






论文《Mining Latent Structures for Multimedia Recommendation》阅读
论文概况
本文是2021年ACMMM 上的一篇论文,该篇文章通过利用物品的多模态信息结合传统CF算法来处理推荐问题。
Introduction
作者提出问题
- 以前的算法一般是通过用户-项目的关系构建图结构,却未能明确地对项目之间的关系进行建模,以下图为例
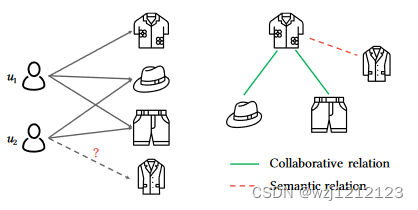
图中用户1与用户2都曾与帽子、短裤交互,根据协同过滤的原则,推荐系统会向用户2推荐用户1曾交互的衬衫,但不会推荐大衣(大衣与上述物品类似,完全有被推荐的理由)。
可以看出,只有协同的物品关系是通过建模高阶项目-用户-项目共现而隐含发现的,这有可能导致与携带语义关系的真正项目-项目关系的差距。
对于上述问题,作者提出一个全新的推荐模型(LATents Tructure miningmethod for multImodal reCommEndation,LATTICE):(1)开发了一个新的模态感知结构学习层,从多模态特征中学习模态感知的项目结构,并聚合模态感知的项目图来构建潜在的多模态项目图。(2)对学习到的潜在图进行图卷积,以明确考虑项目关系。由此产生的项目表征被注入了高阶项目关系,这些关系将被添加到CF模型的输出项目嵌入中
Method
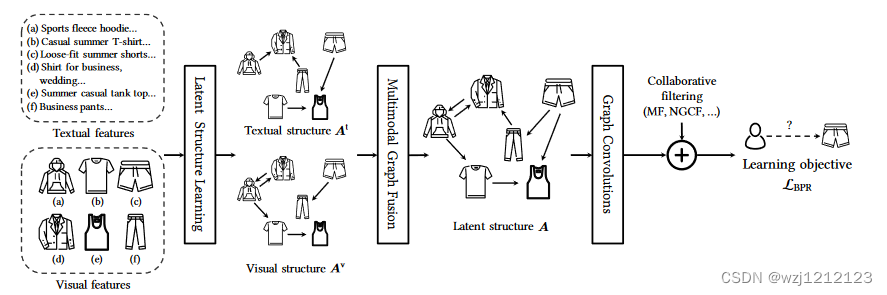
A.Modality-aware Latent Structure Learning
为了将物品与物品之间的关系融入模型,我们先进行物品多模态邻接矩阵的建立,每个模态拥有一个独立的邻接矩阵。邻接矩阵中边的权重是不同模态下两个物品的余弦相似度
S
i
j
m
=
(
e
i
m
)
⊤
e
j
m
∥
e
i
m
∥
∥
e
j
m
∥
.
(1)
S_{i j}^{m}=\frac{\left(e_{i}^{m}\right)^{\top} \boldsymbol{e}_{j}^{m}}{\left\|\boldsymbol{e}_{i}^{m}\right\|\left\|\boldsymbol{e}_{j}^{m}\right\|} .\tag{1}
Sijm=∥eim∥∥
∥ejm∥
∥(eim)⊤ejm.(1)
其中
e
j
m
\boldsymbol{e}_{j}^{m}
ejm表示物品j在模态m下的嵌入。
为了保持矩阵的稀疏性,我们只取矩阵中相似度最高的K条边,其余边的权重设置为0
S
^
i
j
m
=
{
S
i
j
m
,
S
i
j
m
∈
top-
k
(
S
i
m
)
,
0
,
otherwise
(2)
\widehat{S}_{i j}^{m}=\left\{\begin{array}{ll} S_{i j}^{m}, & S_{i j}^{m} \in \text { top- } k\left(S_{i}^{m}\right), \\ 0, & \text { otherwise } \end{array}\right.\tag{2}
S
ijm={Sijm,0,Sijm∈ top- k(Sim), otherwise (2)
(2)所得到的稀疏化的有向图邻接矩阵。为了减轻爆炸或梯度消失的问题,我们将邻接矩阵归一化为:
S
ˉ
m
=
(
D
m
)
−
1
2
S
^
m
(
D
m
)
−
1
2
,
(3)
\bar{S}^{m}=\left(D^{m}\right)^{-\frac{1}{2}} \widehat{S}^{m}\left(D^{m}\right)^{-\frac{1}{2}},\tag{3}
Sˉm=(Dm)−21S
m(Dm)−21,(3)
尽管我们通过利用原始的多模态特征获得了模态感知的初始图结构
S
ˉ
m
\bar{S}^{m}
Sˉm,但它们对于推荐任务可能并不理想。因此我们对每个物品的嵌入进行科学系的线性变化
e
‾
i
m
=
W
m
e
i
m
+
b
m
,
(4)
\overline{\boldsymbol{e}}_{i}^{m}=W_{m} e_{i}^{m}+b_{m},\tag{4}
eim=Wmeim+bm,(4)
其中
W
m
∈
R
d
′
×
d
m
and
b
m
∈
R
d
′
