







MAE是一个视觉领域自监督模型
abstract
摘要的大致介绍模板:
1)文章的写作意图
2)对文字的模型算法的描述
3)模型在某任务的效果
MAE的核心设计:非对称编码器-解码器架构
编码器:仅对可见token(没有mask,未被遮掩的图像块)进行输入,得到一个隐含的特征表示,之后再跟之前被遮掩的块结合输入到解码器中。编码器只接受被曝光的patches作为输入,被遮掩的patches不用输入到编码器中。
轻量级解码器:输入来自编码器的输出 以及编码器中没有被接收到的被遮掩的块。(后面会介绍)
用比较高效的遮掩比例:其次,我们发现掩盖输入图像的高比例,例如75%,产生了一个重要的和有意义的自我监督任务。
Coupling these two designs enables us to train large models efficiently and effectively:
we accelerate training (by 3× or more) and improve accuracy.
efficiently:训练成本低
effectively:可以取得更好的分类效果,分类准确率高
Scalable:(题目)可扩展的,大小模型都可以用这个方法来提高性能。
learning high-capacity models that generalize well:之前在vit中取得的效果并不是很好,本文中通过mae预训练可以使某些模型效果更好。在下游任务也获得了很好的效果。
eg:在仅使用ImageNet-1K数据的方法中,vanilla ViT-Huge模型达到了87.8%的准确率。下游任务的迁移性能优于监督预训练。
introduction
语言和视觉的信息密度不同。语言是人类生成的信号,具有高度的语义和信息密度。当训练一个模型来预测每个句子中仅有的几个缺失单词时,这项任务似乎能诱导出复杂的语言理解。
相反,图像是具有严重空间冗余的自然信号--例如,一个缺失的斑块可以通过邻近斑块恢复,而对部件、物体和场景的高层次理解却很少。为了克服这种差异并鼓励学习有用的特征,我们展示了一种在计算机视觉中行之有效的简单策略:遮盖极高比例的随机斑块。这种策略在很大程度上减少了冗余,并创建了一个具有挑战性的自我监督任务,它需要超越低级图像统计的整体理解。要对我们的重建任务有一个定性的认识,请参见图 2 - 4。
(iii) 自动编码器的解码器将潜在表征映射回输入,在重建文本和图像之间扮演着不同的角色。在视觉中,解码器重建的是像素,因此其输出的语义水平低于普通的识别任务。这与语言不同,在语言中,解码器会预测包含丰富语义信息的缺失单词。在 BERT 中,解码器可以是微不足道的(一个 MLP)[14],但我们发现,对于图像而言,解码器的设计在决定所学潜在表征的语义水平方面起着关键作用。
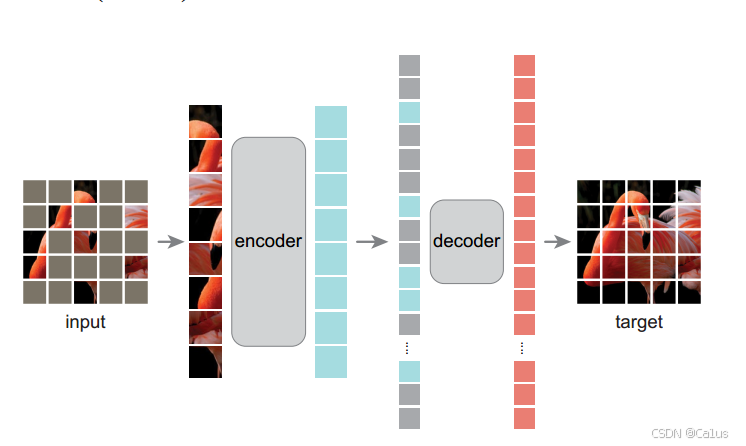
和之前的文章是一样的处理(timm库有现成代码),把图像划分为一个个patches ,二维图像可以类似为转化为sentence一样的一维结构。(encoder是transformer构造的)
把图像的patch随即遮住3/4的比例,把剩下1/4拼成一个序列送到transformer encoder中,得到序列的隐含表示。再把隐含表征跟之前被掩码的哪些部分重新拼起来,恢复成原始图像的顺序(未被掩码的是encoder的输出),mask的那些patches 论文中用的是统一的可学习的mask embedding,没有用到被mask过的那些像素值。
