







这里写自定义目录标题
1、保存预测好的模型
在训练好autogluon模型之后,可以将模型进行保存。之后当有新的数据需要使用autogluon进行预测的时候,就可以直接加载原来训练好的模型进行训练。
import pandas as pd
from sklearn.model_selection import train_test_split
from autogluon.tabular import TabularDataset, TabularPredictor
label='bugState'
predictor = TabularPredictor(label=label,path="bugStatemodel").fit(df4)
其中,参数path="bugStatemodel"就表示在当前路径下新建一个叫bugStatemodel的文件夹,里面存放着训练好的模型
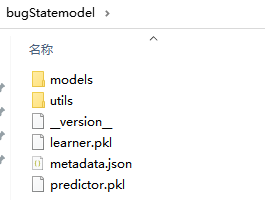
当要调用模型时:
predictorbs = TabularPredictor.load("bugStatemodel")
bs_pred = predictorbs.predict(test_data)
也可以一次性调用多个训练好的模型:
from autogluon.tabular import TabularDataset, TabularPredictor
predictorCBT = TabularPredictor.load("CBTmodel")
predictorCBD = TabularPredictor.load("CBDmodel")
predictorRE = TabularPredictor.load("REmodel")
predictorXDL = TabularPredictor.load("XDLmodel")
test_data = TabularDataset(yc) # yc是新的数据,即要使用autogluon预测的数据
CBT_pred = predictorCBT.predict(test_data)
CBD_pred = predictorCBD.predict(test_data)
RE_pred = predictorRE.predict(test_data)
XDL_pred = predictorXDL.predict(test_data)
2、将预测结果与原数据进行拼接
import pandas as pd
from sklearn.model_selection import train_test_split
from autogluon.tabular import TabularDataset, TabularPredictor
# 读取数据集
data = df
# 划分训练集和测试集
train_df, test_df = train_test_split(data, test_size=0.1)
# 创建TabularDataset对象
train_data = TabularDataset(train_df)
test_data = TabularDataset(test_df)
# 定义标签列名
label_column = 'bugState'
# 创建TabularPredictor对象,并进行训练
predictor = TabularPredictor(label=label_column,path="bugStateModel")
predictor.fit(train_data)
# 输出测试集和测试集标签集的原始数据
test_labels = test_data[label_column]
print("测试集原始数据:")
print(test_df)
print("测试集标签集原始数据:")
print(test_labels)
# 使用AutoGluon预测测试集数据
test_predictions = predictor.predict(test_data)
# 将测试集原本的标签列和预测之后的标签列合并为一个DataFrame
test_result = pd.concat([test_df, pd.Series(test_predictions, name='predictions')], axis=1)
# 输出测试集原本的标签列和预测之后的标签列
print("测试集原本的标签列和预测之后的标签列:")
print(test_result)
test_result.to_excel('8月7号输出1.xlsx')

















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











