







第一次完全自己动手写博文,起初有点不知所措,后来是有种深深的责任感,经过查阅了一些资料,才敢动笔,可能有些地方没有完全领悟到,期望各位同仁予以指正。
虽然在 池化总结(OverlappingPooling、 一般池化、Spatial Pyramid Pooling)一文中简单地介绍过金字塔池化(SPP),这次主要针对SPP实现原理和细节进行说明。本文主要基于Spatial Pyramid Pooling in Deep Convolutional Networ ks for Visual Recognition 这篇论文进行介绍,我觉得这篇论文把这金字塔池化(SPP)这个过程讲的很详细,感兴趣的可以阅读。
当前,深度卷积神经网络引发了计算机视觉和目标检测的革命,识别更加精确的新技术层出不穷,例如 dropout,data augment, modify activation function, 还有我们现在讲的SPP。这些主要从训练和测试着手以提升神经网络的性能。
一、卷积神经网络原理
Pooling是卷积神经网络的一个环节,对于刚接触CNN的读者,再看本文之前,建议先阅读下我另一篇博文——卷积神经网络原理,当然,这里也会简单的介绍下,算是我们共同温习下整个脉络,加深记忆吧!
1.1 神经元
Pooling神经网络由大量的节点(或称“神经元”、“单元”)和相互连接而成。每个神经元接受输入的线性组合,进行非线性变换(亦称激活函数activation function)后输出。每两个节点之间的连接代表加权值,称之为权重(weight)。不同的权重和激活函数,则会导致神经网络不同的输出。神经网络的每个神经元如下:

其中, a1~an为输入向量,当然,也常用x1~xn表示输入,w1~wn为权重,b为偏置bias,f 为激活函数,t 为输出。
事实上,在20世纪50/60年代,上述简单神经元被称之为感知机,可以把感知机理解为一个根据不同因素、以及各个因素的重要性程度而做决策的模型。
1.2 激活函数
常用的激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全链接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数,sigmoid的函数表达式如下:
其中 z是一个线性组合,比如z可以等于: w0+w1∗x1+w2∗x2。通过代入很大的正数或很小的负数到函数中可知, g(z)结果趋近于0或1。sigmoid函数的图形表示如下:

也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。输入非常大的正数时,输出结果会接近1,而输入非常大的负数时,则会得到接近0的结果。压缩至0到1有何用处呢?用处是这样一来变可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
1.3 神经网络
将1.1中的神经元多个以一定的结构组合在一起就形成神经网络。下图是一个三层的神经网络:

上图中最左边的原始输入信息称之为输入层,最右边的神经元称之为输出层(上图中输出层只有一个神经元),中间的叫隐藏层。 同时,每一层都可能由单个或多个神经元组成,每一层的输出将会作为下一层的输入数据。且同一层的神经元之间是没有连接的,上图是单隐层神经网络,深度神经网络又被称为多隐层神经网络,一般而言,神经网络的层数越多,网络达到的性能越好,但是总开销也会加大。
1.4 卷积神经网络结构
1962年Hubel和Wiesel通过对猫视觉皮层细胞的研究,提出了感受野(receptive field)的概念,1984年日本学者Fukushima基于感受野概念提出的神经认知机(neocognitron)可以看作是卷积神经网络的第一个实现网络,也是感受野概念在人工神经网络领域的首次应用。神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。
通常神经认知机包含两类神经元,即承担特征抽取的S-元和抗变形的C-元。S-元中涉及两个重要参数,即感受野与阈值参数,前者确定输入连接的数目,后者则控制对特征子模式的反应程度。
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
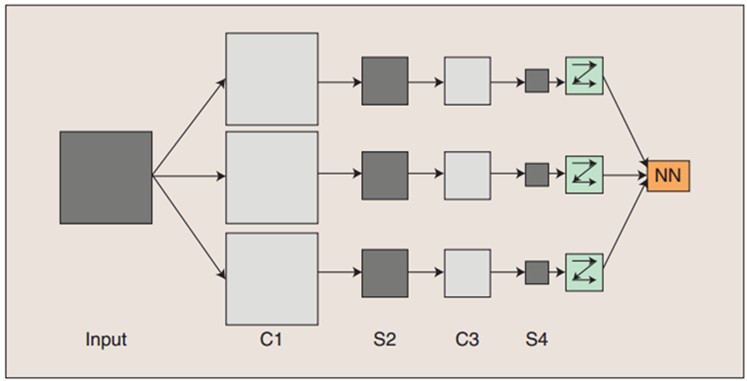
输入图像通过和三个可训练的滤波器和可加偏置进行卷积,滤波过程如图一,卷积后在C1层产生三个特征映射图,然后特征映射图中每组的四个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到三个S2层的特征映射图。这些映射图再进过滤波得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
一般地,C层为卷积层,每个神经元的输入与前一层的feature map相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层pooling层,网络的每个计算层由多个feature map组成,每个map为一个平面。这里pooling就是我们要讨论的重点。
二、Pooling
这里先举个例子说明池化的原理,如下图:

