






目的
本博客总结最近看的几篇关于深度学习的SLAM以及基于深度学习的稠密重建,简要对比记录特点
对比
| 年份 | 名称 | 类型 | 框图 | 前端 | 输出 | 地图 | 方法 | 特点 | 回环 |
|---|---|---|---|---|---|---|---|---|---|
| 2023 | Point-SLAM | RGBD-SLAM | 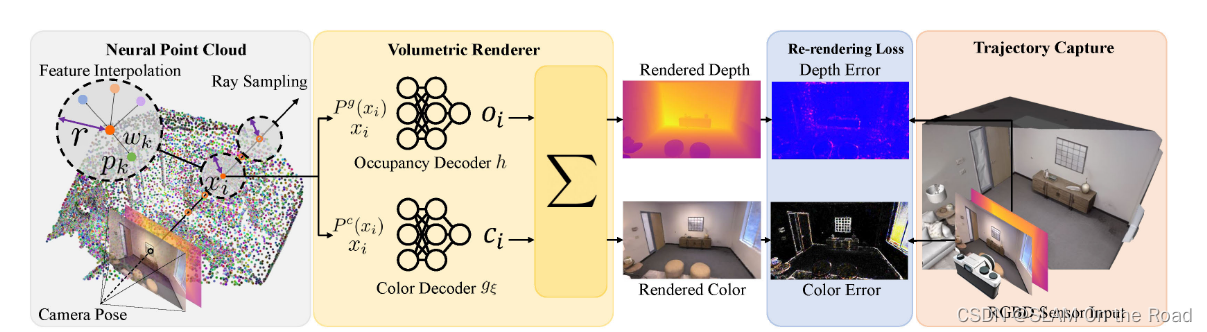 | 渲染的RGB和深度loss来优化pose和点的神经描述子 | 每帧pose和全局点云稠密地图 | 全局点云稠密地图 | 点云周围提取特征,MLP解码,渲染得到RGB和深度图像,loss优化位姿和点云神经描述子 | 没有回环 | |
| 2023 | DIM-SLAM | mono-VSLAM | 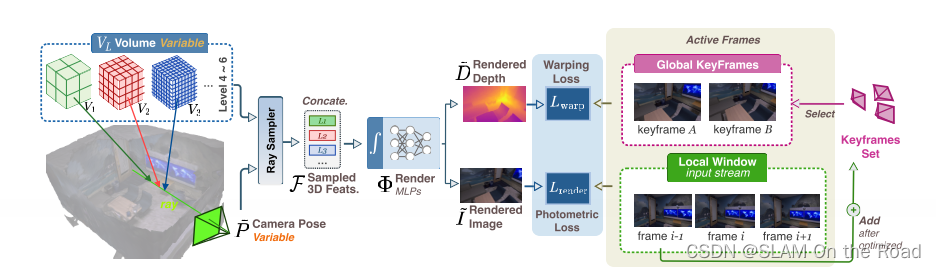 | 重投影patch损失+ RGB图像loss | 每帧的pose和最终的全局稠密地图 | 全局稠密地图 | 多分辨率特征网格+MLP解码器+ RGB损失+重投影多帧path的光流损失 | 输入RGB图像,不需要深度图像,重建稠密地图 | 没有回环 |
| 2023 | NICER-SLAM | mono-SLAM | 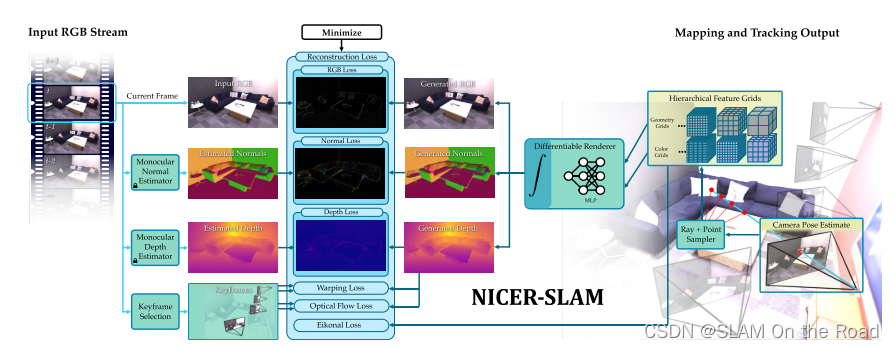 | 单目深度估计+单目法向量估计+光流估计 | 每帧的pose和SDF提取的稠密点云或mesh | 全局SDF优化 | 多分辨率分层网格+MLP解码+多项损失最小化 | 单目获取稠密地图并输出位姿 | 没有回环 |
| 2023 | Orbeez-SLAM | mono-slam | 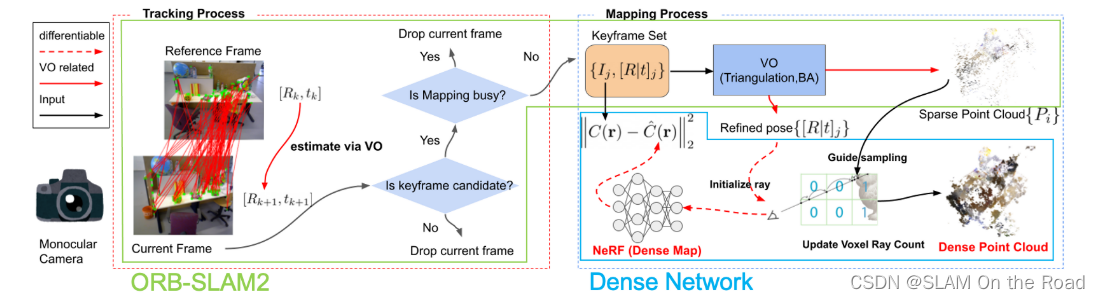 | VSLAM | 每帧的pose,稀疏点云地图,NERF获取的稠密点云地图 | 前端ORBSLAM2估计位姿和稀疏点云地图, 后端NERF估计稠密MLP地图 | 前端后端解耦合,前端传统SLAM算法 | 回环可以依靠ORBSLAM2 | |
