







M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
概要:
- propose a unified framework to transform multi-camera images to a Bird’s-Eye
View (BEV) representation for multi-task AV perception, including 3D object detection
and BEV segmentation.
- propose several novel designs such as efficient BEV encoder, dynamic box assignment, and BEV centerness.
- large-scale pre-training with 2D annotation (e.g. nuImage) and 2D auxiliary supervision can significantly improve the performance of 3D tasks and benefits label efficiency.
方法:
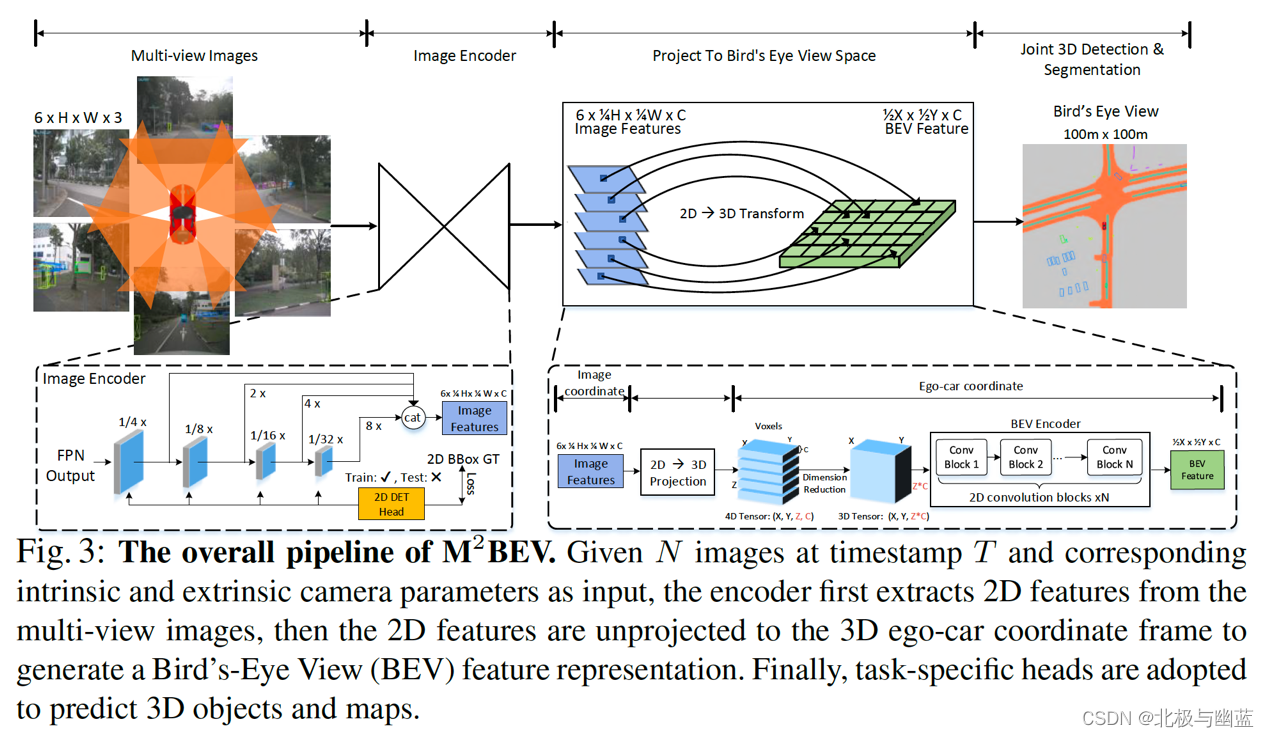
主要步骤和imvoxelnet、cadnn差不多,都通过相机参数把2d feature转换为voxel,然后得到bev。cadnn的voxel直接坍缩到bev,bevformer的bev query被lift成pillar并用预定义large-scale pre-training with 2D annotation (e.g. nuImage) and 2D auxiliary
supervision can significantly improve the performance of 3D tasks and benefits
label efficiency. As a result,的高度投影回fov,M2BEV的voxel过bev encoder得到bev。另外M2BEV是multi-view multi-task。
