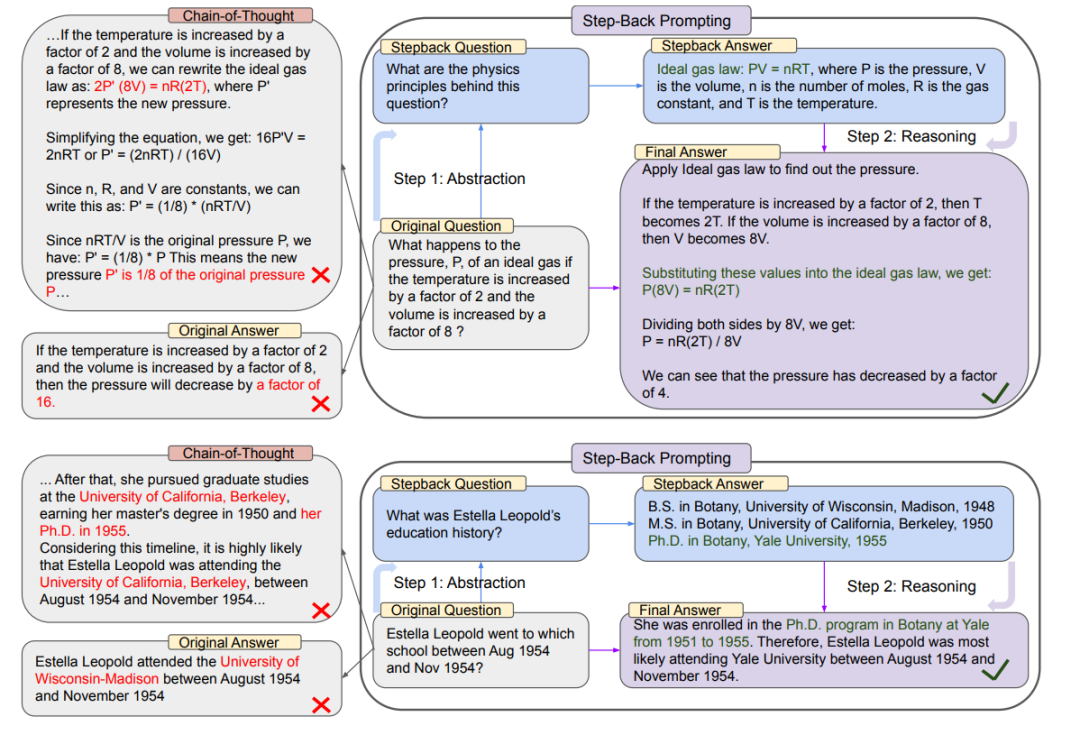
以下是“原始查询”和“后退查询”的示例:
{"Original_Query": "Could the members of The Police perform lawful arrests?","Step_Back_Query": "what can the members of The Police do?",},{"Original_Query": "Jan Sindel’s was born in what country?","Step_Back_Query": "what is Jan Sindel’s personal history?",}
#---------------------Prepare VectorDB-----------------------------------# Build a sample vectorDBfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_community.vectorstores import Chromafrom langchain.embeddings import OpenAIEmbeddingsimport osos.environ["OPENAI_API_KEY"] = "Your OpenAI KEY"# Load blog postloader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")data = loader.load()# Splittext_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)splits = text_splitter.split_documents(data)# VectorDBembedding = OpenAIEmbeddings()vectordb = Chroma.from_documents(documents=splits, embedding=embedding)#-------------------Prepare Step Back Prompt Pipeline------------------------from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplatefrom langchain_core.runnables import RunnableLambdafrom langchain.chat_models import ChatOpenAIretriever = vectordb.as_retriever()llm = ChatOpenAI()# Few Shot Examplesexamp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











