







一、概述
开篇明义,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。关于dropout详情请查看
在机器学习中和深度学习中可能会存在过拟合的问题,表现为在训练集上表现很好,但在测试集中表现不如训练集中的那么好。这主要是由于过拟合的问题,深度学习中dropout是Alaxnet最先引入的。关于其网络详情你可以查看。
Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。但在测试及验证中:每个神经元都要参加运算,但其输出要乘以概率p。示意图如下:

二、tf.nn.dropout()
dropout(x, keep_prob, noise_shape=None, seed=None, name=None)
-
参数:
-
x:你自己的训练、测试数据等
keep_prob:dropout概率
示例:
import tensorflow as tf
dropout = tf.placeholder(tf.float32) # 占位
x = tf.Variable(tf.ones([5, 5])) # 定义变量
y = tf.nn.dropout(x, dropout) # 定义dropout
init = tf.global_variables_initializer() # 初始化变量
with tf.Session() as sess:
sess.run(init)
print("keep_prob=1.0:\n",sess.run(y, feed_dict={dropout: 1})) # 先不进行dropout看输出的是啥
print("keep_prob=0.8:\n",sess.run(y, feed_dict={dropout: 0.8})) # 进行dropout看输出的是啥
输出:
keep_prob=1.0:
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
keep_prob=0.8:
[[1.25 1.25 1.25 1.25 1.25]
[1.25 1.25 1.25 0. 0. ]
[1.25 1.25 1.25 1.25 1.25]
[1.25 0. 1.25 1.25 1.25]
[1.25 1.25 1.25 1.25 1.25]]
三、小案例:dropout效果可视化
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.set_random_seed(1)
np.random.seed(1)
n_sample = 20
n_hidden = 300
lr = 0.01
x = np.linspace(-1, 1, n_sample)[:, np.newaxis]
y = x + 0.2 * np.random.randn(n_sample)[:, np.newaxis]
test_x = x.copy()
test_y = test_x + 0.2 * np.random.randn(n_sample)[:, np.newaxis]
# plt.scatter(x,y,c='magenta',s=50,alpha=0.5,label='train')
plt.scatter(test_x, test_y, c='cyan', s=50, alpha=0.5, label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.show()
tf_x = tf.placeholder(tf.float32, [None, 1])
tf_y = tf.placeholder(tf.float32, [None, 1])
tf_is_training = tf.placeholder(tf.bool, None)
# overfitting net
o1 = tf.layers.dense(tf_x, n_hidden, tf.nn.relu)
o2 = tf.layers.dense(o1, n_hidden, tf.nn.relu)
o_out = tf.layers.dense(o2, 1)
o_loss = tf.losses.mean_squared_error(tf_y, o_out)
o_train = tf.train.AdamOptimizer(lr).minimize(o_loss)
# dropout net
d1 = tf.layers.dense(tf_x, n_hidden, tf.nn.relu)
d1 = tf.layers.dropout(d1, rate=0.5, training=tf_is_training)
d2 = tf.layers.dense(d1, n_hidden, tf.nn.relu)
d2 = tf.layers.dropout(d2, rate=0.5, training=tf_is_training)
d_out = tf.layers.dense(d2, 1)
d_loss = tf.losses.mean_squared_error(tf_y, d_out)
d_train = tf.train.AdamOptimizer(lr).minimize(d_loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
plt.ion()
for t in range(500):
sess.run([o_train, d_train], feed_dict={tf_x: x, tf_y: y, tf_is_training: True})
if t % 10 == 0:
plt.cla()
[o_loss_, d_loss_, o_out_, d_out_] = sess.run([o_loss, d_loss, o_out, d_out],
feed_dict={tf_x: test_x, tf_y: test_y, tf_is_training: False})
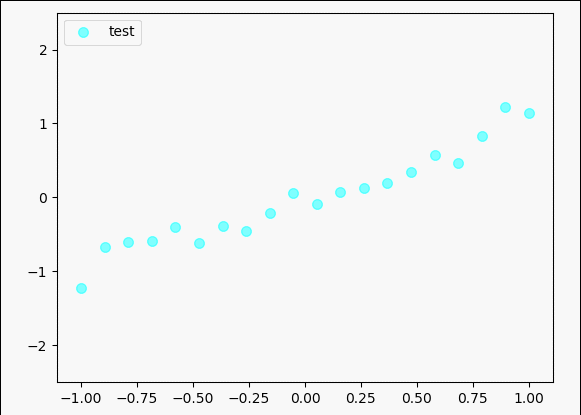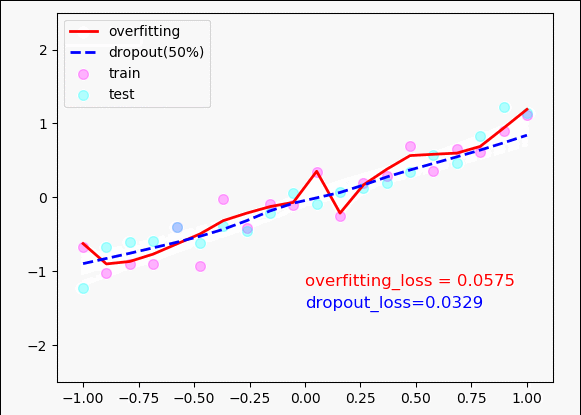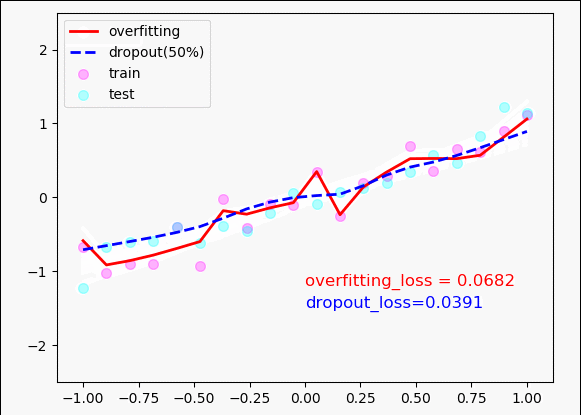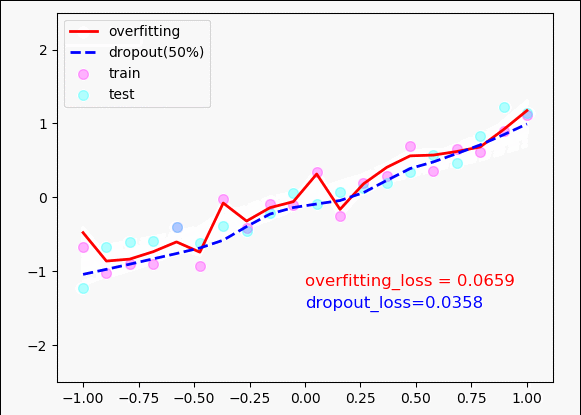
plt.scatter(x, y, c='magenta', s=50, alpha=0.3, label='train')
plt.scatter(test_x, test_y, c='cyan', s=50, alpha=0.3, label='test')
plt.plot(test_x, o_out_, 'r-', lw=2, label='overfitting')
plt.plot(test_x, d_out_, 'b--', lw=2, label='dropout(50%)')
plt.text(0, -1.2, 'overfitting_loss = %.4f' % o_loss_, fontdict={'size': 12, 'color': 'red'})
plt.text(0, -1.5, 'dropout_loss=%.4f' % d_loss_, fontdict={'size': 12, 'color': 'blue'})
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.pause(0.1)
plt.ioff()
plt.show()















 1128
1128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