恢复了图像的大小,解码器的输入是更大的序列,得到一个新的隐含表征,做一个回归任务就可以预测target图片。
approach
掩码自编码器(MAE)是一种简单的自编码方法,基于部分可观测的量,en和de都没有用被掩码的像素作为特征输入,只是基于可观测的那些图像部分来预测整个图像(掩码比例非常大)
embedding
nlp的token中语义非常丰富,cv中不一样
与传统的自编码器不同,我们采用非对称设计:
编码器只作用在部分可观测的部分上,没有用到掩码的token
轻量解码器从隐含表征和被掩码的token来恢复原始信号。
(和bret对比:既有也有被mask的单词来作为输入)
masking:
16 16 3
根据ViT,我们将图像划分为规则的不重叠的小块。然后我们对patch的子集进行采样,并掩码(即删除)剩余的patch。
采样策略:对随机斑块进行采样,不进行替换,遵循均匀分布。我们简单地称之为“随机抽样”
high masking ratio:为了消除冗余性,不用这么高很容易预测出来,学不到什么东西。可以学到高效的编码器
MAE encoder:
1.编码器是ViT,只接受未被掩码的patches作为输入
(可以理解为transformer encoder的结构,多头自注意力机制再加两层MLP结构加层归一化行成一个block,堆叠成多个block形成transformer encoder, 输入改为图像就变成个vit)
2.被遮掩的部分都没有作为编码器的输入(不同于以往的自监督方法 nlp)
好处:效率问题。(transformer的计算量和长度的平方成正比,编码器的输入长度大大缩短,比较省计算量,可以训练更大的编码器)这允许我们只用一小部分的计算和内存训练非常大的编码器。完整的集合由一个轻量级解码器处理
MAE decoder:输入的序列长度是完整的长度:
(i) encoded visible patches 编码器编码过后的embedding
(ii) mask tokens.需要重新拼起来
不论是哪个位置被mask掉都是用同一个mask embedding 没有使用被掩码的图像输入
原始的transformer 也是这么做的:解码器的部分利用:位置嵌入positional embeddings
不论是编码器还是解码器都是用一个个transformer block构成的
任务:回归任务:预测完整的图像,
分类任务:是编码器做的,不需要解码器
解码器是做图像重构的回归任务,回归任务的最终目的是学到一个有效的编码器,编码器学完后可以将解码器扔掉,添加一个分类的mlp头,就可以做图像分类任务了。
Reconstruction target:
MAE通过预测每个被屏蔽补丁的像素值来重建输入。
解码器输出中的每个元素都是代表一个patch的像素值向量。
解码器的最后一部分是全连接层:需要映射到一个patch里像素点的个数来做回归任务,
通过映射后的值和原始的像素值之间的差距作为mae的目标函数
预测目标需不需做归一化:可以对一个patch里的像素先求均值和方差,模型效果会更好
我们还研究了一种变体,其重建目标是每个被屏蔽补丁的归一化像素值。具体来说,我们计算一个patch中所有像素的均值和标准差,并使用它们对该patch进行归一化。在我们的实验中,使用归一化像素作为重建目标提高了表示质量。
