






完整内容请看文末最后的推广群

基于自然语言处理的竞赛论文初步筛选系统
基于多模态分析的竞赛论文自动筛选与重复检测模型
摘要
随着大学生竞赛规模的不断扩大,参赛论文的数量激增,传统的人工筛选方法面临着工作量大、效率低且容易出错的问题。因此,利用计算机和人工智能技术对竞赛论文进行自动筛选成为一种有效的解决方案。该赛题的目标是通过设计数学模型和算法,实现竞赛论文的自动筛选,计算论文的重复率,检测文本、图片和公式的相似性,从而提高筛选效率、减少人工误差,并降低人工成本。
问题一主要关注从竞赛论文中提取基本信息(如标题、摘要、关键词等),以便为后续的筛选和评审提供基础数据。通过PDF提取工具( pdfplumber),自动化提取论文中的文本内容,并通过论文结构和正则化表达进行信息提取,如标题通常位于论文前几页,摘要、关键词等信息紧随其后, 并设计了针对图片、公式和代码的识别函数。该模型能够快速处理大量竞赛论文,自动提取关键信息。
问题二旨在根据论文的内容和格式进行筛选,检查是否包含有效的参赛队信息,判断论文是否与赛题相关,且是否具有实质性内容。通过文件名映射提取参赛队号,通过关键词匹配判断论文是否与赛题相关,并识别无实质内容的论文。
问题三的目标是检测论文之间的重复内容,包括文本的重复率、雷同图片和雷同公式。通过提取文本内容,使用TF-IDF和余弦相似度计算论文之间的文本相似度;对于图片和公式,使用感知哈希和哈希值比较的方法来判断图片和公式是否雷同。该模型通过结合文本、图片和公式的相似度,能够全面检测论文中的重复内容。在文本检测方面,余弦相似度和TF-IDF方法能够有效衡量文本的相似性。图片和公式的检测通过感知哈希和哈希值比较,表现良好。
问题四的目的是检测高图片占比的PDF文件,并分析其与其他文档的重复情况。通过计算图片在页面中的占比来判断是否为高图片占比的论文,并结合OCR技术提取图片中的文字内容来提高图文结合的相似度计算。该模型能够有效识别高图片占比的PDF,并对其进行重复率分析。通过计算每一页的图片占比并进行平均,可以准确识别图片占比较高的文档。使用OCR技术提取图片中的文字,有助于提高图文结合相似度的计算精度。
模型有效地实现了自动化的竞赛论文筛选与分析,极大地提升了论文评审的效率。未来可以考虑通过进一步优化算法、增强模型的鲁棒性,来解决这些问题。此外,模型的计算消耗较大,尤其是在处理大规模数据时,需要高效的计算资源和优化策略。
关键词:余弦相似度; 感知哈希; OCR技术; 多模态分析; 竞赛评审; pdfplumber; 正则化表达
目录
摘要 1
一、 问题重述 4
1.1 问题背景 4
1.2 要解决的问题 4
二、 问题分析 6
2.1 任务一的分析 6
2.2 任务二的分析 6
2.3 任务三的分析 7
2.4 任务四的分析 7
三、 问题假设 9
四、 模型原理 10
4.1 关键词识别 10
4.2 中文文本分析 11
4.3 相关性分析 11
五、 模型建立与求解 13
5.1 问题一建模与求解 13
5.2问题二建模与求解 18
5.3问题三建模与求解 21
5.4问题四建模与求解 25
六、 模型评价与推广 29
6.1模型的评价 29
6.1.1模型缺点 29
6.1.2模型缺点 29
6.2 模型推广 30
七、 参考文献 31
附录【自行黏贴】 32
二、 问题分析
2.1任务一的分析
针对问题一,论文的初步筛选与评审工作通常需要涉及对论文的基本信息进行提取和统计,包括论文的标题、作者、摘要、关键词等内容。对于大量的竞赛论文而言,手动提取这些信息显然是不切实际的,因此需要自动化的手段来完成这些任务。问题一的核心目标是设计一个自动化的系统,通过程序从PDF格式的论文中提取相关信息,为后续的筛选和评审提供基础数据。
具体来说,论文的标题和摘要通常位于论文的前几页,是论文的关键部分。作者和关键词可能出现在标题之后或其他部分。为了准确提取这些内容,需要假设每篇论文都有类似的结构,并且可以通过正则表达式或关键词匹配来识别这些部分。文本的提取也依赖于PDF的结构,如果文件的排版或内容较复杂,提取的准确性可能受到影响。
此外,提取公式和图片的工作同样需要自动化完成。公式通常以数学符号和特定的格式(如
.
