







预览,详细内容请看文末或主页简介:
代码:
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import pandas as pd
import numpy as np
from datetime import datetime
# # 数据预处理
# In[2]:
# 加载数据
medals_df = pd.read_csv('./2025_Problem_C_Data/summerOly_medal_counts.csv', encoding='ISO-8859-1')
hosts_df = pd.read_csv('./2025_Problem_C_Data/summerOly_hosts.csv')
programs_df = pd.read_csv('./2025_Problem_C_Data/summerOly_programs.csv', encoding='ISO-8859-1')
athletes_df = pd.read_csv('./2025_Problem_C_Data/summerOly_athletes.csv', encoding='ISO-8859-1')
# 查看数据结构,确保正确加载
print(medals_df.head())
print(hosts_df.head())
print(programs_df.head())
print(athletes_df.head())
# In[3]:
# 检查缺失值
print(medals_df.isnull().sum())
print(hosts_df.isnull().sum())
print(programs_df.isnull().sum())
print(athletes_df.isnull().sum())
# In[5]:
# 将年份列转换为整数类型
medals_df['Year'] = medals_df['Year'].astype(int)
hosts_df['Year'] = hosts_df['Year'].astype(int)
athletes_df['Year'] = athletes_df['Year'].astype(int)
# 将奖牌数量转换为整数类型
medals_df['Gold'] = medals_df['Gold'].astype(int)
medals_df['Silver'] = medals_df['Silver'].astype(int)
medals_df['Bronze'] = medals_df['Bronze'].astype(int)
medals_df['Total'] = medals_df['Total'].astype(int)
# In[6]:
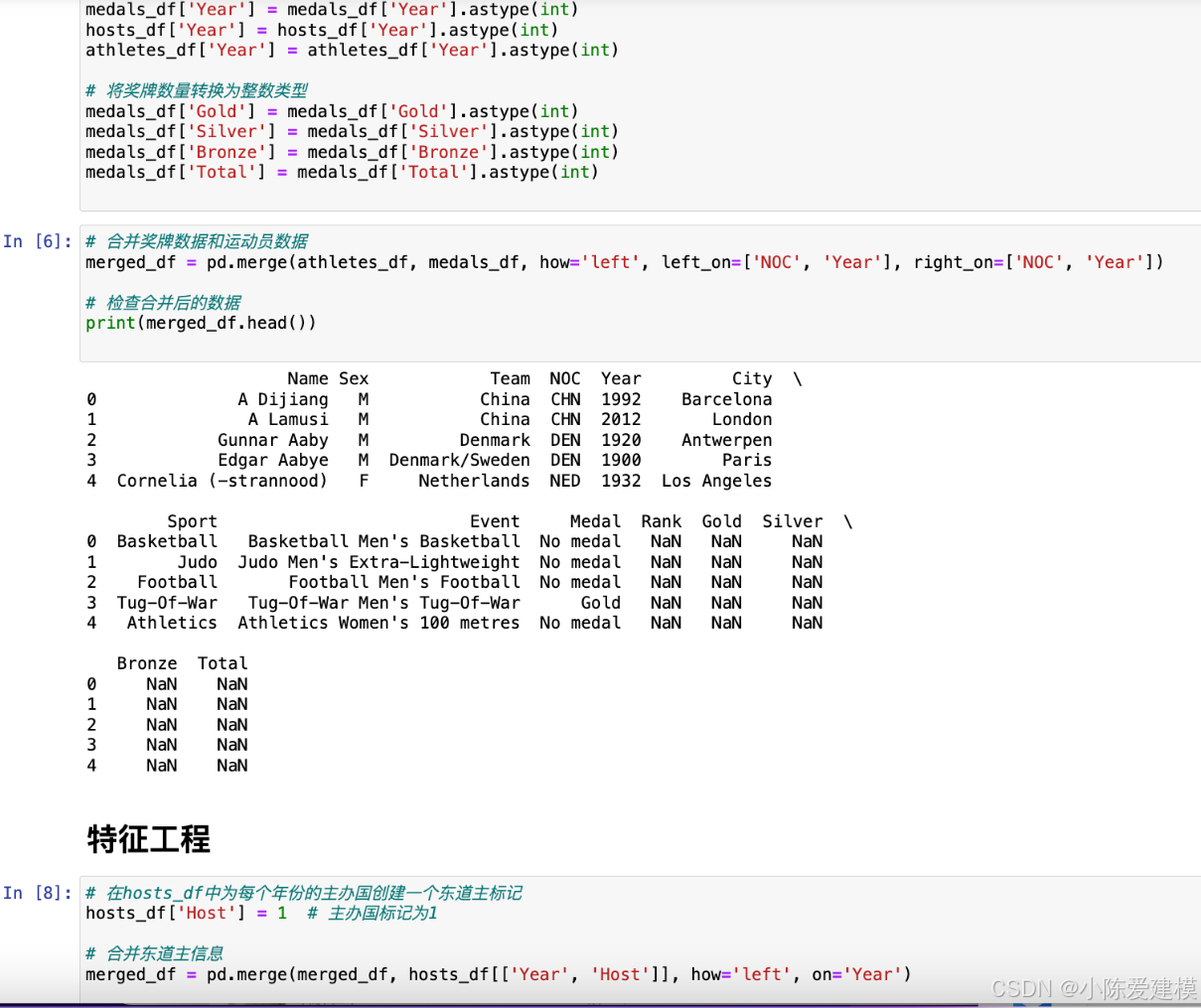
# 合并奖牌数据和运动员数据
merged_df = pd.merge(athletes_df, medals_df, how='left', left_on=['NOC', 'Year'], right_on=['NOC', 'Year'])
# 检查合并后的数据
print(merged_df.head())
# # 特征工程
# In[8]:
# 在hosts_df中为每个年份的主办国创建一个东道主标记
hosts_df['Host'] = 1 # 主办国标记为1
