







ResGen 模型是浙江大学药学院侯廷军老师课题组2023年发表在nature machine intelligence期刊上文章Nature Machine Intelligence | Volume 5 | September 2023 | 1020–1030,题目为:《ResGen is a pocket-aware 3D molecular generation model based on parallel multiscale modelling》。
合作单位是碳硅智能,第一作者是HaotianZhang。

一、文章简介
ResGen是基于蛋白口袋为条件的三维分子生成的E3等变自回归模型。
ResGen建立在并行多尺度建模的原理之上,可以捕获更高层次的口袋分子交互并实现更高的计算效率(比之前最好的模型快大约八倍)。
为了更好地考虑蛋白质口袋的几何形状,生成过程被表述为两个分层自回归:全局自回归和原子自回归。
全局自回归在口袋里生成原子,原子自回归是依次产生新添加的原子的坐标和拓扑。
与其他分子生成模型相同,ResGen模型同样遵循E3等变特性。模型结构如下图:
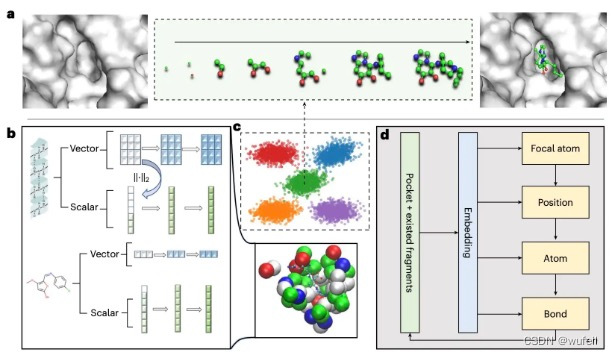
上图a 在分子生成的过程中,逐步地确认生长点,添加原子(全局自回归),确认原子的位置,然后添加边(原子自回归)。
在图b中,口袋和参考分子被表示成原子特征(vector)和原子坐标(scalar)。
残基原子并行多尺度建模,大球体代表不同的残基,而口袋内的小球体代表原子。
分子生成过程如下图。图中灰色点云,例如 i 中的灰色点云,代表新生成的原子,仅具有位置信息。
彩色点云,例如ii中的绿色点云,是新生成的原子,并补充了原子类型。
红色圆圈表示每一步的焦点原子(focal atom, 生长点),而数字是每个原子成为生长点的概率。
正是因为ResGen模型的分子中的后面的原子是基于前面生成原子来生成的,所以ResGen模型是自回归模型。

