







1.词形还原与词干还原
说来惭愧得很,在NLP中这两个术语我老是忘记。在这里记录一下。
词干还原为Stemming,主要是去除词缀得到词根的过程,可以理解为从一个单词的前面和后面删去字符,留下词根。比如将effective还原为effect。
词形还原为lemmatization,主要是指将单词还原为一般形式,比如将did还原为do。
2.TFIDF的计算
TF为文档频率,IDF为逆文档频率。TF的计算公式为tfij= fij / mi,在这里mi指的是第i篇文档中出现最多的词的出现频率,之所以要除以mi是为了消除文档长度的影响。IDF的计算公式为idfj= log2(n/nj) +1 nj >0。idfj是为了衡量词本身的区分性。只在某些篇文档出现的单词是一个好“词”。
综上所述公式为:tij=tfij*idfj = (fij / mi) *(log2(n/nj) +1) when nj >0
3.熵,联合熵,条件熵,互信息,点间互信息
熵描述随机变量的不确定性,随机变量越不确定,熵就越大。从信息论的角度来理解,熵用来描述随机变量的平均信息量,而平均信息量用随机变量的平均编码长度来衡量。其计算公式为:
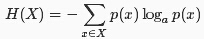
联合熵描述X和Y两个离散型随机变量共同的不确定性,假设它们的联合分布密度为p(x,y),则X,Y的联合熵定义为:
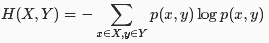
条件熵描述在已知一个离散型随机变量的情况下,另外一个离散型随机变量的不确定性,假如它们的联合分布密度为p(x,y),则给定X时Y的条件熵定义为:
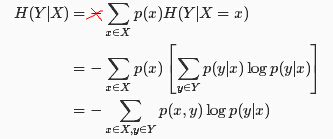
联合熵和条件熵满足链式规则:
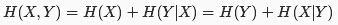
而互信息的定义如下,其含义为包含在X中的有关Y的信息量,或包含在Y中有关X的信息量。

随机变量X,Y之间的互信息定义为:
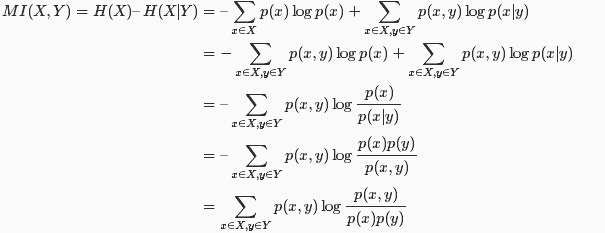
互信息的性质为:
1. MI(X,Y)>=0等号成立当且仅当X和Y相互独立。
2. MI(X,Y) = MI(Y,X)说明互信息是对称的。
在计算语言学中,更为常用的两个具体事务之间的互信息,称之为点间互信息。时间x,y之间的互信息MI(x,y)定义为:
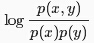
点间互信息度量两个具体时间之间的相关程度:
当I(x,y) >>0 时,x和y高度相关。当I(x,y) = 0时,x和y相互独立。当I(x,y) << 0时,x和y呈互补分布。
相对熵
设p(x)、q(x)是随机变量X的两个不同的分布密度,则它们的相对熵定义为:
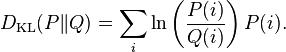
相对熵一般也称之为KL距离,KL距离不满足对称性,用来度量一个随机变量的不同分布的差异性。















 1461
1461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