# 合并东道主信息
merged_df = pd.merge(merged_df, hosts_df[['Year', 'Host']], how='left', on='Year')
# 如果没有主办国信息,则填充为0(不是东道主)
merged_df['Host'].fillna(0, inplace=True)
# 检查更新后的数据
print(merged_df.head())
# In[9]:
# 为运动员创建一个新的列,表示奖牌类型
merged_df['Medal_Type'] = np.where(merged_df['Medal'] == 'Gold', 'Gold',
np.where(merged_df['Medal'] == 'Silver', 'Silver',
np.where(merged_df['Medal'] == 'Bronze', 'Bronze', 'No Medal')))
# 检查创建的奖牌类型列
print(merged_df[['Name', 'Medal_Type']].head())
# In[11]:
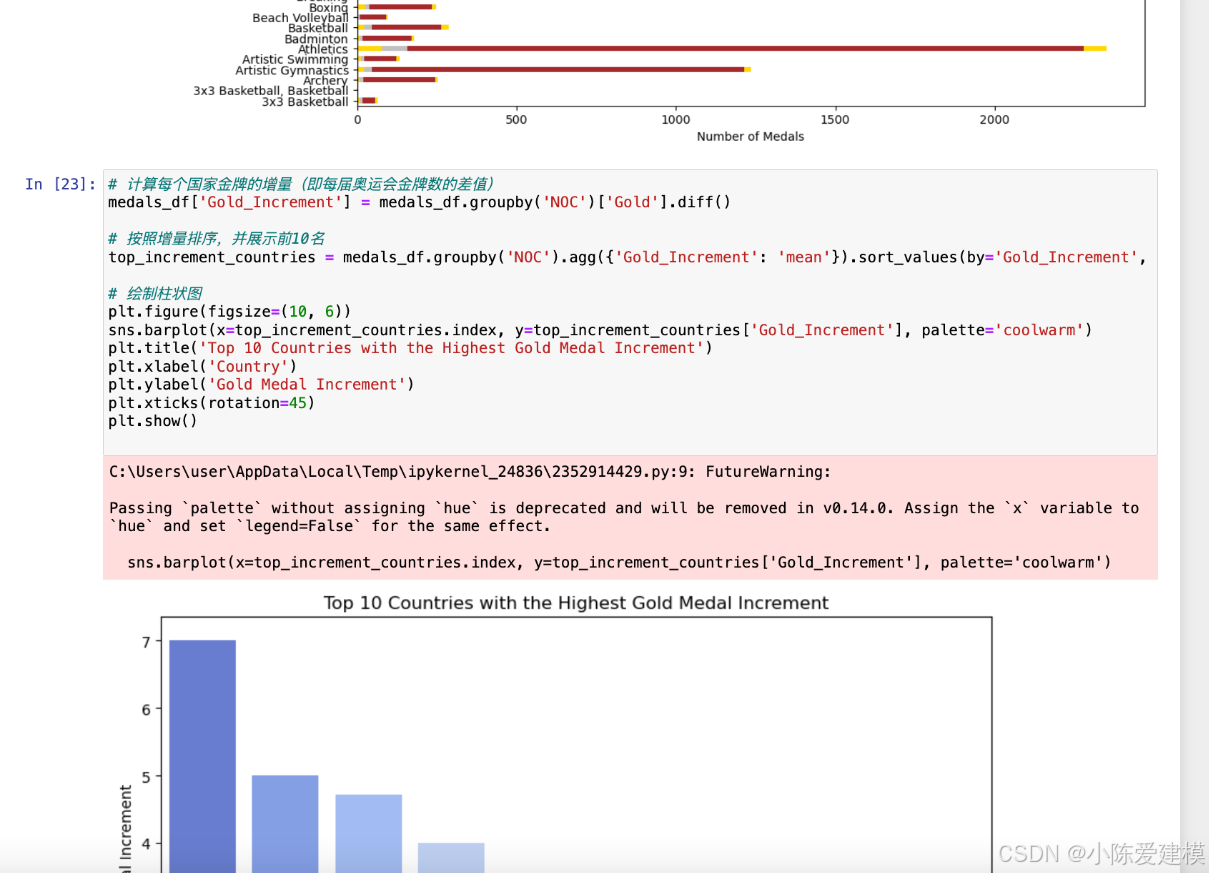
# 计算国家的奖牌增速(例如金牌数量变化)
medals_df['Gold_Change'] = medals_df.groupby('NOC')['Gold'].pct_change() # 使用百分比变化
# 如果是首次参加奥运会,设置增速为0
medals_df['Gold_Change'].fillna(0, inplace=True)
# 检查添加的增速特征
print(medals_df[['NOC', 'Year', 'Gold_Change']].head())
# In[ ]:
# # 保存清洗后的数据
# merged_df.to_csv('cleaned_olympic_data.csv', index=False)
# In[12]:
import matplotlib.pyplot as plt
import seaborn as sns
# 假设我们分析的是2024年奥运会金牌数量的排名
year = 2024
top_n = 20 # 显示排名前20的国家
# 筛选数据
medals_2024 = medals_df[medals_df['Year'] == year]
medals_2024_sorted = medals_2024.sort_values(by='Gold', ascending=False).head(top_n)
# 绘制条形图
plt.figure(figsize=(10, 6))
sns.barplot(x='Gold', y='NOC', data=medals_2024_sorted, palette='viridis')
plt.title(f'Top {top_n} Countries by Gold Medals in {year} Olympics')
plt.xlabel('Gold Medals')
plt.ylabel('Country')
plt.show()
# In[13]:
# 假设我们分析的是2024年奥运会的奖牌分布
medals_2024 = medals_df[medals_df['Year'] == 2024]
medals_2024_sorted = medals_2024.sort_values(by='Total', ascending=False).head(top_n)