.
.
...
... 或 […])出现,图片则嵌入在文本中。需要对每一页进行遍历和分析,提取有效的公式和图片内容。
2.2任务二的分析
问题二的目的是对论文进行筛选,确保论文与赛题相关并且具有实质内容。具体任务包括三个方面:首先,需要确认论文是否包含有效的参赛队信息;其次,需要判断论文内容是否与赛题相关;最后,评估论文是否具有实质性内容,避免出现大量无意义的内容,如致谢、附录和参考文献等。
第一步是检查参赛队信息,这一任务通过查看文件名中的加密号并将其与参赛队号映射表进行匹配来完成。若匹配成功,则认为该论文包含有效的参赛队信息。
第二步是判断论文内容与赛题的相关性。为此,需要提取论文正文部分并通过关键词匹配方法来判断论文是否与赛题相关。赛题的相关关键词已给出,因此可以通过在文本中查找这些关键词来识别与赛题相关或无关的论文。
最后,第三步是检查论文的实质性内容。很多论文可能在正文中包含大量无实际内容的段落,例如致谢、附录、代码实现等部分。通过检测正文内容的有效性以及是否含有这些无关段落,能够筛选出不符合要求的论文。
2.3任务三的分析
问题三的核心目标是通过自动化手段检测竞赛论文中的重复内容,具体包括计算文本的重复率、检测雷同的图片以及雷同的公式。随着论文数量的增多,检测论文中是否存在抄袭或雷同内容变得尤为重要。
首先,文本重复率的计算基于文本相似度的分析。通过提取每篇论文的正文文本,并将其转化为TF-IDF向量,利用余弦相似度来衡量不同论文之间的文本相似度。通过计算每篇论文与其他论文的相似度,可以得出每篇论文的重复率。
其次,雷同图片的检测依赖于图片的感知哈希技术。通过提取论文中的图片并计算其哈希值,利用哈希值之间的差异来判断图片是否雷同。感知哈希是一种能够有效识别图片相似度的方法,尤其是在图片做了细微修改时,依然能够识别出相似内容。
最后,雷同公式的检测同样使用哈希技术。通过提取公式并计算其哈希值,比较不同论文中的公式,判断是否存在雷同公式。公式的格式一般具有较强的规律性,因此通过哈希值可以准确地检测出相似或相同的公式。
2.4任务四的分析
问题四的目标是通过分析PDF文件中的图片占比来识别是否为高图片占比的文档,并进一步分析其与其他文档的重复情况。高图片占比PDF常常包含大量无关或无实际内容的图片,这些图片可能是装饰性的或者与论文主题无关。因此,识别这种类型的PDF文件对于竞赛论文的筛选具有重要意义。