作者的结果表明,ResGen 在生成新型分子方面,比现有最先进的方法具有更高的成功率,这些分子可以比原始配体更紧密地与靶点结合。
此外,在从头药物设计的现实场景中回顾性计算实验表明,ResGen 成功地生成了更低的结合能和更高的多样性的药物样分子,优于当前最优模型。
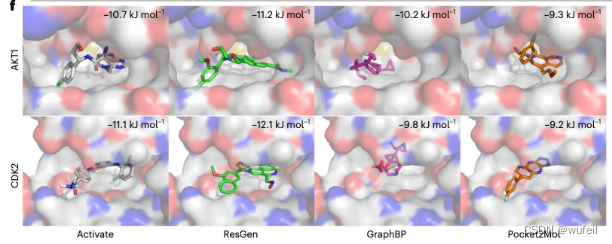
以CDK2和ATK1两个靶点为例,作者列出了ResGen模型与GrapBP,Pocket2mol
对比的结果,发现ResGen能生成Vina score更低的分子,如下图。
其实,基于E3等变网络的分子生成模型很多,我们之前就介绍过targetdiff,是基于E3等变模型的扩散分子生成模型。
但是,这些模型大多数都是基于ENGG网络(EDM网络),模型结构都基本一致,分子和蛋白的表示方法非常相同,均以原子坐标和元素种类的onehot,可能加上电荷。
文章之间的差别仅有生成网络结构或者应用的区别。
例如:3DLinker,是基于VAE架构的E3等变分子生成网络。targetdiff,是基于E3等变模型的扩散分子生成模型。
而且这些模型的特点是,可以生成3D的分子。
这篇文章的作者,显然是做药物设计出身的,计算背景。
理解到,当前这些模型表示分子的方式过于简单,模型处理分子-蛋白的方法过于粗糙,于是,想通过更加合理的E3模型架构(前文提到的两层自回归模型,全局自回归和分子成分自回归)实现更好的实现生成更加有“活性”的分子。
所以这篇文章的亮点在于口袋的parallel multiscale modelling,作者并没有简单而直接的套用EDM等等变网络。
这就是药物设计专家的AI思路,比的不是更好的通用模型,而是更符合药物设计的模型架构。
与之类似的思路,中国科技大学的刘琦老师,也是类似的思路,例如之前介绍的FLAG, 是基于motif来实现的分子生成。
二、文章中模型结果
作者比较了GraphBP, Pocket2Mol, ResGen,以及测试集中(生成分子) top k 小vina score 的平均值,以及对应的QED, SA等类药性质,结果发现,ResGen要明显好于其他方法,也好于测试集。结果图下表:
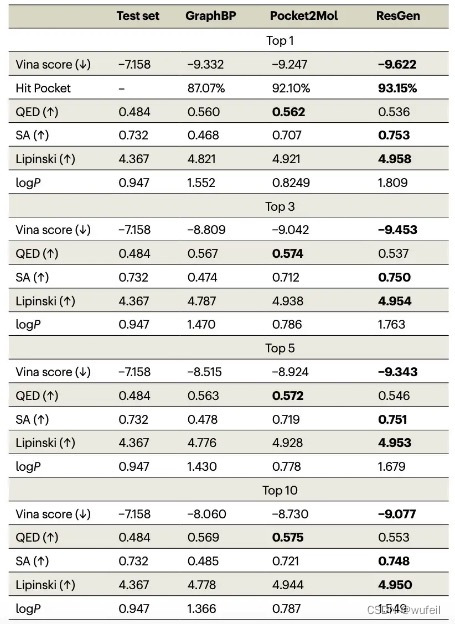
其中,hit Pocket,代表生成的分子对于给定目标具有比其原始配体更高的结合亲和力的概率。
在生成分子的多样性方面,ResGen模型生成的分子更加的多样,如下表:

作者以AKT1和CDK2作为案例,比较了生成分子的vina score 分布,生成构象与预测构象的RMSD,以及生成分子的相互作用。
发现,ResGen生成分子的Vina score 更低,说明结合力越强,捕获到更多的相互作用,生成的构象与软件计算的构象更相似。
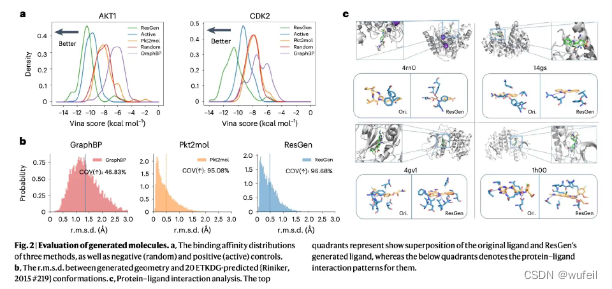
作者同样分析了在AKT1和CDK2两个体系上生成分子的vina score 和类药性质,如下:

但是通过这个案例,以及前文的图,好像ResGen生成的分子更大,那么Vina score就会更低。
可能模型更好的学会了,在口袋中长分子?当然,能把分子长出来就是能力。
此外,SA打分更高,说明生成分子的可合成型更好。
RSMSD更低,说明ResGen生成的分子更真实。这些都说明ResGen模型要优于GraphBP, Pocket2Mol。
关于生成分子构象更合理的方面,作者计算了不同原子键类型的键长分布的Jensen–Shannon散度(较低的值表示两个分布更相似)。
结果如下表:

可能是由于同一时期的缘故,作者并没有对Targetdiff进行对比。
看起来,ResGen生成分子的可合成性更好一些,更类药一些。
三、案例实测
下面我们进行简单的测评。
3.1 复制项目
首先复制项目
git clone https://github.com/HaotianZhangAI4Science/ResGen.git复制完成后,项目目录为:
.
├── ckpt
├── configs
├── data
├── evaluation
├── examples
├── figures
├── gen_all.py
├── gen.py
├── LICENSE
├── models
├── process_data.py
├── readme.md
├── resgen.yml
├── train.py
└── utils
8 directories, 7 files3.2 环境安装
执行如下代码。
(注:不同的机子配置很有可能安装不同,需要多尝试一下。作者使用的pytorch-cluster 安装比较诡异):
# 创建环境
conda create -n Resgen python=3.10
conda activate Resgen
# 安装pytorch,严格按照cuda版本
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
#
conda install pyg -c pyg
conda install -c conda-forge rdkit
conda install biopython -c conda-forge
conda install pyyaml easydict python-lmdb -c conda-forge
conda install pytorch-cluster -c pyg
conda install -c conda-forge torch-scatter
作者提供了训练好的模型checkpoint,下载链接:
https://drive.google.com/file/d/1RoVnHBLuPGFh2qGlCMoCRKtY-Rribp0j/view
下载的ckpt为:val_172.pt。下载完成后,放置在./ckpt目录下。
3.3 案例测试
作者提供了两个测试体系,分别为4iiy和14gs。
我们先创建一个测试文件夹 Test, 然后将./example文件夹下的4iiy.pdb和4iiy_ligand.sdf,复制到Test目录下。
cp ./examples/4iiy.pdb ./Test/
cp ./examples/4iiy_ligand.sdf ./Test/3.3.1 4iiy
4iiy的口袋比较深,小分子很好嵌入在口袋中,如下图:
我们尝试使用下面命令生成分子:
python gen.py \
--pdb_file ./Test/4iiy.pdb \
--sdf_file ./Test/4iiy_ligand.sdf \
--outdir ./Test_4iiy \
--device cpu # cuda其中,--sdf_file ./examples/4iiy_ligand.sdf 为对应的配体,用于识别配体中心,以便生成分子。
运行输出:
... ...
successfully generate: O=C1C=C=NC=C1
successfully generate: O=C1C=CN=C=C1O
successfully generate: Oc1cccc(O)c1
successfully generate: O=C1C=C(CO)C=CC1
successfully generate: O=c1cc(CO)cc[nH]1
successfully generate: O=C(O)CCOCCO
successfully generate: O=P1(O)OCC(O)CO1
successfully generate: O=C(O)CCC(=O)CO
successfully generate: O=C1C=C=CC(CO)=C1
... ...
# 一共会产生100个分子我这里是使用CPU生成分子的,时间大约花了2个小时。
(GPU我也试了一下,3090 花了20分钟。。。效率有点慢,没有作者说的那么快)
运行完成以后,会在./目录下生成./Test_4iiy文件夹,./Test_4iiy目录内容如下:
(base) [wufeil@a01 Test_4iiy]$ tree -L 2
.
└── 4iiy_ligand
├── 4iiy_ligand_gen.sdf
├── 4iiy.pdb
└── SDF其中,SDF文件夹是保存了每个生成的分子,一共生成了100个分子。默认是生成100个分子。
所有分子汇总保存在了4iiy_ligand_gen.sdf文件夹内,挑选序号分别为:1,10,20,50,100的分子,截图如下:
如上图所示,分子似乎是不断长大的。更多的分子结构展示如下视频:
从视频结果来看,确实是逐渐长大的,而且分子的类型并不多,相同的子结构现象明显。
从smiles中更明显,生成smile中有明显重复的结构:OCC(O)C(O)CO和O=C1C=CC(O)CN1。
ResGen模型更像是生成了一两个系列的小分子,而不是完全不一致的小分子。
当然,这就是自回归生成模型的特点,初始生长的分子片段,很大程度上会影响后期生长出来的分子片段。
当然,也可以理解为ResGen模型生成了一个分子,就是最后一个102分子,如下图:

ResGen模型有一个优点,那就是,生成的分子的构象,感觉上更为合理,而且健和原子种类更合适,更像一个药物分子。
这一点是targetdiff等模型做不到的。
四、总结
这是一个非常好的分子生成项目,而且还开源了。项目代码也比较完整。
侯廷军老师的工作特点,正如之前所说的,非常靠近药物设计。
虽然,模型不是那么前沿,没有利用了diffusion之类的,但是值得好好学习。
毕竟,合适才是最好的。
但是模型也存在一些问题,生成效率慢,100个分子使用 3090 GPU花费了20分钟。
另外就是,生成分子的多样性太少,100个分子,实际上只有几个有用的分子,仅包含2~3个系列。
这两个问题,都与自回归模型有关。
github 链接:
GitHub - HaotianZhangAI4Science/ResGen: 3D_Molecular_Generation















 1092
1092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