# 堆叠条形图,显示金、银、铜奖牌比例
fig, ax = plt.subplots(figsize=(10, 6))
medals_2024_sorted.set_index('NOC')[['Gold', 'Silver', 'Bronze']].plot(kind='barh', stacked=True, ax=ax, color=['gold', 'silver', 'brown'])
plt.title(f'Top {top_n} Countries by Medal Count in {year} Olympics')
plt.xlabel('Number of Medals')
plt.ylabel('Country')
plt.show()
# In[15]:
# 假设我们分析的是某个国家(例如美国)的奖牌数量变化趋势
country = 'United States'
# 筛选数据
usa_medals = medals_df[medals_df['NOC'] == country]
# 绘制折线图
plt.figure(figsize=(10, 6))
plt.plot(usa_medals['Year'], usa_medals['Gold'], label='Gold', marker='o')
plt.plot(usa_medals['Year'], usa_medals['Total'], label='Total Medals', marker='o')
plt.title(f'{country} Medal Trend Over Time')
plt.xlabel('Year')
plt.ylabel('Number of Medals')
plt.legend()
plt.grid(True)
plt.show()
# In[17]:
# 假设我们分析的是2024年奥运会的不同项目奖牌分布
year = 2024
projects = merged_df[merged_df['Year'] == year]
# 绘制堆叠条形图
project_medals.plot(kind='barh', stacked=True, figsize=(12, 8), color=['gold', 'silver', 'brown'])
plt.title(f'Medal Distribution by Sport in {year} Olympics')
plt.xlabel('Number of Medals')
plt.ylabel('Sport')
plt.show()
背景讲解:
奥林匹克运动会(
Olympic Games
)自
1896
年开始举办,已经成为全球最具影响力的体育盛会之一。每四年一次的夏季奥运会吸引了来自世界各地的顶尖运动员参赛,奖牌榜也成为全球关注的焦点。每个国家的表现不仅代表着该国的体育实力,也反映了各国对体育事业的投入和发展水平。
在奥运会中,奖牌的数量通常是评价各国运动水平的重要指标。奥运奖牌分为金牌、银牌和铜牌,每种奖牌的数量决定了一个国家在奥运历史上的成绩排名。不同国家在奥运会上的表现受到多个因素的影响,包括历史成绩、运动员的水平、体育设施和投资、文化背景、主办国的影响等。
