







本学期的室内导航位置服务课程结束了,最后有一个结课作业做了一些工作,在这里分享给大家,同时也是自己的一个记录。
主要内容包括以下四个方面:
模型驱动PDR
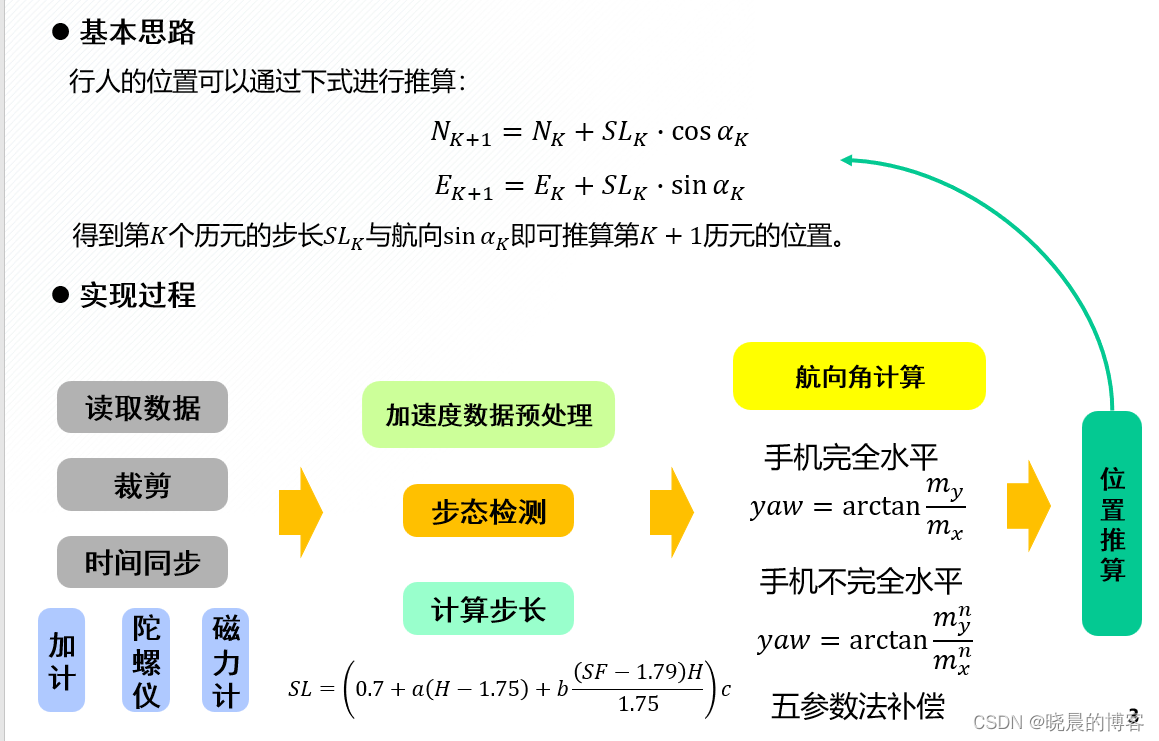