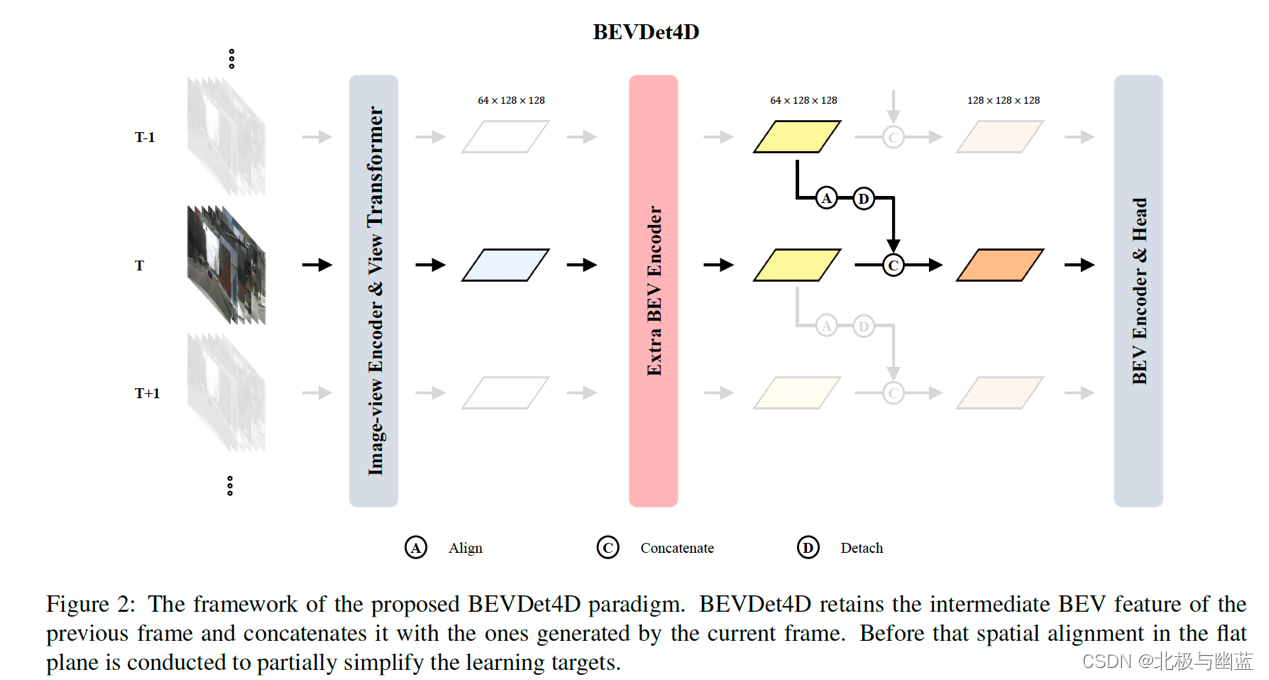
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection
概要:lift the paradigm from the spatial-only 3D space to the spatial-temporal 4D space by fusing feature from previous frame with corresponding one in the current frame
方法:
BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
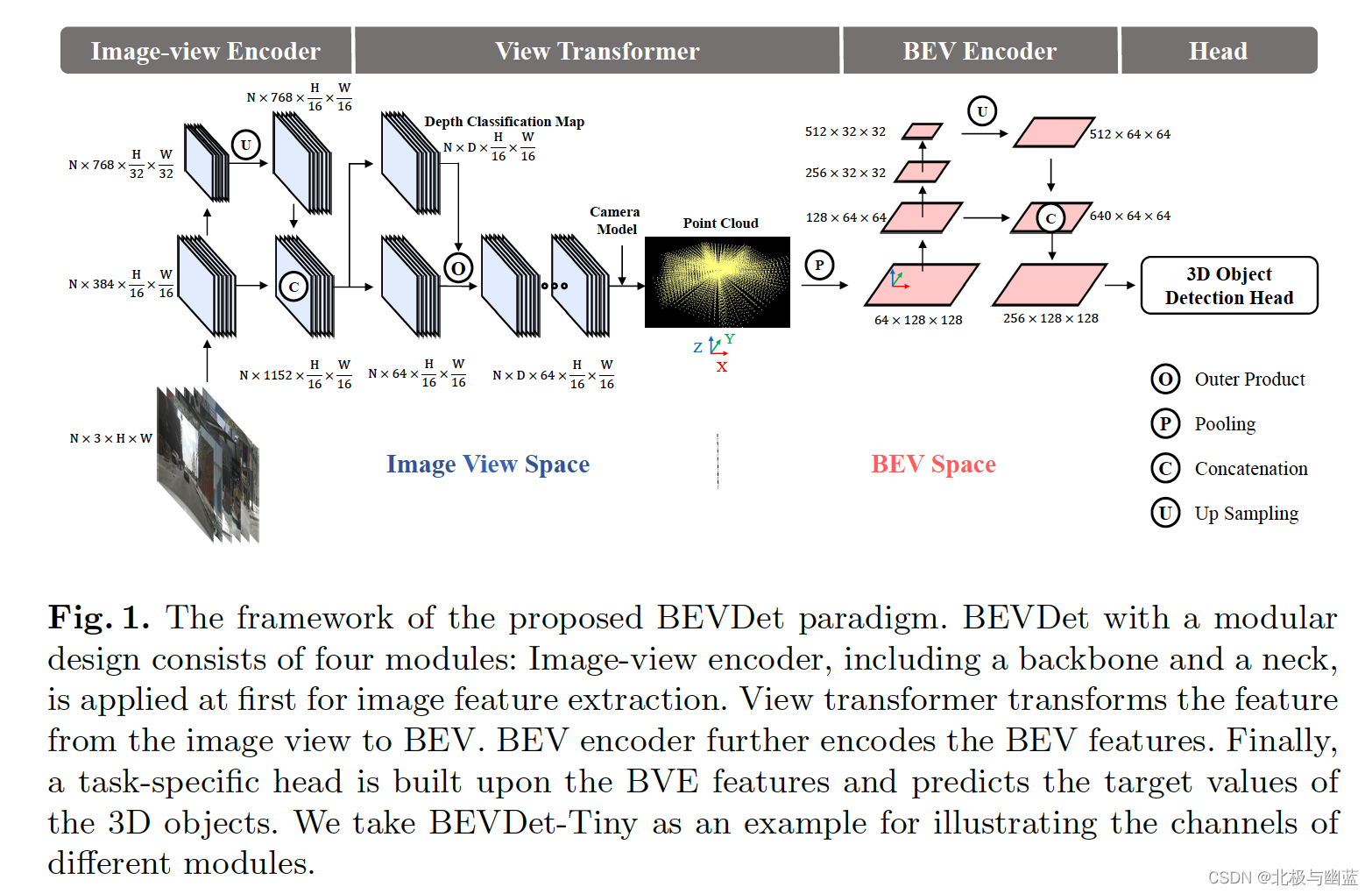
遵循四个模块的pipeline,提出customized data augmentation strategy和Scale-NMS The Isolated View Spaces.