| 2022 | DPVO | mono-VO | 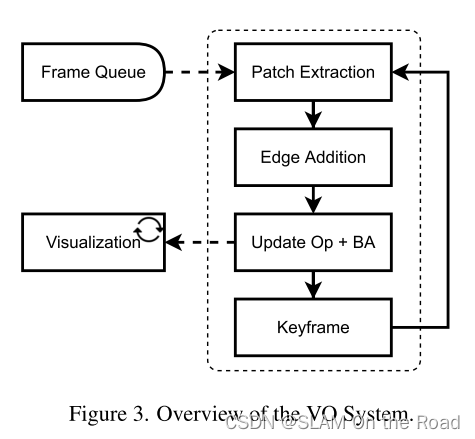 | VO | 每一帧的pose和paches转到3D坐标系下的3D点,稀疏点云 | 稀疏3D点云拼接 | 提取每张图的feature_map, 随机提取多个patch + 根据初始位姿投影到滑窗内的其余帧 + 网络迭代找到匹配点target + 每个patch投影到其余帧,和对应的匹配点target构成重投影误差,BA优化滑窗内帧的位姿和匹配点target的位置+ patch为二维块,其中心对应的逆深度,加上当前帧的pose,可以转为3D点云。 | patch匹配时考虑了局部特征和context特征,BA优化时候,也优化patch轨迹,即2D匹配点位置 | 没有回环 |
| 2022 | GCVD | mono-sfm | 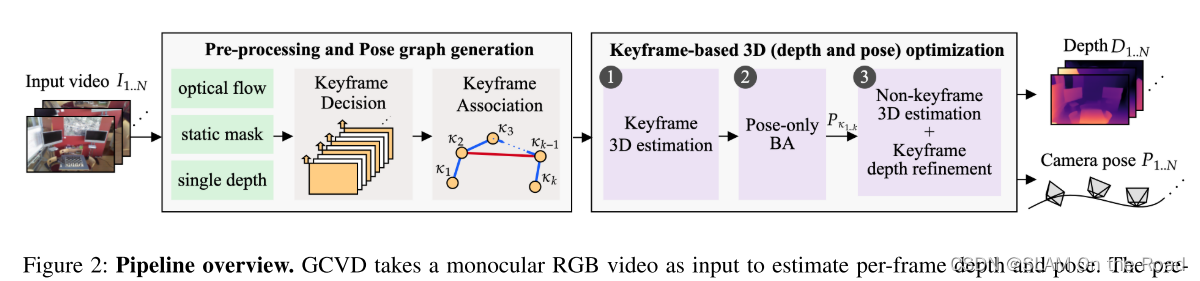 | RAFT稠密光流, MASK-CNN剔除动态物体 | 视频流的所有相机位姿和稠密深度图像 | 没有建图 | RAFT稠密光流相邻帧的相对pose+MSCK-CNN语义剔除动态物体+MiDAS估计深度先验+光流视差筛选关键帧+深度特征聚合关键帧,并稠密光流计算相对pose+构建带权重的pose-graph+ 仅优化pose的BA + 网络固定pose, 优化关键帧和非关键帧的深度(代价方程:两帧之间的投影光度误差+光流一致性+地图一致性) | 全局一致性 | 有 |
| 2022 | ParticleSfM | mono-sfm | 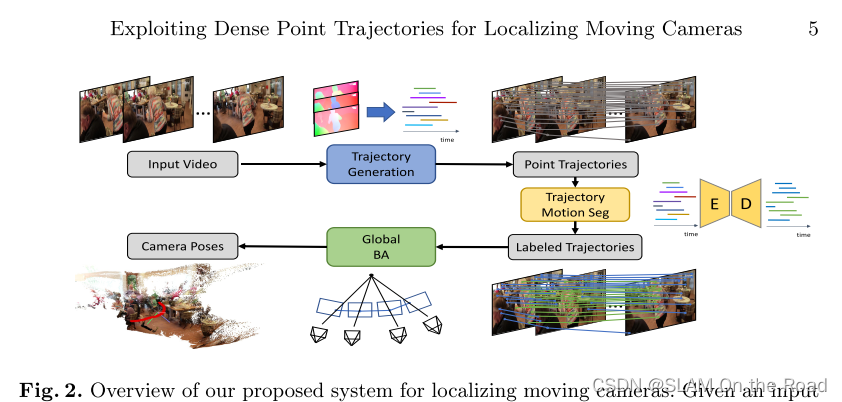 | RAFT连续跟踪多帧 | sfm地图和相机pose | 全局sfm稠密特征点地图 | RAFT稠密光流连续跟踪+光流剔除动态物体+光流多帧构建track+ 全局sfm BA | 动态物体剔除,网络泛化好 | 没有回环,类似滑窗光流SLAM |
| 2021 | DROID-SLAM | mono-VSLAM |  | 全图像素点+稠密光流匹配 | 输出每个关键帧的位姿和稠密深度图像 | 全局场景稠密点云地图 | RAFT稠密光流+稠密BA+重投影误差 | GPU显存占用较大(前端实时需要8GGPU显存,后端由于需要存储所有图像的featuremap,因此,显存占用会很大,5000帧需要24GB),位姿和全局地图精度高 | 遍历全部关键帧构建帧图 |