随着全球化进程的推进,越来越多的国家在奥运会的奖牌榜上有所突破,特别是一些曾经未曾取得奖牌的国家,逐渐通过增加体育投资、培养运动员、强化国际合作等手段逐步提升了自己的表现。同时,奥运会的项目种类和竞赛形式不断变化,这也影响了各国在不同项目中的表现。例如,一些国家在特定项目中占据优势(如中国在乒乓球和羽毛球方面的优势),而其他国家则在其他项目中表现突出(如美国在游泳和田径中的优势)。
数据背景和要求
2024
年巴黎奥运会奖牌数据:
奖牌表:奥运会的奖牌表通常按照金牌数、银牌数和铜牌数排序。
2024
年巴黎奥运会的奖牌榜上,美国、中华人民共和国和日本等国家排名靠前,其中美国和中国的金牌数并列第一(
40
枚金牌)。
各国表现差异:虽然一些传统强国(如美国和中国)在金牌和总奖牌数上占据优势,但许多其他国家也在某些领域取得了突破。例如,法国是
2024
年巴黎奥运会的东道主,尽管金牌数排名第五,但在总奖牌数上排名第四。英国也尽管金牌数不高(
14
枚金牌),但在总奖牌数上排名第三。
奥运历史数据:
历史奖牌数据:题目提供了
1896
年至
2024
年所有夏季奥运会的奖牌数据,包括各国在每届奥运会中的金牌、银牌、铜牌的数量。这些历史数据不仅可以帮助分析各国的长期表现趋势,还能揭示各国奖牌数变化的规律。
主办国的影响:每届奥运会的主办国通常会因主场作战而有所表现提升。数据中也有主办国的信息,可以帮助分析主办国如何影响奖牌数量。
体育项目数据:
奥运项目数量:每届奥运会的比赛项目数量会有所不同,这直接影响到各国的表现机会。题目要求分析项目数量和种类如何影响各国的奖牌数量。
模型分析和任务要求
奖牌预测模型:
目标:开发一个预测模型,根据历史奖牌数据、项目数量和类型等因素预测每个国家在
2028
年洛杉矶夏季奥运会中的奖牌数。
预测内容:预测金牌数量、总奖牌数量,并给出预测区间。模型还需要考虑未来可能新加入的体育项目以及各国运动员的表现。
不确定性和精度:
目标:在预测过程中,需要对模型的不确定性和预测精度进行评估。对于每个国家,给出奖牌预测的置信区间或预测区间。
统计方法:可以使用回归分析、时间序列分析、贝叶斯方法等进行建模,并通过交叉验证和误差分析评估模型的可靠性。
教练效应分析:
目标:分析教练变动是否对某些国家的表现产生影响,特别是一些著名教练如
Lang Ping
和
Béla Károlyi
曾在不同国家执教并取得成功的案例。
方法:检查历史数据,识别教练变动与奖牌数之间的关联。基于这些数据,估算教练效应对奖牌数的贡献。
首次获奖的国家预测:
目标:预测哪些从未获得过奥运奖牌的国家将在
2028
年洛杉矶奥运会上首次获得奖牌。
方法:分析这些国家的历史表现、体育投资情况、运动员的实力等因素,给出首次获奖的预测及其概率。
体育项目与奖牌数的关系:
目标:探索奥运会的不同体育项目对各国奖牌数的影响。某些项目可能对特定国家更为重要(如美国的游泳,肯尼亚的长跑)。
分析:使用数据分析技术,探索各国在哪些项目上表现较强,哪些项目对他们的奖牌总数贡献最大。
任务目标和最终目标
通过建立数学模型,预测
2028
年奥运会的奖牌表,并评估不同国家在未来奥运会中的表现变化。
在此过程中,结合历史数据、体育项目、主办国效应、教练影响等因素,提供对未来奥运会表现的深入分析。
结果将为各国奥委会提供策略建议,帮助他们优化奥运备战计划和体育资源分配。
结论
此题要求运用统计学、数据分析和建模技巧,结合历史数据,预测
2028
年洛杉矶夏季奥运会奖牌表,并深入分析不同因素对奖牌数的影响。通过对奥运历史数据、体育项目、教练变动等方面的分析,旨在为未来的奥运备战提供理论支持和数据依据。
如果需要进一步分析或帮助,或者对模型的具体实现有任何问题,随时告诉我!
