







 文章介绍了如何使用AutoGluon进行模型优化,包括设置训练时间、选择评价指标、调整参数如`time_limit`,`eval_metric`,`presets`来提高输出精度。此外,还提到了模型的验证、特征重要性的输出和模型性能的可视化。文章强调了通过调整参数和使用GPU可以进一步提升模型的准确性,并提供了代码示例来展示模型训练和预测的过程。
文章介绍了如何使用AutoGluon进行模型优化,包括设置训练时间、选择评价指标、调整参数如`time_limit`,`eval_metric`,`presets`来提高输出精度。此外,还提到了模型的验证、特征重要性的输出和模型性能的可视化。文章强调了通过调整参数和使用GPU可以进一步提升模型的准确性,并提供了代码示例来展示模型训练和预测的过程。
【AutoGluon_02】更优精度与特征重要性
除了autogluon最基础的模型之外,还可以对其进行调参等操作,这样跑出来可以有更高的准确率。
1、优化改良版autogluon
参数设置:
(参数设置)增加训练时间的一般都会增加输出精度
time_limit : 模型训练的最长等待时间,通常不设置
eval_metric: 指定评价指标例如,AUC还是精度等
‘f1’ (for binary classification),
‘roc_auc’ (for binary classification),
‘log_loss’ (for classification), ‘
‘mean_absolute_error’ (for regression),
‘median_absolute_error’ (for regression)
presets: 默认为’medium_quality_faster_train’,可以按medium_quality good_quality high_quality best_quality的顺序测试,找到适合的模型。损失了精度但是速度比较快。要是设置为“best_quality”,则会做bagging和stacking以提高性能。
presets=‘best_quality’:利用bagging/staking,准确度高但是运行时间长。
presets=‘medium_quality’:选择的算法运行时间较短,但准确率会差一点。
折中的办法就是:presets=[‘good_quality’, ‘optimize_for_deployment’]
Tuning_data: 这个作为验证集数据的参数,官网建议如果没有特别的理由时不加,让机器自己从训练集中分割出一小部分验证集,这边值得一提的是机器还能自己根据数据使用分层抽样等,可以说是非常人性化了。
holdout_frac:这个参数指定从训练集出分割出多少比例的验证集
num_bag_folds = 5-10,这个应该是类似k倍交叉验证,会增加训练时间
num_stack_levels = 1-3,stacking 水平
num_bag_sets:减少方差,但是增加训练时间
优化改良版代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from autogluon.tabular import TabularDataset, TabularPredictor
df = TabularDataset('test.csv')
label = "label"
X=df
y=df[label]
#划分数据集并使用autogluon自动训练, 可根据需要指定预测方式problem_type=‘regression’: 回归问题;‘classfication’: 分类问题
train_x,test_x,train_y,test_y=train_test_split(X,y,test_size=0.2,random_state=0)
predictor = TabularPredictor(label= label).fit(train_data=train_x,ag_args_fit={'num_gpus':-1})
# predictor = tabular.TabularPredictor(label='Label_mL',problem_type='regression').fit(train_data=train_x,ag_args_fit={'num_gpus':-1})
#使用高质量模型
# time_limit = 60 # for quick demonstration only, you should set this to longest time you are willing to wait (in seconds)
# metric = 'roc_auc'
# predictor = TabularPredictor(label= label, eval_metric=metric).fit(train_data=train_x, time_limit=time_limit, presets='best_quality',ag_args_fit={'num_gpus':-1})
test_data = TabularDataset(test_x)
leaderboard = predictor.leaderboard(test_data) #预测结果看板
#删除标签列作为测试集 ; 也可以选择一个新的需要预测的数据
test_data_t=test_x.drop(labels=[ label],axis=1)
# df2 = TabularDataset('能力值_.csv')
# test_data_t = df2.drop(labels=[ label],axis=1)
#方式1:使用指定最优模型输出结果
# pred_y=predictor.predict(test_data_t,model='XGBoost')
#方式2:使用默认predictor模型输出结果
pred_y=predictor.predict(test_data_t)
print(pred_y) #打印预测结果
#预测发生的概率
proba_y=predictor.predict_proba(test_data_t)
print(proba_y)
#结果输出
test_x["pred_y"] = pred_y
test_x
# df["proba_y"] = proba_y[1]
# df2.to_csv("result2.csv",encoding="utf_8_sig")
2、快速使用
autogluon自动寻找最优模型:
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/In
c/train.csv')
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/In
c/test.csv')
predictor = TabularPredictor(label='class').fit(train_data=train_data)
predictions = predictor.predict(test_data)
score = predictor.evaluate(test_data)
3、模型训练
- 将数据转换为 autogluon 中所需格式,并定义预测标签,不考虑时间成本追求最优模型,5择交
叉检验、模型融合 - 使⽤CPU训练了⼤约20分钟,可以看到最优模型为 WeightedEnsemble_L3
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = TabularDataset(df_train)
# 预测标签
label = 'satisfaction_level'
# 模型保存⽂件名
save_path = 'agModels-predictClass'
# 建⽴预测模型,verbosity(0~4),默认为2就好
predictor = TabularPredictor(label=label,path=save_path,verbosity=0)
# presets='best_quality'不考虑时间成本,追求最好模型
predictor.fit(train_data,presets='best_quality',num_bag_folds=5,num_bag_se
ts=1,num_stack_levels=1)
# 输出模型表现
predictor.leaderboard(silent=True)
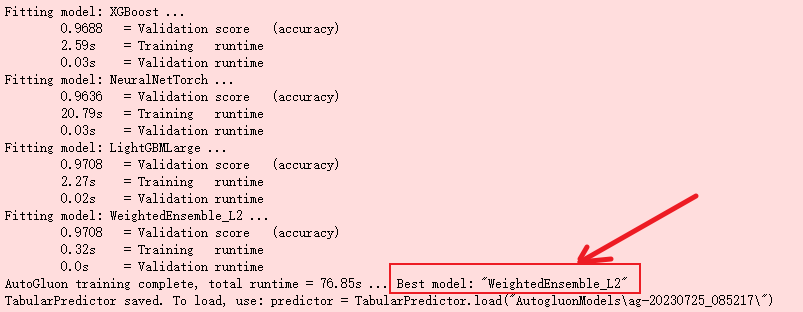
轻量级超参数:
predictor_light = TabularPredictor(label=label, eval_metric=metric).fit(tra
in_data, hyperparameters='very_light', time_limit=30)
excluded_model_types = ['KNN', 'NN_TORCH', 'custom']
predictor_light = TabularPredictor(label=label, eval_metric=metric).fit(tra
in_data, excluded_model_types=excluded_model_types, time_limit=30)
4、更高的输出精度
time_limit = 60 # for quick demonstration only, you should set this to lon
gest time you are willing to wait (in seconds)
metric = 'roc_auc' # specify your evaluation metric here
predictor = TabularPredictor(label, eval_metric=metric).fit(train_data, tim
e_limit=time_limit, presets='best_quality')
predictor.leaderboard(test_data, silent=True)