详细可参考PDR (Pedestrian Dead Reckoning)行人航位推算基本原理及实现
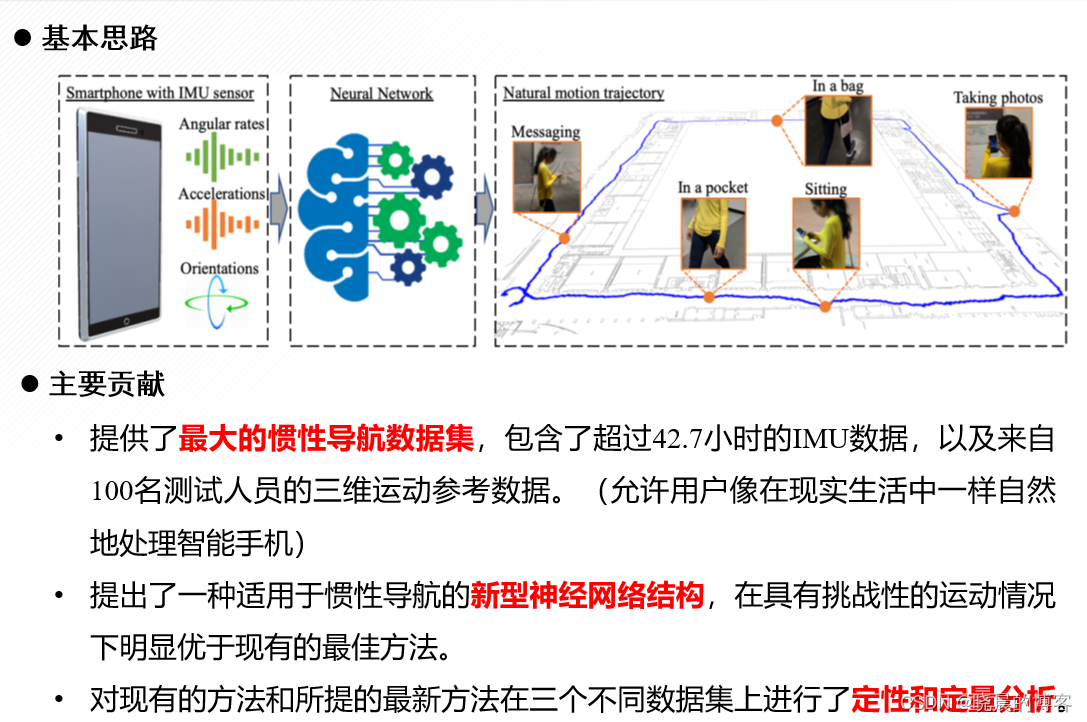
数据驱动PDR
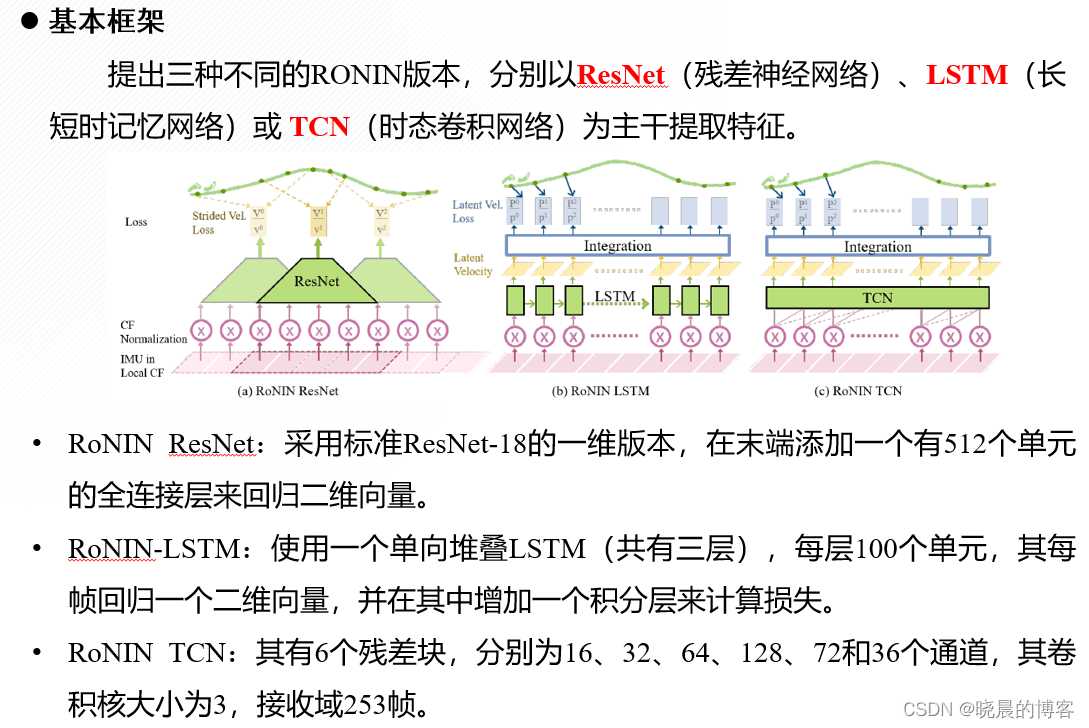
这里使用的是RONIN模型:RoNIN: Robust