问题一:奖牌预测模型的建立
这个问题要求我们建立一个模型来预测
2028
年洛杉矶奥运会各国的奖牌数,特别是金牌和总奖牌数。这个模型应该利用过去的奥运数据,包括各国的历史奖牌数、项目数和类型,以及其他可能影响奖牌数的因素(如主办国效应、教练效应等)。
建模思路
确定建模目标
我们需要构建一个预测模型,能够:
预测各国在
2028
年奥运会的奖牌数量,尤其是金牌和总奖牌数。
评估模型的不确定性,提供预测区间(即置信区间或预测区间)。
分析哪些国家可能在
2028
年表现优异,哪些国家的表现可能下降。
数据收集与预处理
为了构建有效的预测模型,我们需要以下几类数据:
历史奖牌数据:所有夏季奥运会的数据,包括
1896
年至
2024
年每个国家的奖牌数量(包括金、银、铜)。
奥运项目数据:每届奥运会的项目数量和种类,帮助分析不同项目对各国表现的影响。
主办国信息:每届奥运会的主办国数据,考虑主办国对奖牌数量的潜在影响。
国家特征数据:国家的人口、经济状况、体育投入、运动员数量等,这些可能会影响国家在奥运会上的表现。
运动员和教练数据:教练对国家奖牌数的影响,尤其是名教练跨国执教的情况。
我们需要清理数据,去除重复项,处理缺失数据,并将数据标准化,使其适合模型训练。
模型选择
根据任务要求,我们可以使用以下几种建模方法:
(1)
线性回归模型
我们可以从每个国家的历史奖牌数(包括金牌和总奖牌数)出发,构建一个线性回归模型。具体步骤如下:
特征变量:
国家在过去几届奥运会中的奖牌数。
每个国家的体育项目数量和类别(影响其获得奖牌的机会)。
每届奥运会的项目变化(新项目的加入可能影响奖牌分布)。
主办国效应(主办国通常在主场表现较好)。
各国的体育投入、经济发展水平、运动员人数等。
模型公式:
对于金牌数的预测,我们可以构建以下回归模型:
G2028=β0+β1⋅Ghistory+β2⋅Pevents+β3⋅Phost+β4⋅Cinvestment+ϵG_{\text{2028}} = \beta_0 + \beta_1 \cdot G_{\text{history}} + \beta_2 \cdot P_{\text{events}} + \beta_3 \cdot P_{\text{host}} + \beta_4 \cdot C_{\text{investment}} + \epsilon
其中:
G2028G_{\text{2028}}
是
2028
年奥运会的金牌预测值。
GhistoryG_{\text{history}}
是该国在历史奥运会中的金牌数。
PeventsP_{\text{events}}
是该届奥运会的项目数量。
PhostP_{\text{host}}
是主办国的标识变量(
1
表示主办国,
0
表示非主办国)。
CinvestmentC_{\text{investment}}
是国家的体育投入(可以通过年度预算、运动员数量等来衡量)。
ϵ\epsilon
是误差项。
对于总奖牌数,也可以构建类似的回归模型。
(2)
时间序列模型
如果奖牌数随时间的变化趋势显著(例如某些国家在每届奥运会后表现持续增长或下降),可以考虑使用时间序列分析方法,如
ARIMA
模型。通过历史数据预测未来奖牌数,并将这些预测值作为模型的输入。
时间序列建模:对每个国家的历史金牌和总奖牌数进行
ARIMA
建模,分析奖牌数量的时间趋势。
模型公式:
Yt=ϕ1⋅Yt−1+ϕ2⋅Yt−2+…+ϵtY_t = \phi_1 \cdot Y_{t-1} + \phi_2 \cdot Y_{t-2} + … + \epsilon_t
其中,
YtY_t
是某年(如
2028
年)的金牌数或总奖牌数,
ϕ1,ϕ2\phi_1, \phi_2
是回归系数,
ϵt\epsilon_t
是误差项。
(3)
贝叶斯回归模型
贝叶斯方法通过引入先验分布来处理数据中的不确定性,适用于有不确定性的预测任务。贝叶斯回归模型可以用来估计奖牌数的分布,并提供预测区间(而不是单一的点估计)。
贝叶斯模型:
使用贝叶斯推断来进行奖牌数的预测,考虑到每个国家的历史数据、项目数量、主办国效应等因素。
通过
MCMC
方法(马尔科夫链蒙特卡洛)进行参数的采样,获得奖牌数的后验分布。
计算预测的置信区间和预测区间。
(4)
机器学习方法
如果数据的复杂度较高,我们还可以使用一些机器学习方法,如随机森林(
Random Forests
)、梯度提升机(
XGBoost
)等,通过特征选择、模型训练和交叉验证来预测奖牌数。
模型评估与验证
为了评估模型的表现,我们可以使用以下方法:
交叉验证:将数据分成训练集和测试集,通过交叉验证评估模型的性能,避免过拟合。
误差分析:计算模型的均方误差(
MSE
)、平均绝对误差(
MAE
)等指标,评估模型的精度。
置信区间
/
预测区间:给出奖牌数预测的置信区间或预测区间,体现模型的不确定性。