| 2021 | NeuralRecon | mono-TSDF重建 |  | 分段TSDF重建+GRU融合 | 位姿已知 | 全局TSDF稠密网格 | 没有全局优化,实时稠密单目重建,增量式重建 | 认为位姿已知且准确 | |
| 2021 | CodeMapping | Mapping |  | 基于稀疏特征SLAM | 输出每个关键帧的位姿和稠密深度图像 | 全局3D TSDF模型 | 稀疏基于特征法得到的关键帧位姿,稀疏点云,稀疏点的平均重投影误差,VAE估计初始带有不确定度的稠密深度图像+多帧优化当前帧的稠密深度 | 与稀疏SLAM(ORBSLAM3)并行,不直接优化深度像素点,优化一个深度code | 回环依靠稀疏SLAM保证,多帧优化时不优化关键帧位姿,仅优化深度code。 |
| 2021 | TANDEM | Mono-VSLAM |  | 稠密直接法,采用TSDF中投影到当前帧的较稠密深度 | 输出每个关键帧的位姿和稠密深度图像 | TSDF稠密建图 | 稠密深度图像直接法前端+ 稀疏梯度点关键帧滑窗BA后端,类似DSO | 类似DSO | 没有回环和全局BA,实时VO位姿和多帧MVS融合的关键帧稠密深度图像 |
| 2020 | DeepFactors | Mono-VSLAM |  | 整张图像的LK光流,跟踪上一个关键帧 | 输出每个关键帧的位姿和稠密深度图像 | 全局场景稠密点云地图 | 整张图像稠密LK光流前端跟踪+滑窗内因子图优化关键帧的pose和深度编码code(光度误差,重投影误差因子,稀疏几何因子)+BRISK描述子,词袋闭环检测 | 深度编码重建的稠密深度不准确 | BRISK描述子回环,因子图增加边。 |
| 2021 | CodeVIO | Mono-VIO |  | 稀疏点跟踪MSCKF-VIO | 输出每个关键帧的位姿和稠密深度图像 | 局部场景稠密点云地图 | MSCKF-VIO + MSCKF优化深度编码(稀疏点云和灰度图像生成关键帧初始深度编码) | 局部点云,且点云不准,位姿精度依靠VIO精度 | 没有回环 |















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