首先,图片占比的计算基于页面的总面积和图片的面积,通过计算图片在页面中所占的比例来判断是否为高图片占比PDF。若该比例超过设定的阈值(如30%),则该PDF被认为是高图片占比。
接下来,使用OCR技术提取图片中的文字内容。OCR(光学字符识别)可以从图片中提取出有用的文字信息,帮助进一步分析图片的内容。对于有文字内容的图片,OCR可以提升其在相似度计算中的作用。
最后,进行多模态相似度分析,即结合文本和图片的相似度来评估论文之间的相似度。通过对论文的文本部分和图片部分分别计算相似度,并结合两者的信息来综合评定论文的重复率。综合相似度将文本和图片的相似度进行加权合并,得到更为准确的重复率结果。
问题一结果
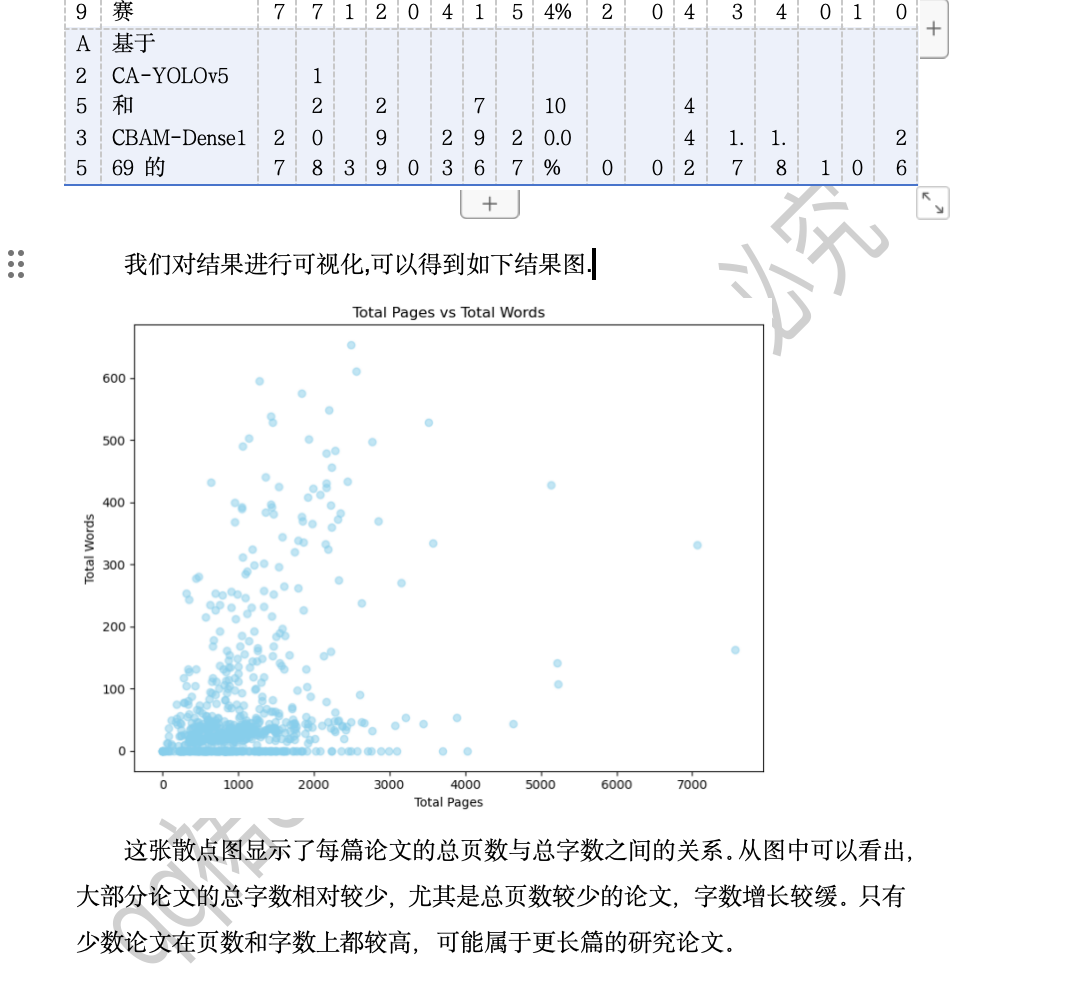
问题二结果
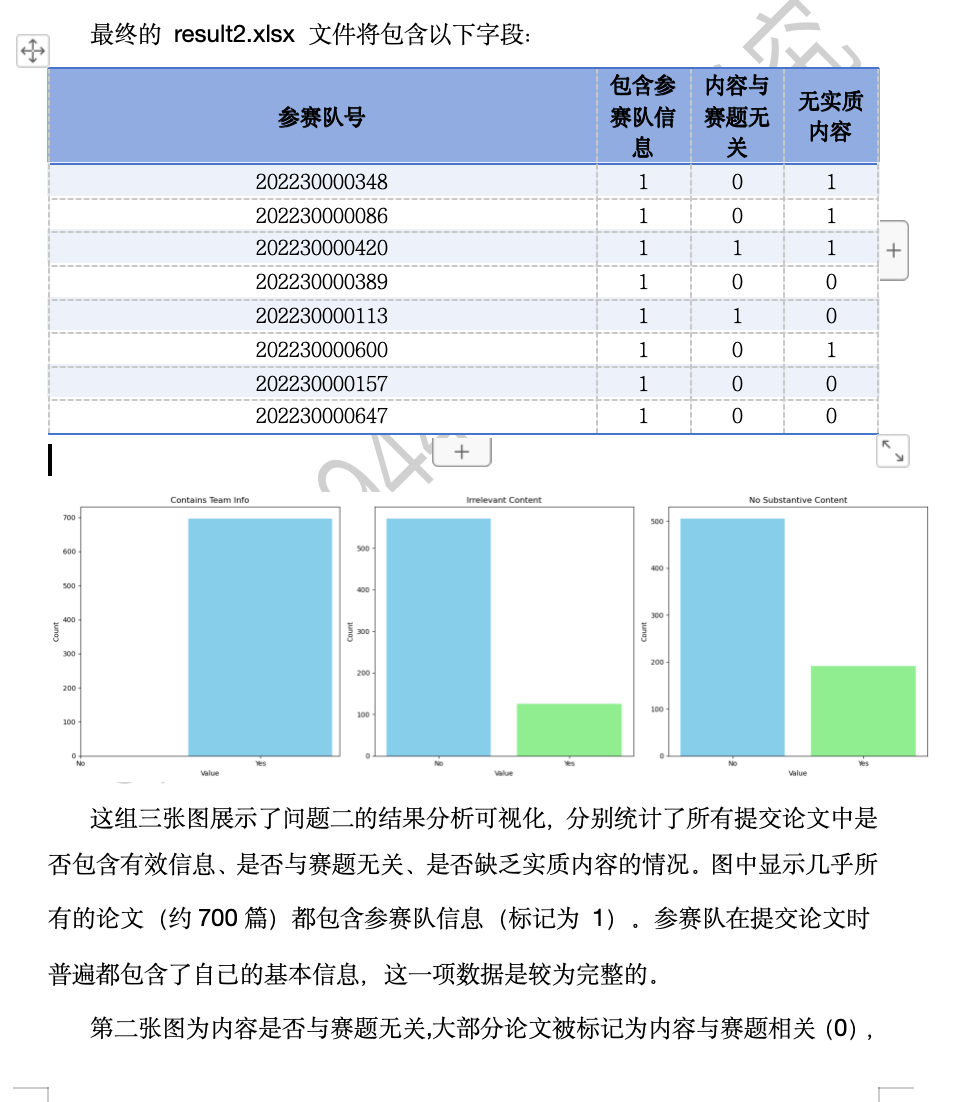
问题三结果