预测
2028
年奥运会的奖牌数
使用训练好的模型,基于历史数据、项目数量、主办国等因素,预测
2028
年洛杉矶奥运会各国的金牌数和总奖牌数。
预测输出:每个国家的金牌数、银牌数、铜牌数以及总奖牌数。
不确定性估计:给出预测区间,例如
“
美国将在
2028
年获得
38
到
42
枚金牌
”
。
国家表现趋势分析
根据模型预测的结果,可以进一步分析哪些国家在
2028
年有可能表现得更好,哪些国家可能会有所下滑。这个分析可以基于各国的历史表现、经济水平、体育投入等因素。
尚未获得奖牌的国家预测
最后,模型还应该预测哪些尚未获得奥运奖牌的国家可能在
2028
年首次获得奖牌。这一部分的预测可以基于这些国家的运动员培养、经济投入等因素。
如果选择使用
**
梯度提升机(
XGBoost
)
**
来建立预测模型,
XGBoost
是一种强大的机器学习方法,特别适用于结构化数据的预测。它通过结合多个决策树来提高模型的准确性,并且具有高效性和较好的预测性能。基于
XGBoost
的初始模型,我们可以进行一些进阶的修正和优化,以提高模型的准确性、鲁棒性以及解释性。
梯度提升机(
XGBoost
)模型的基本结构
XGBoost
模型的基本思想是通过逐步添加新的决策树来优化预测结果,每棵树都尝试纠正前一棵树的错误。这种方法通常表现出较强的泛化能力,可以通过调整超参数来减少过拟合并提高性能。
XGBoost
的基本流程:
数据预处理:处理缺失值、异常值和数据类型转换。
特征选择:选择影响奖牌数的特征(如历史奖牌数、体育项目数量、主办国标识等)。
训练
XGBoost
模型:使用历史数据训练
XGBoost
模型。
评估与预测:使用交叉验证、误差分析等评估模型,生成预测结果。
进阶修正模型的改进方法
(1)
超参数调优
XGBoost
有许多超参数可以调整,这些超参数对于模型的性能至关重要。通过优化这些超参数,可以显著提高模型的预测精度。
常见的
XGBoost
超参数包括:
学习率(
learning_rate
或
eta
):控制每棵树对最终预测结果的贡献。较低的学习率通常需要更多的树。
树的数量(
n_estimators
):即模型中决策树的数量。增加树的数量可以提升模型的复杂性和拟合度,但可能会导致过拟合。
树的最大深度(
max_depth
):控制每棵树的深度,越大越容易导致过拟合。
子样本比率(
subsample
):每棵树训练时随机选择的样本比例。设置为
0.8
表示每棵树使用
80%
的数据进行训练。
特征列随机选择(
colsample_bytree
、
colsample_bylevel
):控制每棵树在训练时随机选择的特征列比例。
L1
(
Lasso
)正则化(
alpha
)和
L2
(
Ridge
)正则化(
lambda
):用于控制模型复杂度,防止过拟合。
调优方法:
网格搜索(
Grid Search
):通过遍历超参数空间,找到最佳的超参数组合。
随机搜索(
Randomized Search
):与网格搜索类似,但随机选择超参数组合,通常效率更高。
贝叶斯优化(
Bayesian Optimization
):通过优化算法来寻找最佳的超参数组合。
from sklearn.model_selection import GridSearchCV
from xgboost import XGBRegressor
假设数据已经处理好并且划分为训练集和测试集
model = XGBRegressor(objective=‘reg:squarederror’)
定义超参数空间
param_grid = {
‘learning_rate’: [0.01, 0.1, 0.2],
‘n_estimators’: [100, 200, 300],
‘max_depth’: [3, 5, 7],
‘subsample’: [0.7, 0.8, 0.9],
‘colsample_bytree’: [0.7, 0.8, 0.9]
}
网格搜索
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
最佳超参数
print(grid_search.best_params_)
(2)
特征工程与选择
特征选择和工程对于提升
XGBoost
模型的性能至关重要。为了提高模型的准确性,特别是与奥运奖牌预测相关的特征,我们可以尝试以下几种策略:
历史表现特征:包括每个国家过去的奥运金牌数量、银牌数量、铜牌数量和总奖牌数量。
体育项目数和类别:不同奥运会的体育项目数量和类型(例如,游泳、田径等)对不同国家的表现有重要影响。我们可以为每个国家创建一个特征,表示该国参赛项目的数量,或者该国在各个项目中的表现(如游泳、田径、体操等)。
主办国效应:如果某个国家是主办国,可以为其创建一个二进制特征(