The Isolated View Spaces: 当在input image上做了数据增强A时,为了使特征和BEV空间中的目标播啊吃空间一致性,需要在view transformation中做A的反向变换,这样image view space的数据增强就不会改变BEV空间的spatial distribution,从而可以在image view space执行复杂的数据增强。
BEV Space Learning with Data Augmentation
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D

任意数量的相机 & robust to calibration error
方法和CaDNN几乎一样,区别是CaDNN用到gt depth来预测离散深度,LSS用给定的一系列深度值把fov像素点从(h,w)抬升为(h,w,d)。Shoot用于motion planning具体没看。

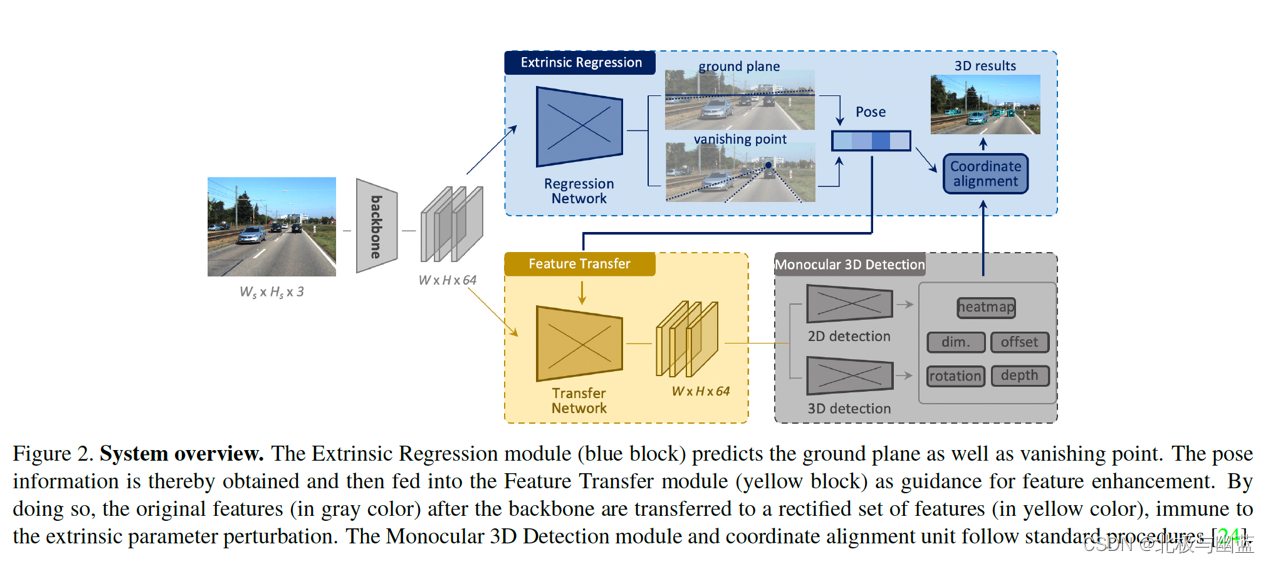
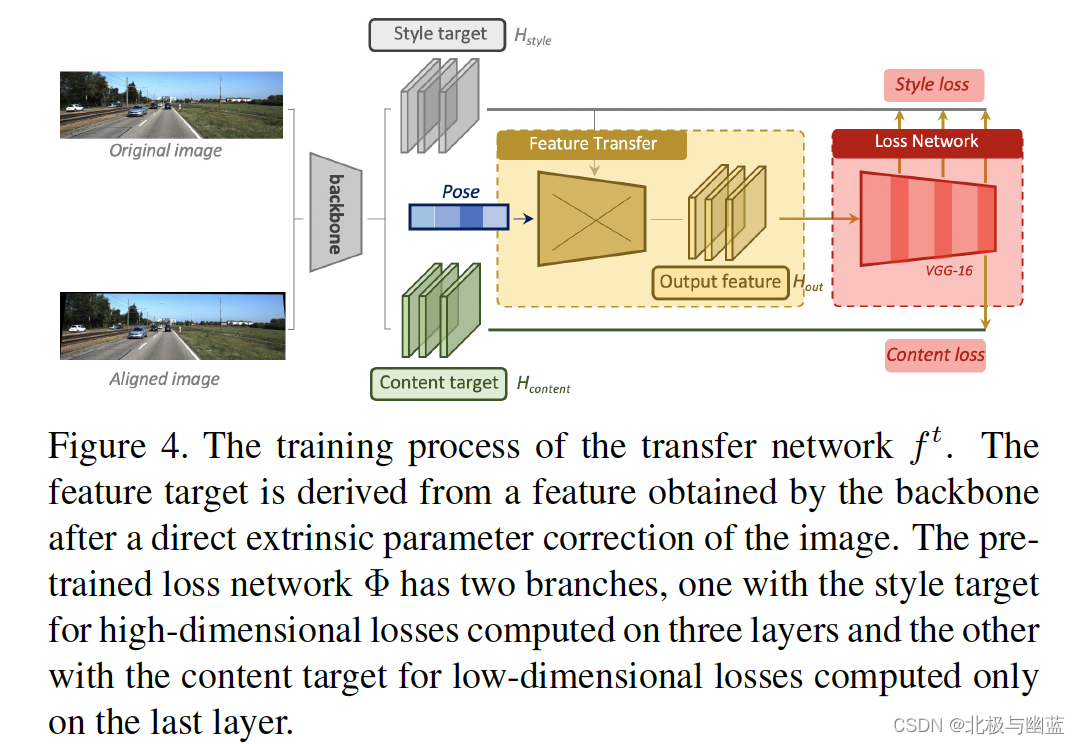
Monocular 3D Object Detection: An Extrinsic Parameter Free Approach