Simple implementation.mask的简单实现
不需要特殊的稀疏化操作,
首先,可以为每一个输入的图像块生成一个token (token embedding)
其次,对token的列表进行打散shuffle,shuffle之后打乱之后,取其中前25%作为encoder输入,
得到encoded patches,
将encoded patches与其他75%拼起来,做一个unshuffle操作,还原成原始图片的顺序,还原后的序列作为解码器的输入,解码器会以unshffule之后的序列来作为输入,后面的75%会用mask embedding 代替输入到解码器中
总结:
把图片划分成patches 得到patch embedding 拼起来就是一个个token 对token进行shuffle打乱,打乱后去前25%作为编码器输入, 编码完成之后和后面75%拼起来,拼起来之后 进行 unshuffle, 把token的顺序还原成原来图像的顺序关系,被掩码的部分用patch embedding代替,送入解码器中 , 解码器也会加入pisition embedding,解码器最后层做一个 projection,project到每一个像素点的个数上,将预测后的值和正确的像素值算一个loss,就可以完成整个mae的结构。
ImageNet Experiments
做了三个实验
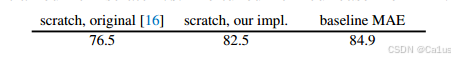
第一个原始论文中
第二个 自己实现的vit large
第三个 在自己实现方法的同时用上mae的自监督学习方法 做预训练微调
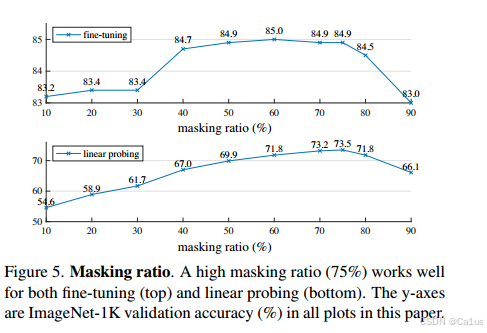
mask取不同比例的效果
上图:用完自监督学习(输入是图片,输出仍然是图片,训练编码器)训练完mae自监督任务之后,训练完编码器接上一个分类器,既微调encoder,也微调分类层mlp,整个分类模型都进行微调训练
(mask的比例达到4050的时候开始慢慢饱和)
下图:做完mae预训练之后固定住编码器,在输出端加mlp分类,只训练mlp部分不训练编码器部分,冻住编码器的参数,只训练mlp分类曾部分(训练参数少很多)
(分类准确率随着mask比例增长)
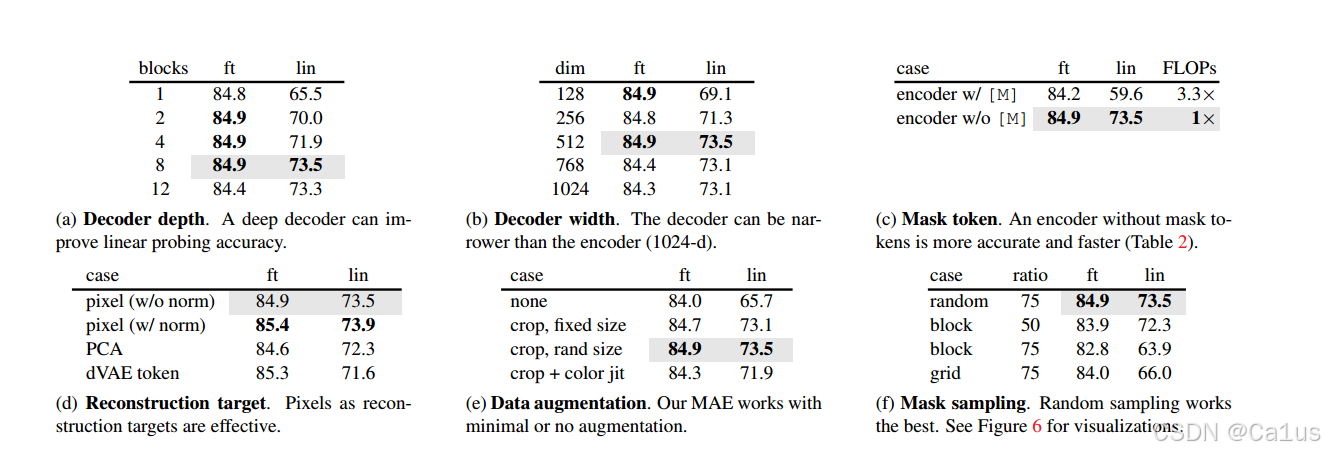
消融实验:
(a)解码器深度
ft:并不在意decoder的深度,几层差别不大
lin:只训练了分类层,比较在意解码器的深度,我们希望编码器在预训练阶段就学习到语义信息,
对于ft:即使在预训练阶段没有学习到比较抽象的语义信息,仍然可以微调整个编码器,使之适应分类任务。
(b)解码器宽度:每个transformer block的embedding的大小
lin:希望解码器更强大一点
(c)mask token
mae相比于之前的自监督学习的区别在去编码器不用接受mask token作为输入
上面接受 下面不接受(性能更好效率更高)
(d)采不采用做均值方差归一化 一个patch里算均值方差
把patch里所有像素减去均值除以标准差作为目标
(e)对数据增广的依赖性:证明MAE工作的好和数据增广是无关的
(f)mask的样式

















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