W_{m} \in \mathbb{R}^{d^{\prime} \times d_{m}} \text { and } b_{m} \in \mathbb{R}^{d^{\prime}}
Wm∈Rd′×dm and bm∈Rd′,然后重复(1)(2)(3)过程,得到能更好表达项目之间相似度的邻接矩阵
A
~
m
\tilde{A}^{m}
A~m
然而,尽管初始图可能是有噪声的,但它通常仍带有关于项目图结构的丰富和有用的信息。此外,邻接矩阵的急剧变化将导致不稳定的训练。为了保持初始物品图的丰富信息并稳定训练过程,我们增加了一个跳过连接,将学到的图与初始图结合起来。
A
m
=
λ
S
~
m
+
(
1
−
λ
)
A
~
m
,
(5)
A^{m}=\lambda \widetilde{S}^{m}+(1-\lambda) \widetilde{A}^{m},\tag{5}
Am=λS
m+(1−λ)A
m,(5)
最终,我们将不同模态下的邻接矩阵融合成最终物品相似度邻接矩阵
A
=
∑
m
=
0
∣
M
∣
α
m
A
m
,
(6)
A=\sum_{m=0}^{|\mathcal{M}|} \alpha_{m} A^{m},\tag{6}
A=m=0∑∣M∣αmAm,(6)
其中
α
m
\alpha_{m}
αm是可学习的参数。
B. Graph Convolutions
利用(6)得到的邻接矩阵,我们实现物品与物品之间转化关系的提取
h
i
(
l
)
=
∑
j
∈
N
(
i
)
A
i
j
h
j
(
l
−
1
)
,
(7)
\boldsymbol{h}_{i}^{(l)}=\sum_{j \in \mathcal{N}(i)} A_{i j} h_{j}^{(l-1)},\tag{7}
hi(l)=j∈N(i)∑Aijhj(l−1),(7)
其中
h
i
(
l
)
\boldsymbol{h}_{i}^{(l)}
hi(l)物品i在第l轮的嵌入表示。然后,将最终得到的物品嵌入与用户的初始信息输入之后的CF模型。
C.Combining with Collaborative Filtering
设CF模型最终得到的物品嵌入为
x
i
\boldsymbol{x}_{i}
xi,用户嵌入为
x
u
\boldsymbol{x}_{u}
xu,将CF得到的物品嵌入与利用物品相似度图迭代得到的物品嵌入相结合,得到最终的物品嵌入
x
^
i
=
x
~
i
+
h
i
(
L
)
∥
h
i
(
L
)
∥
2
(8)
\widehat{\boldsymbol{x}}_{i}=\tilde{\boldsymbol{x}}_{i}+\frac{\boldsymbol{h}_{i}^{(L)}}{\left\|\boldsymbol{h}_{i}^{(L)}\right\|_{2}}\tag{8}
x
i=x~i+∥
∥hi(L)∥
∥2hi(L)(8)
物品打分为
y
^
u
i
=
x
~
u
⊤
x
^
i
.
(9)
\hat{y}_{u i}=\tilde{x}_{u}^{\top} \widehat{x}_{i} .\tag{9}
y^ui=x~u⊤x
i.(9)
D. Optimization
采用贝叶斯个性化排名(BPR)损失来计算loss,让预测结果更为准确
L
B
P
R
=
−
∑
u
∈
U
∑
i
∈
I
u
∑
j
∉
I
u
ln
σ
(
y
^
u
i
−
y
^
u
j
)
(10)
\mathcal{L}_{\mathrm{BPR}}=-\sum_{u \in \mathcal{U}} \sum_{i \in I_{u}} \sum_{j \notin I_{u}} \ln \sigma\left(\hat{y}_{u i}-\hat{y}_{u j}\right)\tag{10}
LBPR=−u∈U∑i∈Iu∑j∈/Iu∑lnσ(y^ui−y^uj)(10)
总结
LATTICE模型弥补了传统模型只关注用户-项目转化却忽略了项目本身所蕴含的特征关系的缺陷,实现了能作用在大多数模型基础上创新,相当于优化了其他模型的初始化过程,且在物品嵌入部分加入了物品-物品转化关系。且因为前后部分是分开的,可以利用高性能计算思维来加快代码运行速度。















 1875
1875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