地面不平导致相机看到的物体信息偏离真实物体信息

通过检测vanishing point和horizon change来预测相机外参,从而构建不受extrinsic perturbation影响的检测器。
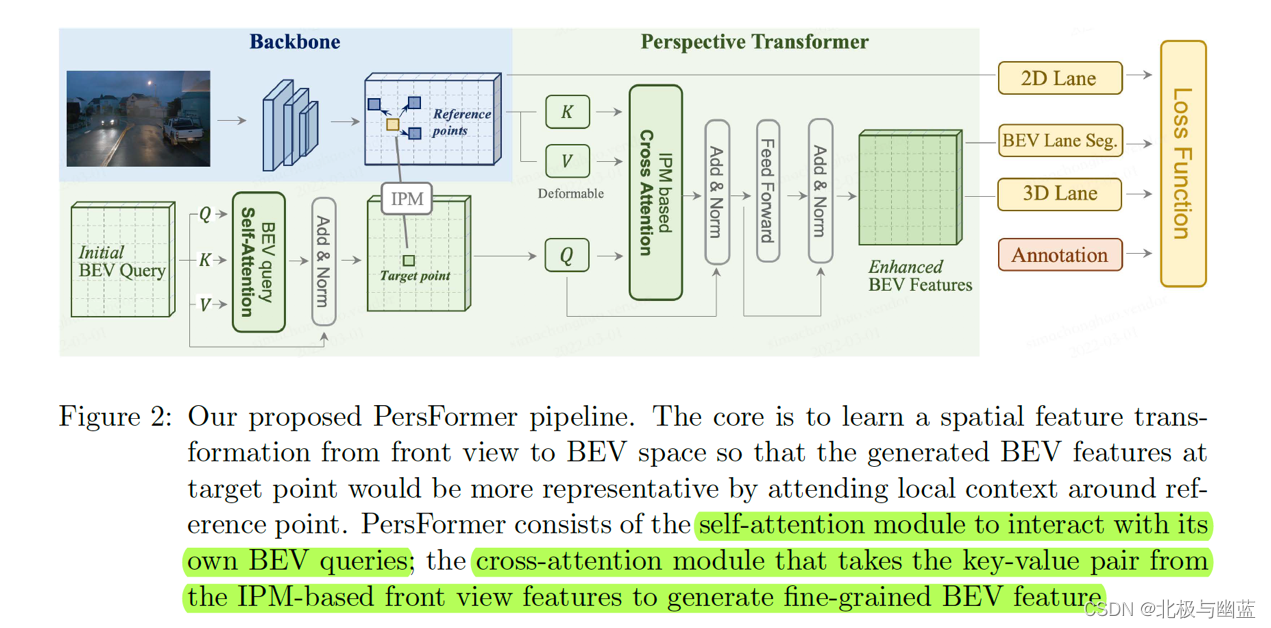
PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark

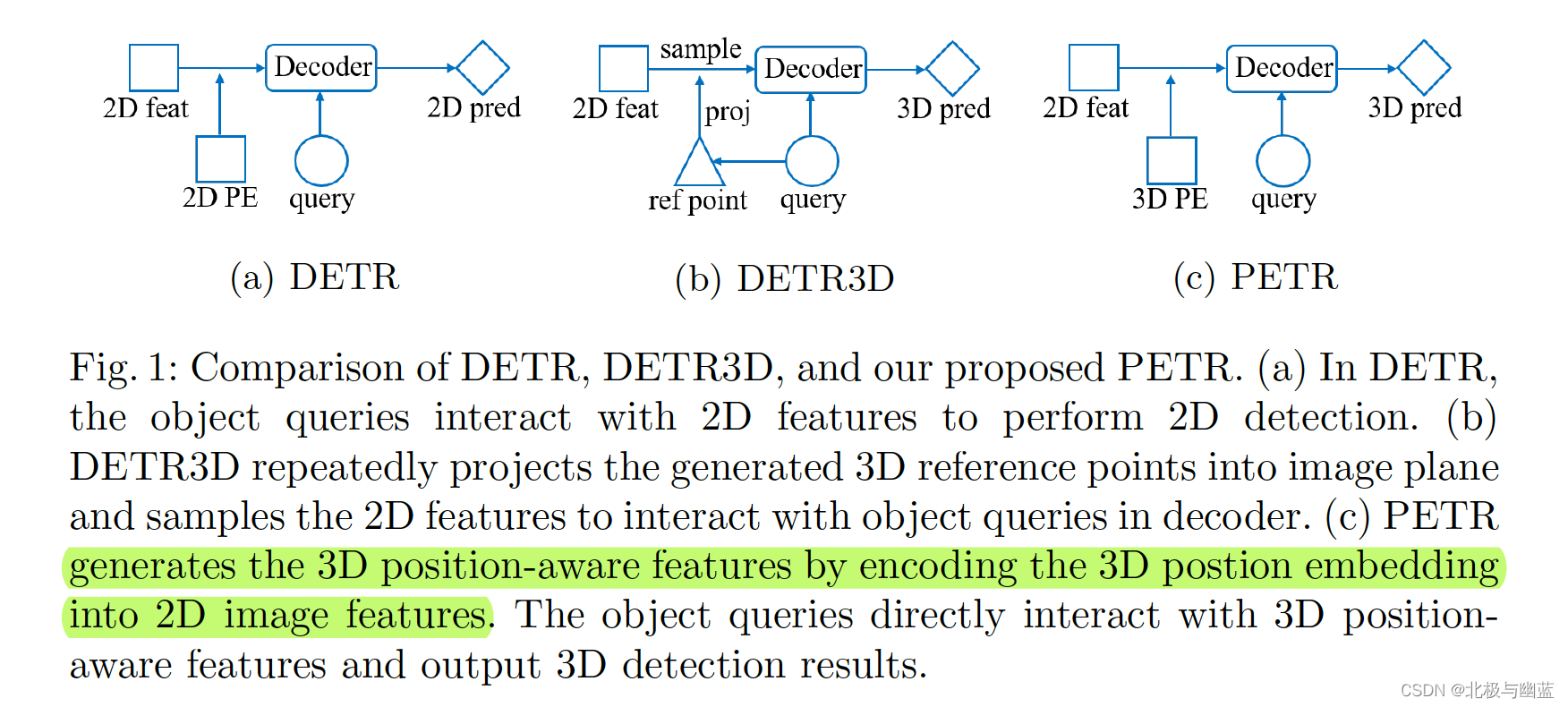
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