Neural Inertial Navigation预训练模型测试
实验效果对比
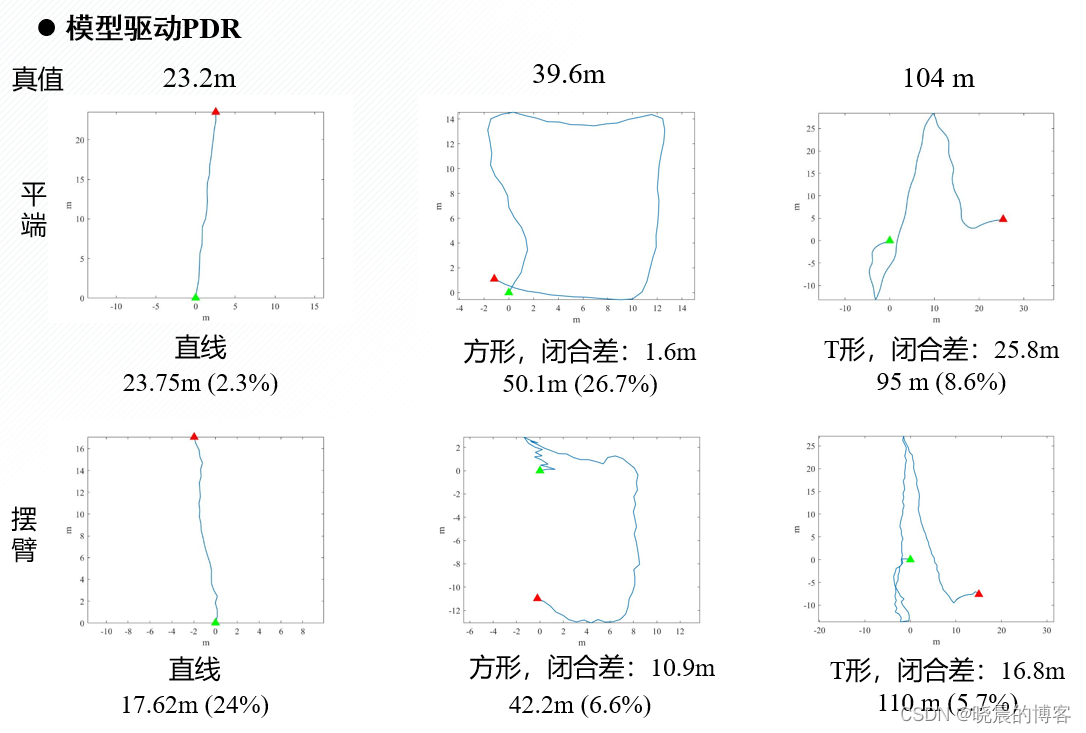
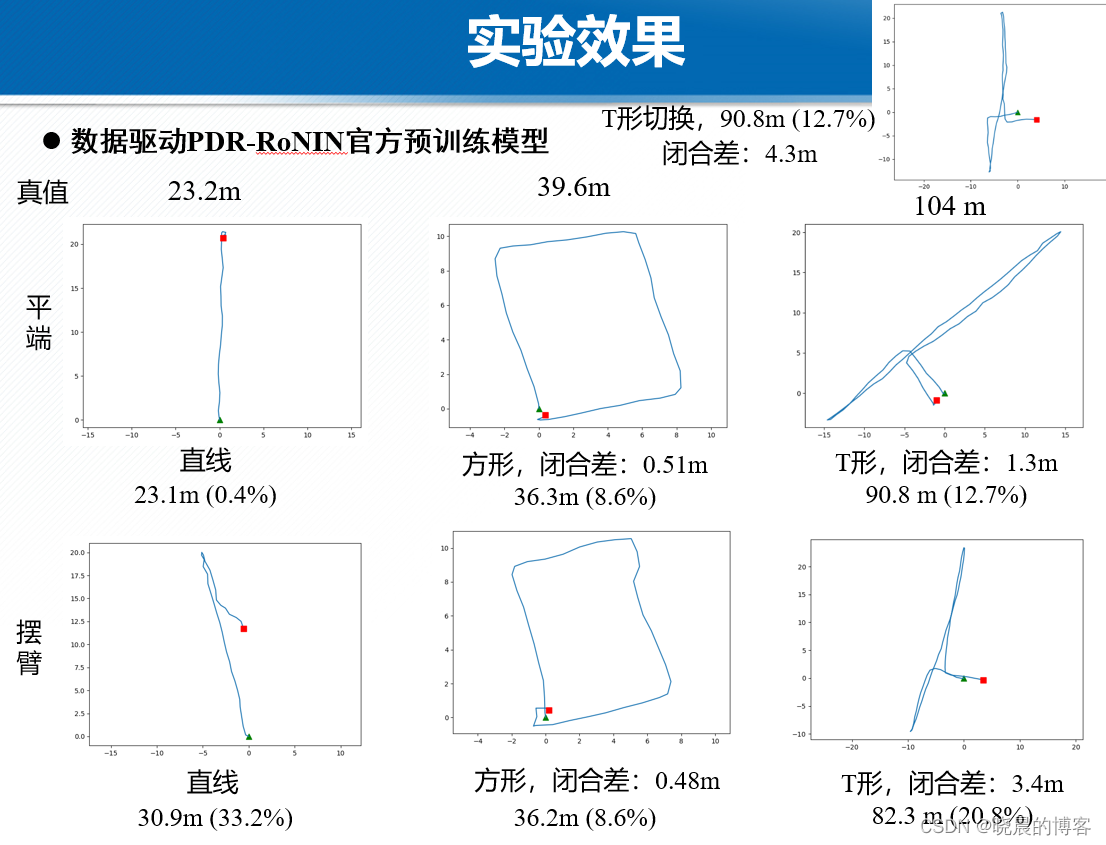
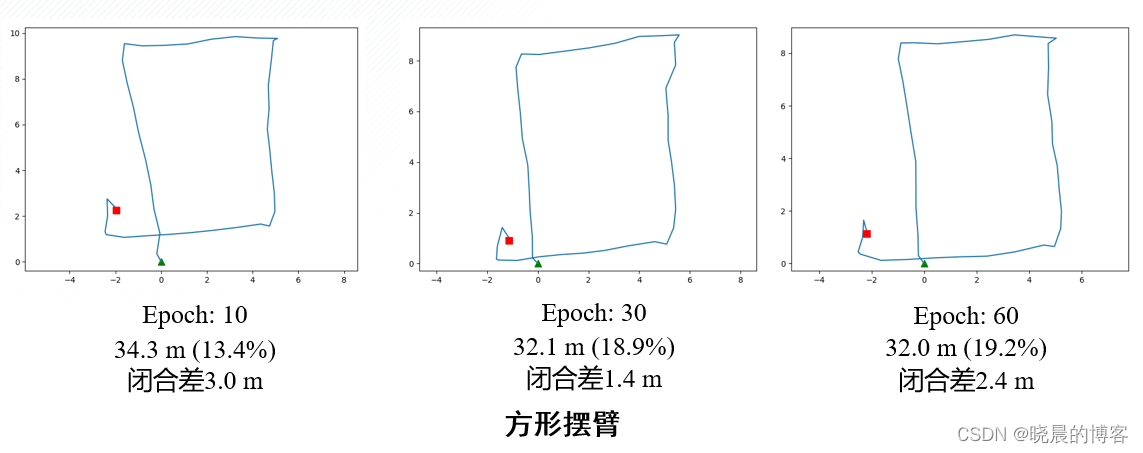