1
表示主办国,
0
表示非主办国),以考虑主办国的表现优势。
经济与体育投资:可以使用该国的经济数据(如
GDP
)和体育投资数据(如国家年度体育预算)来预测其在奥运会中的表现。
特征选择方法:
L1
正则化:使用
Lasso
回归(
L1
正则化)来选择重要特征,
Lasso
有助于剔除冗余特征。
树模型的重要性:
XGBoost
本身会提供特征重要性评估,基于这一评估,我们可以选择对预测结果影响最大的特征。
import xgboost as xgb
import matplotlib.pyplot as plt
训练
XGBoost
模型
model = XGBRegressor(objective=‘reg:squarederror’, **best_params)
model.fit(X_train, y_train)
绘制特征重要性
xgb.plot_importance(model)
plt.show()
(3)
增加交叉验证与早停(
Early Stopping
)
为了避免过拟合,可以使用交叉验证来评估模型的性能。同时,可以使用早停(
Early Stopping
)来在训练过程中监控验证集的误差,避免模型在训练集上过拟合。
from sklearn.model_selection import cross_val_score
from xgboost import XGBRegressor
使用交叉验证评估模型
model = XGBRegressor(objective=‘reg:squarederror’, **best_params)
cv_scores = cross_val_score(model, X_train, y_train, cv=5, scoring=‘neg_mean_absolute_error’)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV score: {cv_scores.mean()}")
早停方法:
通过设置
early_stopping_rounds
参数,可以在验证集的误差停止下降时提前终止训练,避免过拟合。
model = XGBRegressor(objective=‘reg:squarederror’, **best_params)
model.fit(X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=10)
输出最佳的树的数量
print(f"Best number of trees: {model.best_iteration}")
(4)
模型融合与堆叠(
Stacking
)
在
XGBoost
模型的基础上,还可以使用模型融合技术提高准确性。常见的融合方法有:
模型加权平均:将多个不同的模型(例如
XGBoost
、
LightGBM
、随机森林等)的预测结果进行加权平均。
堆叠(
Stacking
):通过训练一个元学习器(如逻辑回归、神经网络等),利用多个基学习器的预测结果作为输入来进行最终预测。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import StackingRegressor
定义基学习器
base_learners = [
(‘xgb’, XGBRegressor(objective=‘reg:squarederror’)),
(‘rf’, RandomForestRegressor())
]
堆叠模型
stacking_model = StackingRegressor(estimators=base_learners, final_estimator=LogisticRegression())
stacking_model.fit(X_train, y_train)
预测
y_pred = stacking_model.predict(X_test)
问题三:教练效应分析
目标:
问题三的目标是分析
“
伟大教练效应
”
对奥运奖牌数的影响,即是否存在名教练在不同国家间流动并对成绩产生显著影响的情况。比如,
Lang Ping
曾分别执教过美国和中国的女子排球队,带领两队分别获得了奥运金牌,而
Béla Károlyi
是体操领域的著名教练,曾分别执教罗马尼亚和美国体操队取得了显著成绩。问题要求我们分析这些教练的影响,并估算他们对奖牌数量的贡献。
建模思路
确定建模目标
我们需要建立一个模型,分析以下几个问题:
教练更替与奖牌数的变化:当国家更换教练时,奖牌数是否出现显著变化?如果有,变化的幅度如何?
伟大教练效应的估算:通过历史数据,量化教练效应对奖牌数的贡献。
不同国家的教练投资:根据模型,哪些国家应该在特定的项目中投入更多的资源,聘请著名教练?