核心思想就是把3D坐标的位置信息编码到图片特征里,产生3D position-aware features。与DETR3D相比省去了反投影和采样。
2D特征和3D坐标一起输入3D position encoder得到3D position-aware features。
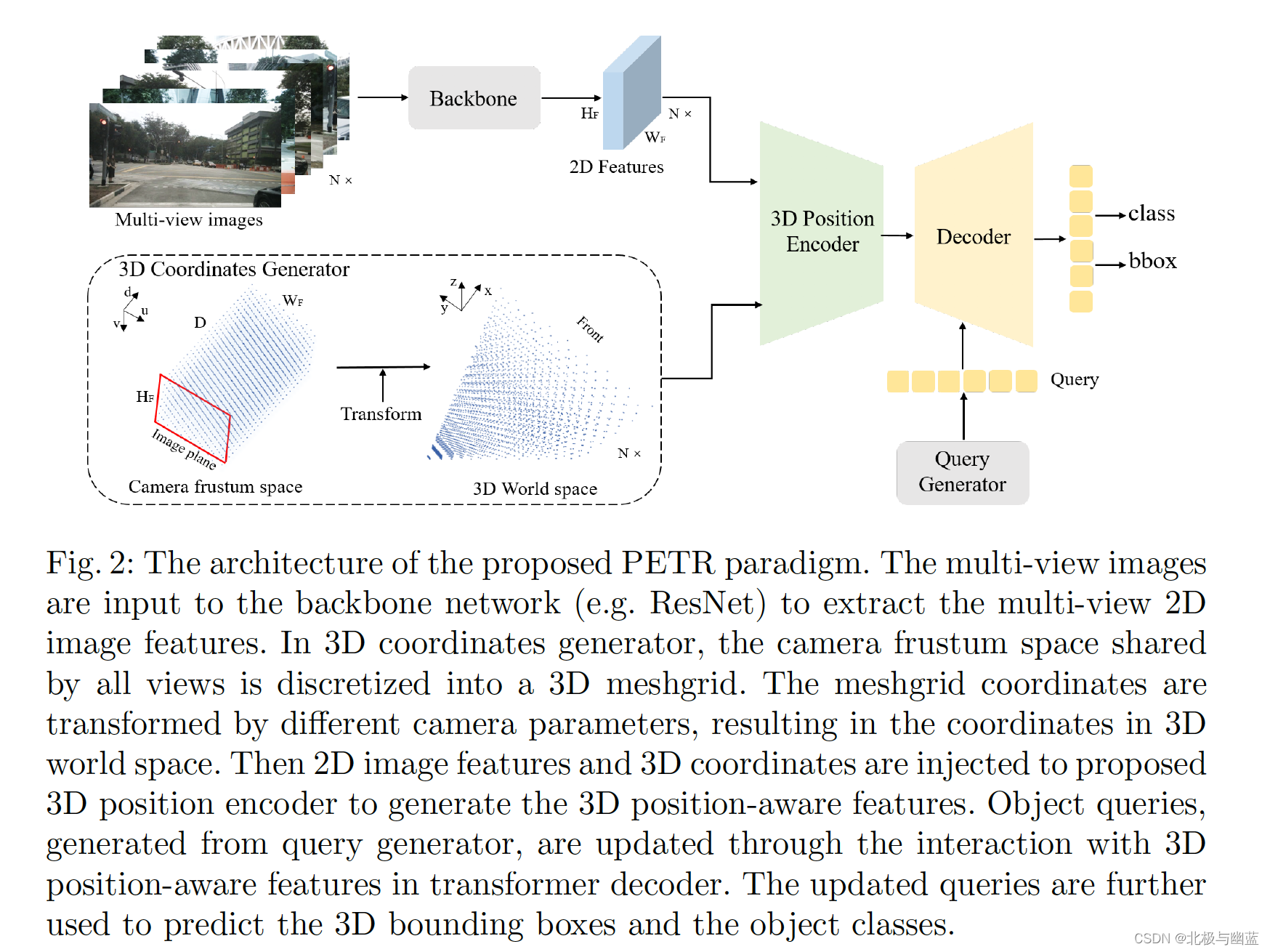
3D PE建立了3D空间中不同视角的位置关联。















 3815
3815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