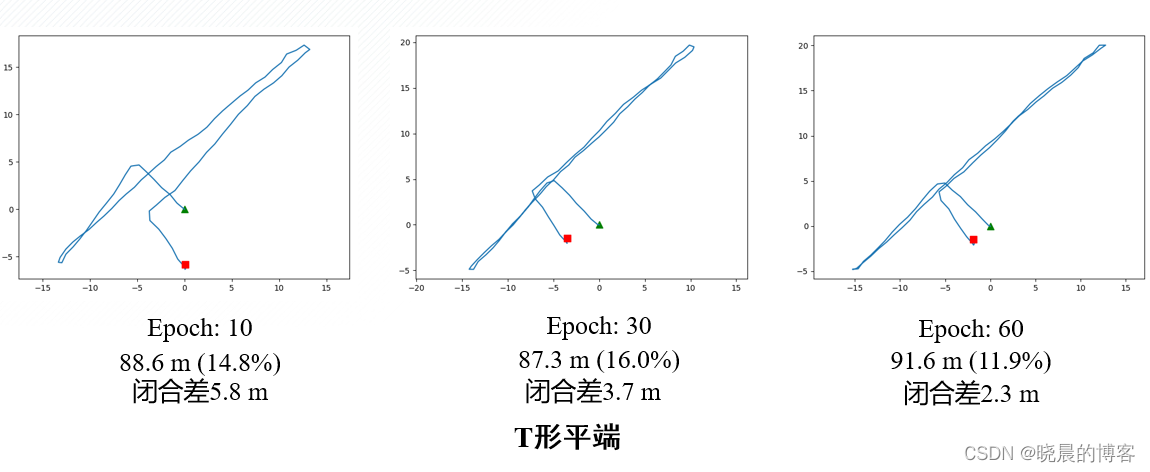
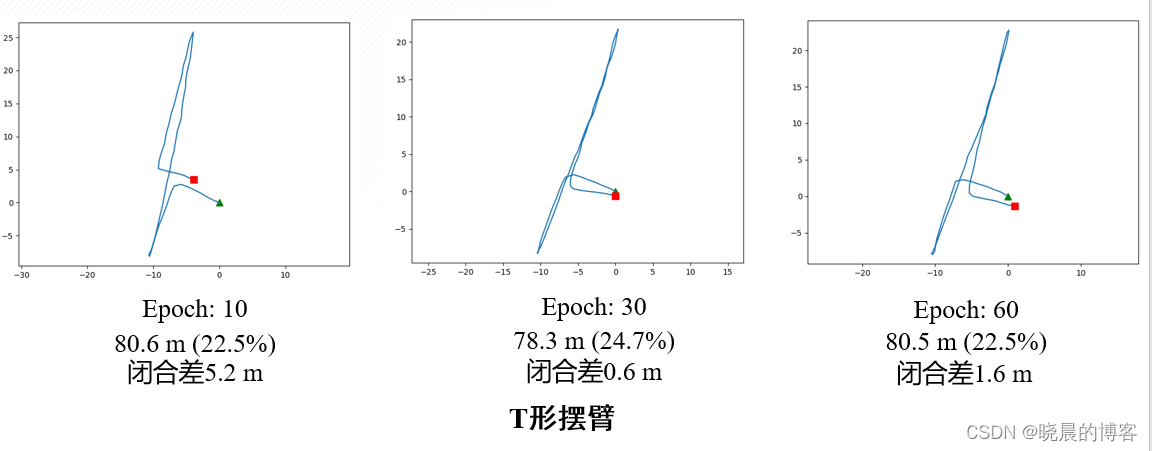
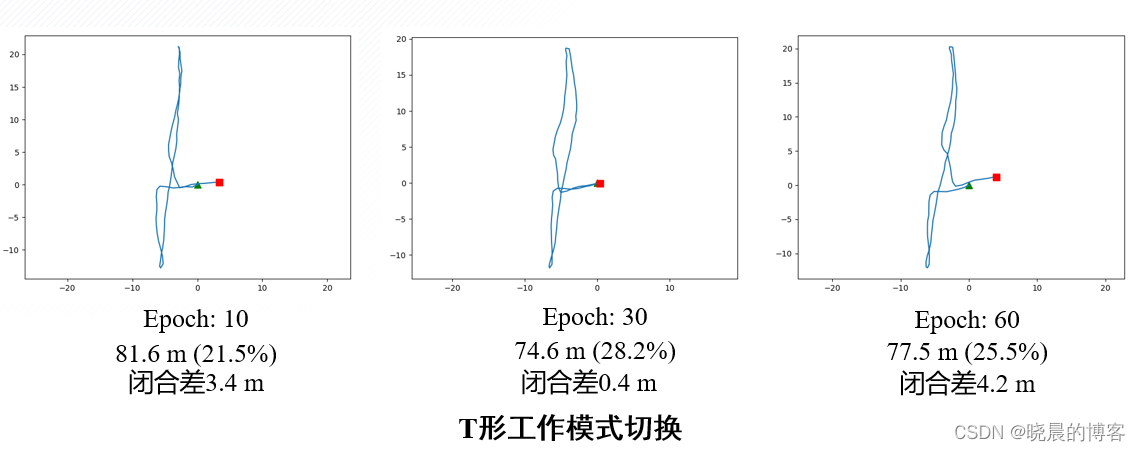