我们首先需要计算竞赛论文之间的文本相似度,衡量文本的重复率。该过程使用 余弦相似度 方法,计算每篇论文与其他论文的相似度,并得到最大相似度作为论文的重复率。基于pdfminer函数从PDF文件中提取出每篇论文的正文内容,排除参考文献、附录等部分。使用 TF-IDF(词频-逆文档频率)对每篇论文的文本进行向量化,将每篇论文表示为一个向量。TF-IDF 是衡量单词在文本中的重要性的常用方法。使用 余弦相似度(Cosine Similarity) 计算两篇文本的相似度,公式如下:
其中,( A ) 和 ( B ) 是文本的TF-IDF向量,( A \cdot B ) 是向量的内积,( |A| ) 和 ( |B| ) 是向量的模。
对于每篇论文 ( i ),计算它与其他论文的最大相似度,作为该论文的重复率。若论文 ( i ) 与论文 ( j ) 的相似度最大,则该论文的重复率 ( R_i ) 可以表示为:
对于每篇论文 ( i ),其重复率 ( R_i ) 计算公式为:
其中 ( A_i ) 和 ( A_j ) 是第 ( i ) 和第 ( j ) 篇论文的 TF-IDF 向量。
接着我们需要检测论文中的雷同图片,检查不同的论文是否使用了相同或相似的图片。为此,我们使用 感知哈希算法 来计算图片的哈希值,并比较图片之间的相似度。
