







注意:本文所表示的json格式并非coco数据集格式,而是自动驾驶数据集BDD100K的标注。
请先确认再看全文!!!!!
一、修改数据集读取位置
5~9行

二、修改类别
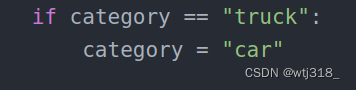
33~34行,若有标注类别名称想改变,可修改类别名称,不用可注释掉。
三、运行程序
python xml_bddjson.py全部可运行代码如下:
import os
import json
import xml.etree.ElementTree as ET
Root = "/home/wtj/Data/red_mount/6979_detect_annotation/val/" # 数据集读取位置
xml_dir = Root + "labels/" # xml标注位置
img_dir = Root + "images/" # 图片读取位置
annotation_dir = Root + "det_annotaions/" # json 输出位置
def mkdir(path):
if not os.path.exists(path):
os.mkdir(path)
def write_json(xml_path, anno_path):
objects = []
tree = ET.parse(xml_path)
root = tree.getroot()
if root.tag != "annotation":
raise Exception("xml should be like voc ...")
file_name = root.findtext("filename")[:-4]
# attributes (交通灯时修改,其他默认)
attributes = dict()
attributes["occluded"] = True
attributes["truncated"] = False
attributes["trafficLightColor"] = "none"
objs = root.findall("object")
id = 0
for obj in objs:
category = obj[0].text
if category == "truck":
category = "car"
bbox_j = dict()
box = [int(obj[4][i].text) for i in range(4)]
bbox_j["x1"] = box[0]
bbox_j["y1"] = box[1]
bbox_j["x2"] = box[2]
bbox_j["y2"] = box[3]
# print(box)
obj_j = dict()
obj_j["category"] = category
obj_j["id"] = id
obj_j["attributes"] = attributes
obj_j["box2d"] = bbox_j
objects.append(obj_j)
id = id + 1
# print(id)
objects_j = objects
label_json = {
"name": file_name,
"frames": [{
"timestamp": 1000,
"objects": objects_j
}],
"attributes":{
"weather": "undefined",
"scene": "city street",
"timeofday": "daytime"
}
}
json_path = os.path.join(anno_path, file_name+ ".json" )
with open(json_path,"w") as file:
file.write(json.dumps(label_json,indent=4))
def main():
mkdir(annotation_dir)
img_list = os.listdir(img_dir)
for img_name in img_list:
name = img_name[0:-4]
xml_path = os.path.join(xml_dir, name+".xml")
print("reading {} ...".format(xml_path))
write_json(xml_path, annotation_dir)
if __name__ == "__main__":
main()
最后请看,知识就是力量,请放心使用~~~
















 6699
6699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