使用自采的三个不同形状数据直线、方形、T形,进行测试。
模型驱动PDR测试效果
数据驱动PDR-RoNIN官方预训练模型
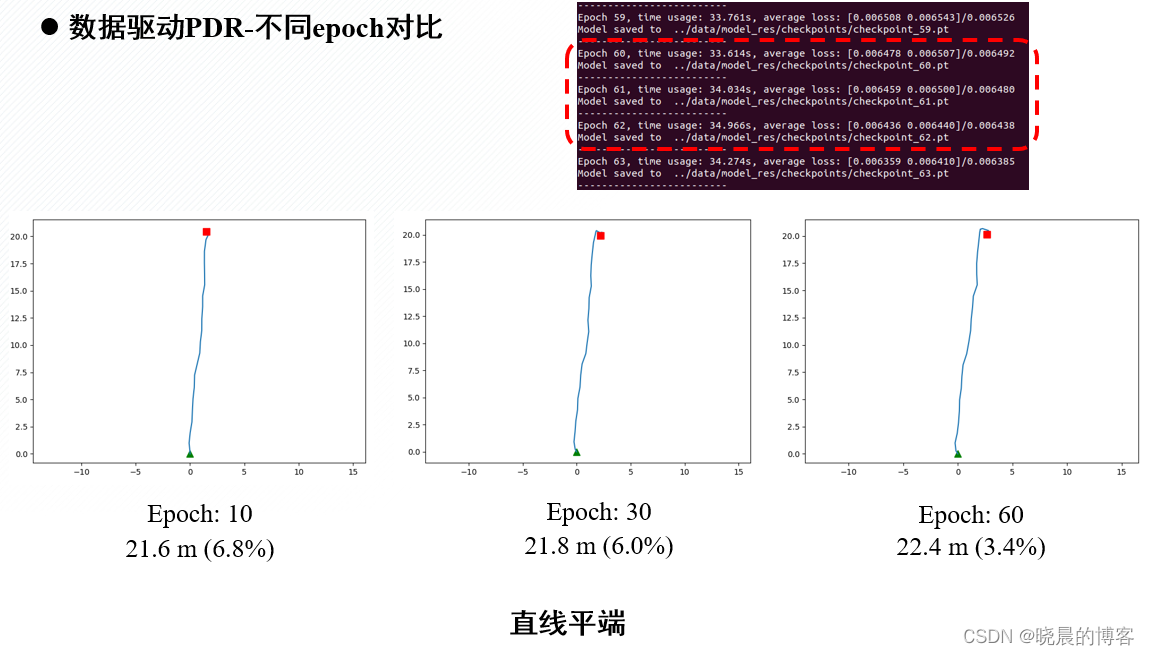
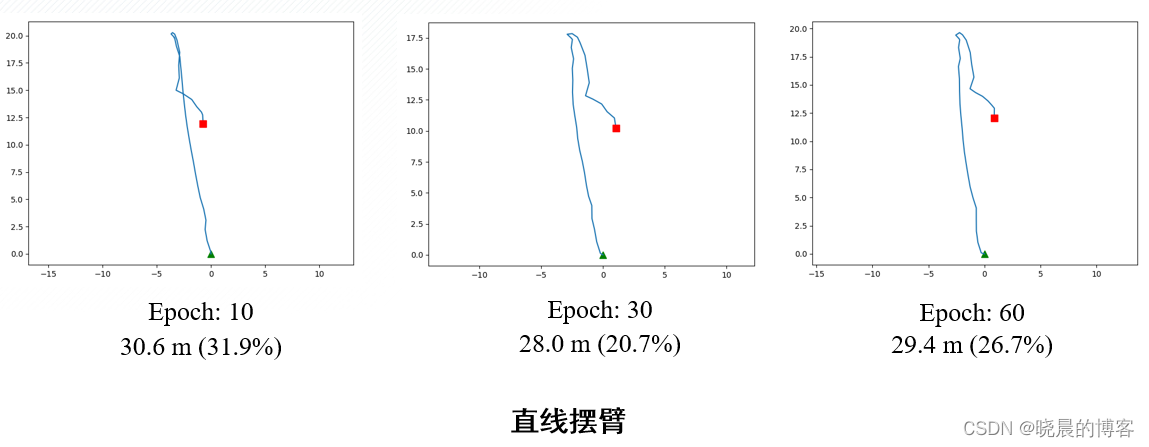