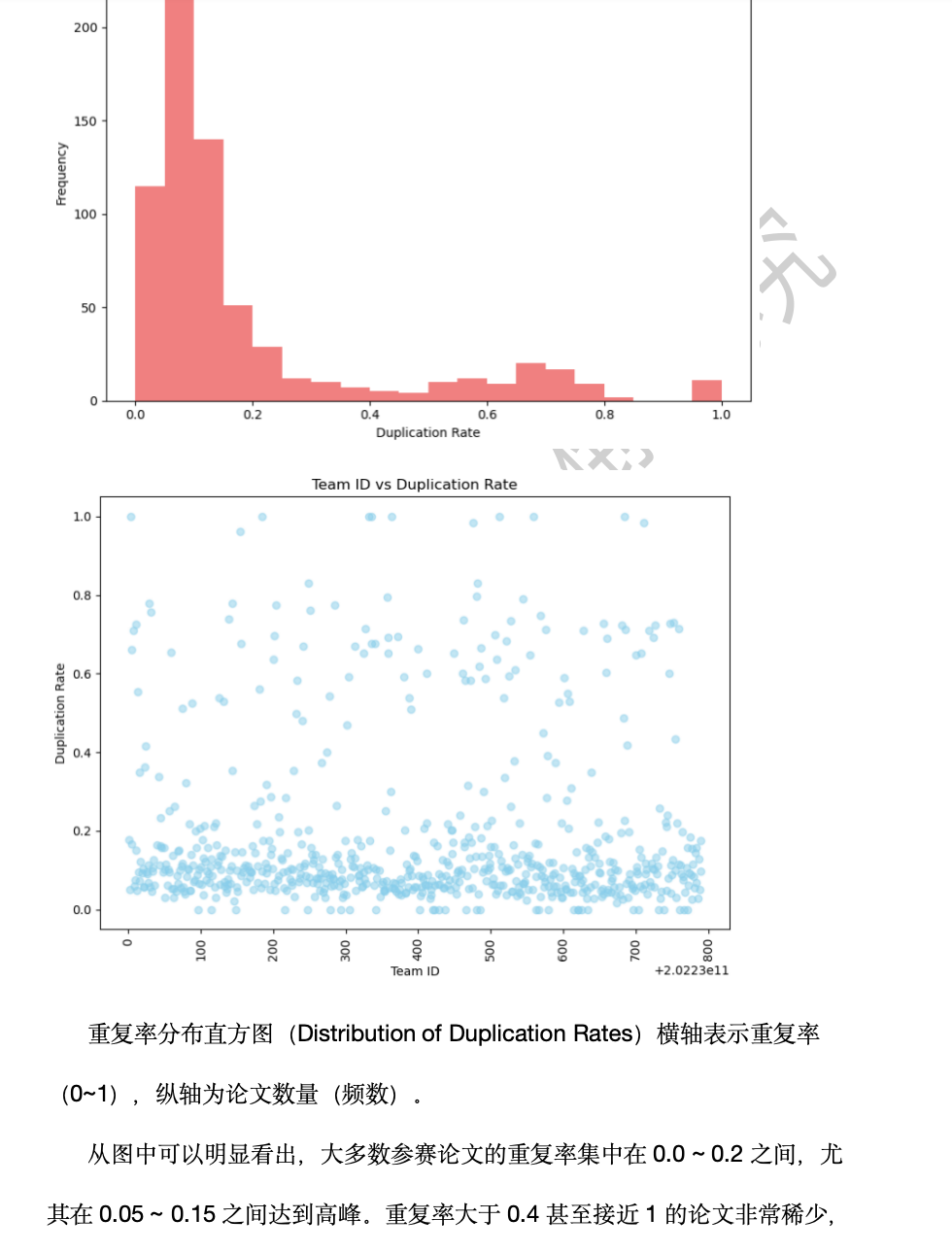
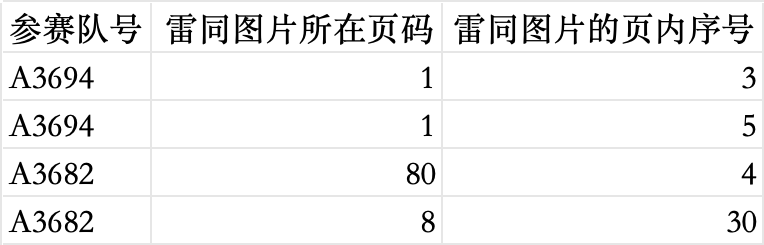
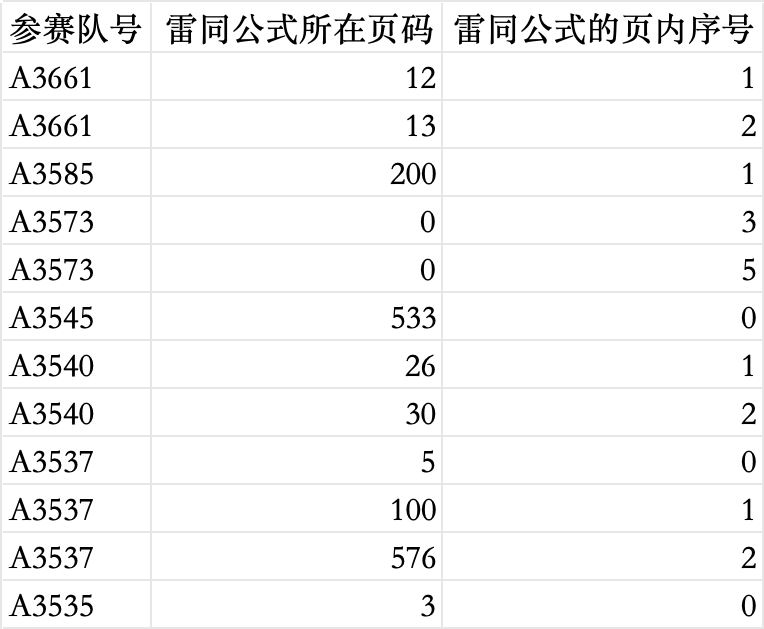
问题四结果
同时通过 pytesseract OCR技术提取图片中的文字信息。对于每张图片,计算其特征向量,使用 标准化处理(将图片转换为灰度图像并调整大小)来提取图片的特征向量,用于后续的图片相似度分析。
对于每一张图片,使用 感知哈希(Perceptual Hash) 来提取其特征向量。感知哈希的计算公式为:
其中 h§ 是图片 p 的感知哈希值,表示图片的特征。
我们需要综合文本和图片信息,计算每篇论文的相似度。为此,我们首先计算文本之间的余弦相似度,然后计算图片之间的相似度,最后将两者的相似度结合得到综合相似度。
对每篇论文的正文内容进行 TF-IDF 向量化,并计算余弦相似度。余弦相似度公式如下:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