上方左侧特征矩阵的 20∗20要进行大小为 10∗10的池化,那么左侧图中的红色就是10*10的大小,对应到右侧的矩阵,右侧每个元素的值,是左侧红色矩阵每个元素的值得和再除以红色矩阵的元素个数,也就是平均值形式的池化。另外还有一种池化形式——max pooling,顾名思义就是对红色区域取最大值。
在我那篇博文中介绍了三种池化方式——一般池化,Over Pooling和Spatial Pyramid Pooling。上图展示就是一般的池化,我们可以发现,这里的窗口大小是等于步长的,即 win=stride=10。那Over Pooling的窗口 win>步长 stride的。
但是这两种池化对输入的不是固定大小的图片是不适应的。如前所述,一个卷积神经网络主要由两部分组成,卷积层(这里把Pooling当做是卷积层的一部分)和全连接层。实际上,卷积层不需要固定大小的输入,它也可以产生不同的输出大小不同的feature maps,但是全连接层必须是的输入的通道是固定的。所以为了保证输入图像有相同的固定的大小,我们一般通过crop和warp方法实现,但是这两种方法都会降低识别准确率,比如crop会损失部分图像信息,warp会扭曲图像。

2.1 Spatial Pyramid Pooling
由于以上种种原因,因此有学者提出将SPP应用到卷积神经网络中,下图的上部分是传统的CNN结构,下部分是应用了SPP池化CNN结构。这个卷积层可以接受任意大小的输入,但是经过SPP之后会产生固定大小的输出以适应全连接层,大小由SPP结构而定。

SPP的具体结构如下图所示:

对于这幅图来说,共采用了3种池化视图,分别是{ 4∗4, 2∗2, 1∗1},但是他们步长和窗口大小有输入图片决定。假设经过最后一层卷积得到的feature map的大小为 a∗a,我们想得到的池化视图大小为 n∗n,那么窗口 win=⌈an⌉,步长 stride=⌊an⌋。

这里,我们假设输入的map大小为 13∗13,这里的256表示的是map的个数,所以,SPP得到的输出的特征数量为 (4∗4+2∗2+1∗1)∗256=5376,不管最开始输入的图片多大,经SPP输出后的特征数量都为5376。
2.2 no SPP vs SPP
SPP 不仅使的任意大小的输入成为可能,而且还有效的提高了识别准确率。在Spatial Pyramid Pooling in Deep Convolutional Networ ks for Visual Recognition论文中,着重将no SPP-net与SPP-net进行了对比。
例如,作为计算机视觉系统识别项目, ImageNet目前世界上图像识别最大的数据库,作者用该数据集训练ZF-5,Convnet*-5,Overfeat-5和Overfeat-7,每个网络都有一般池化和SPP,最后结果表明,SPP-net能提高1%~2%的准确率。

作者在其它数据集上训练,结果都说明SPP-net性能较佳,此外总开销与no SPP-net相差无几。
SPP-net不仅在分类中表现出色,而且在目标检测中也具有强大的优势,除了提高Mean average precision之外,还大大减少了总的训练时间。















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