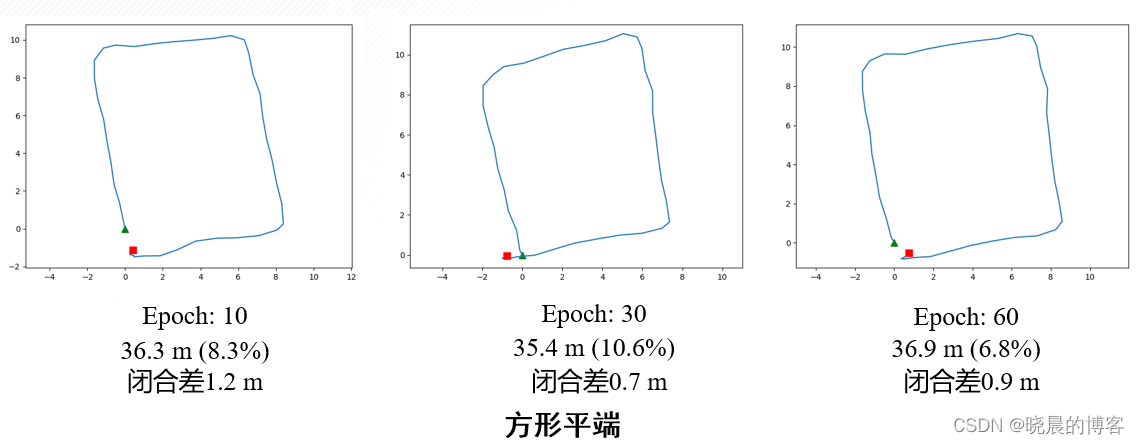
数据驱动PDR-自主训练
总结展望
- 相比于模型驱动PDR,数据驱动PDR的鲁棒性更强,尤其能够较好的处理转弯,掉头等航向角迅速变化的动作。
- 逐步增加训练epoch能提高模型在复杂运动中的适应能力
- 增加训练数据量,在平端、摆臂等行走状态下,从指标上来看没有明显的精度提高,从视觉效果上来看更加贴近真实情况;
- 增加训练数据量,在T形多种动作切换状态下获取的轨迹长度更加贴近真值。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