使用GPU训练:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label=label).fit(
train_data=train_data,
hyperparameters=hyperparameters,
feature_metadata=feature_metadata,
# presets = 'best_quality',
time_limit=0.2*3600,
ag_args_fit={'num_gpus':-1})
# # by default, all available gpus are used by AutoMM
# predictor.fit(hyperparameters={"env.num_gpus": -1})
# # use 1 gpu only
# predictor.fit(hyperparameters={"env.num_gpus": 1})
5、模型评估
(1)模型排行榜
predictor.leaderboard(test_data, silent=True)#输出排⾏榜
predictor.leaderboard(extra_info=True, silent=True)#输出拓展的每个算法运⾏数据的排⾏榜
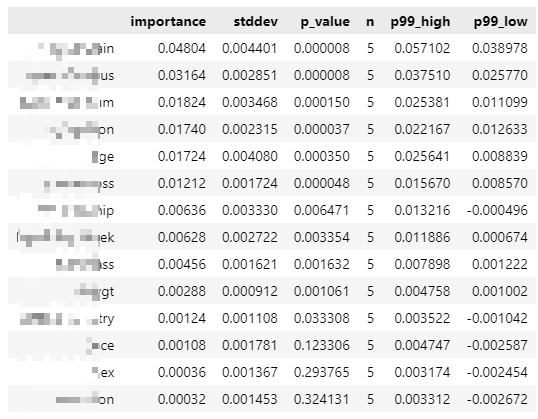
(2)输出各特征重要性
# 删除其余模型(减少内存开销)
predictor.delete_models(models_to_keep='best')
# 输出最优模型
predictor.get_model_best()
# 输出特征重要程度
predictor.feature_importance(train_data)
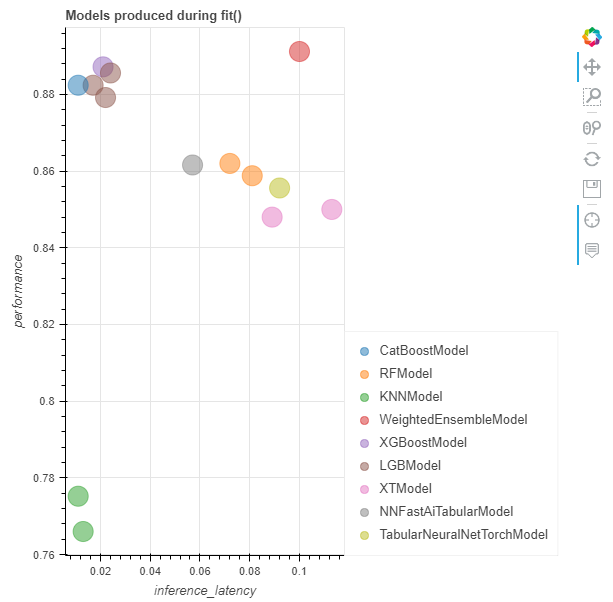
(3)模型性能可视化
返回拟合过程中的各个指标:时间、精度等
results = predictor.fit_summary(show_plot=True)
6、输出最终模型
直接输出6种评估指标,以及预测结果
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxilia
ry_metrics=True)# 结果评估
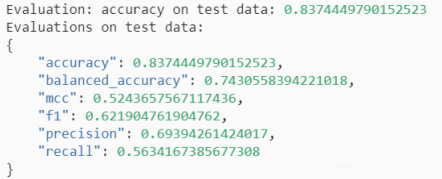
输出指定值,准确率、召回率、F1值
7、预测
查看模型信息:
predictor.problem_type # 查看预测类型,即回归还是分类
predictor.feature_metadata # 数据标签列的数据类型
predictor.features() # 特征
predictor.get_model_best() # 输出表现最好的模型
导⼊测试数据集, autogluon 会⾃动使⽤最优模型进⾏预测:
# 导⼊预测数据
test_data = TabularDataset(df_test)
# 导⼊模型
predictor = TabularPredictor.load(save_path)
# 得到预测值
y_pred = predictor.predict(test_data)
y_pred
#预测发⽣的概率
proba_y=predictor.predict_proba(test_data_t)
print(proba_y)
当我们调⽤时,AutoGluon 会⾃动使⽤ 在验证数据上显示最佳性能的模型(即 加权系综)。相反,我们
可以指定⽤于哪个模型 像这样的预测:predict()
predictor.predict(test_data)
predictor.predict(test_data, model='LightGBM')


















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