教练与运动员的互动关系:教练如何影响运动员的表现,特别是那些具有国际经验的教练。
数据收集与预处理
为了进行教练效应分析,我们需要收集和清理以下数据:
教练信息:教练的背景、曾经执教过的国家、执教时间段及其带领的队伍表现(奖牌数、金牌数等)。
运动员与奖牌数据:运动员在每届奥运会的表现数据,主要关注那些由著名教练执教的国家和项目。
历史奖牌数据:各国在过去所有奥运会中的奖牌数,特别是金牌数。需要分析教练变动前后的表现变化。
体育项目数据:每届奥运会的项目种类与数量,不同项目的奖牌分布对国家的影响不同。
国家特征数据:包括该国的经济水平、体育投入、运动员数量等。
数据预处理步骤包括:
去除重复数据。
填补缺失值,特别是教练的变动和奖牌数数据。
标准化或归一化一些特征,如国家经济水平、体育投资等。
教练效应的建模
我们将从两方面入手分析教练效应:
(1)
基于历史数据的回归模型
我们首先可以通过回归分析来探究教练更替与奖牌数之间的关系。设想以下回归模型:
目标变量:奖牌数(包括金牌、总奖牌数)。
特征变量:
教练更替:一个二元变量,表示是否发生了教练变动(
1
表示更换教练,
0
表示没有更换教练)。
教练影响力:根据教练的历史成绩或排名,设定一个量化的教练影响因子。例如,使用教练带领的队伍在过去奥运会中的成绩作为衡量指标。
运动员数量:每个国家的运动员数量(数量越多,获得奖牌的机会越大)。
体育项目数量:参赛的体育项目数量。项目种类的增加意味着更多的获奖机会。
国家经济和体育投入:这些特征对奖牌数的影响在前述模型中已经考虑。
回归模型公式:
Y_i = \beta_0 + \beta_1 \cdot X_{\text{coach_change}} + \beta_2 \cdot X_{\text{coach_influence}} + \beta_3 \cdot X_{\text{athletes}} + \beta_4 \cdot X_{\text{sports}} + \beta_5 \cdot X_{\text{economy}} + \epsilon
其中:
YiY_i
是国家
ii
的金牌数或总奖牌数。
X_{\text{coach_change}}
是教练更替的二元变量。
X_{\text{coach_influence}}
是教练的影响因子(如历史成绩)。
XathletesX_{\text{athletes}}
是该国运动员数量。
XsportsX_{\text{sports}}
是参赛体育项目的数量。
XeconomyX_{\text{economy}}
是该国的经济水平。
ϵ\epsilon
是误差项。
通过这个回归模型,我们可以量化教练变动对奖牌数的影响,并评估教练是否有显著效应。
(2)
因果推断分析
如果数据足够丰富,我们还可以通过因果推断分析来探讨教练效应。因果推断方法能够帮助我们确定教练更替是否直接导致奖牌数的变化,而不是仅仅存在相关性。
常见的因果推断方法包括:
回归不连续设计(
RDD
):当某个国家更换教练时,可以将其作为回归不连续设计中的
“
切点
”
,分析教练更替前后奖牌数的变化。
倾向得分匹配(
Propensity Score Matching, PSM
):通过匹配那些更换教练和没有更换教练的国家的其他特征(如经济水平、运动员数量等),来隔离教练效应对奖牌数的影响。
(3)
基于教练和运动员的关系建模
考虑到教练与运动员的互动关系,特别是在一些国家或项目中,教练的影响可能与运动员的表现密切相关。我们可以进一步通过以下方法来分析:
运动员表现:通过训练运动员和比赛表现数据,评估教练对运动员的影响。通过运动员的历史表现、成绩提升等指标来量化教练的影响。
团队合作效应:对于团体项目(如篮球、排球、足球等),教练的影响可能更加显著。可以分析教练如何在团队管理和战术部署中起到关键作用。
(4)
模型评估与验证
为了验证教练效应模型的可靠性,我们可以使用以下评估方法:
交叉验证:将数据分为训练集和测试集,使用交叉验证评估模型的泛化能力。
误差分析:计算模型的均方误差(
MSE
)、平均绝对误差(
MAE
)等指标,评估模型预测的精度。
重要性分析:对于
XGBoost
等模型,使用特征重要性分析来评估教练因素对奖牌数的贡献。
教练效应的估算
通过回归分析和因果推断方法,我们可以估算
“
伟大教练效应
”
对奖牌数的贡献。具体来说,我们可以:
量化教练更替后的奖牌数变化,评估
“
伟大教练
”
的作用。
如果某些国家在更换教练后奖牌数显著上升,则可以认为教练对奖牌数有较大影响。
通过统计检验,分析教练变动对奖牌数的显著性。
教练效应的应用建议
根据模型的结果,我们可以为各国奥委会提供以下建议:
教练投资:哪些国家应在特定的项目中增加教练投资,以提升奖牌数。例如,在体操、游泳等项目中,聘请经验丰富的教练可能带来显著的成绩提升。
教练人才引进:哪些国家应引进外籍教练,特别是那些有历史成绩和国际经验的教练。
改进教练体系:如果教练更替对奖牌数有较大影响,国家奥委会可以考虑通过完善教练体系,提供更好的支持和资源,以提高成绩。
总结
在问题三中,通过建立回归模型、因果推断分析和教练
运动员关系建模,我们可以量化并评估
“
伟大教练效应
”
对奥运奖牌数的影响。通过这些分析,我们能够为各国奥委会提供关于如何通过引进优秀教练来提升奥运表现的策略建议。

















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









