






#深度学习
超参数是在机器学习模型中,在模型训练之前设定的一些参数。这些参数不是通过模型训练学习得到的,而是需要人为设定或通过某些优化方法来调整的。超参数对模型的性能有重要影响,因此它们的设定通常需要根据具体问题和数据集的特点来进行调整。
常见的超参数包括:
-
学习率(Learning Rate):在模型训练过程中,学习率决定了参数更新的步长大小。学习率过大可能导致训练不稳定,过小则可能导致训练过程缓慢。
-
批量大小(Batch Size):批量大小是指在一次梯度更新中使用的样本数量。批量大小的大小会影响模型的收敛速度和稳定性。
-
迭代次数(Number of Epochs):迭代次数是指整个数据集被遍历并用于训练模型的次数。迭代次数太少可能导致模型未能充分学习,而过多则可能导致过拟合。
-
隐藏层大小和数量:在神经网络中,隐藏层的大小和数量决定了模型的复杂度。隐藏层过少或节点过少可能导致模型欠拟合,过多则可能导致过拟合。
-
正则化参数:如L1和L2正则化中的参数,用于控制模型复杂度和防止过拟合。
-
dropout率:在神经网络中,dropout是指在训练过程中随机丢弃一部分神经元的操作,以防止过拟合。dropout率决定了被丢弃的神经元的比例。
1.学习率的调整规则
学习率的调整一般在0.01与0.001之间进行的调整,常见的学习率调整策略:
-
固定学习率:在整个训练过程中保持学习率不变。这种方法简单,但可能无法在训练初期快速学习,或在训练后期精细调整。
-
分段常数学习率:将训练过程分为几个阶段,每个阶段使用不同的固定学习率。例如,可以在训练初期使用较大的学习率来快速收敛,然后在训练后期减小学习率以进行精细调整。
-
学习率衰减:随着训练的进行,逐步减小学习率。这种方法可以是在每个迭代后按固定比例减小(如乘以一个小于1的常数),或者按照预定的步骤(如每过一定的迭代次数后减小学习率)。
-
学习率预热(Warm-up):在训练开始时使用较小的学习率,然后逐渐增加到预定的学习率。这有助于在训练初期稳定模型。
-
周期性学习率(Cyclical Learning Rates, CLR):这种方法让学习率在一定的范围内周期性地变化,如使用三角形或正弦波形。这种方法可以帮助模型跳出局部最小值。
-
自适应学习率调整:使用某些优化算法,如Adam、RMSprop或Adagrad,它们能够根据参数的历史梯度自适应地调整学习率。
-
使用学习率调度器:许多深度学习框架提供了学习率调度器(Learning Rate Scheduler),可以根据预定的策略或自定义的函数来自动调整学习率。
选择合适的学习率调整策略通常需要根据具体问题和数据集进行实验。在实践中,研究者们通常会尝试多种策略,并通过验证集上的性能来选择最佳的学习率调整方法。
以下是一组不同学习率的精度对比:
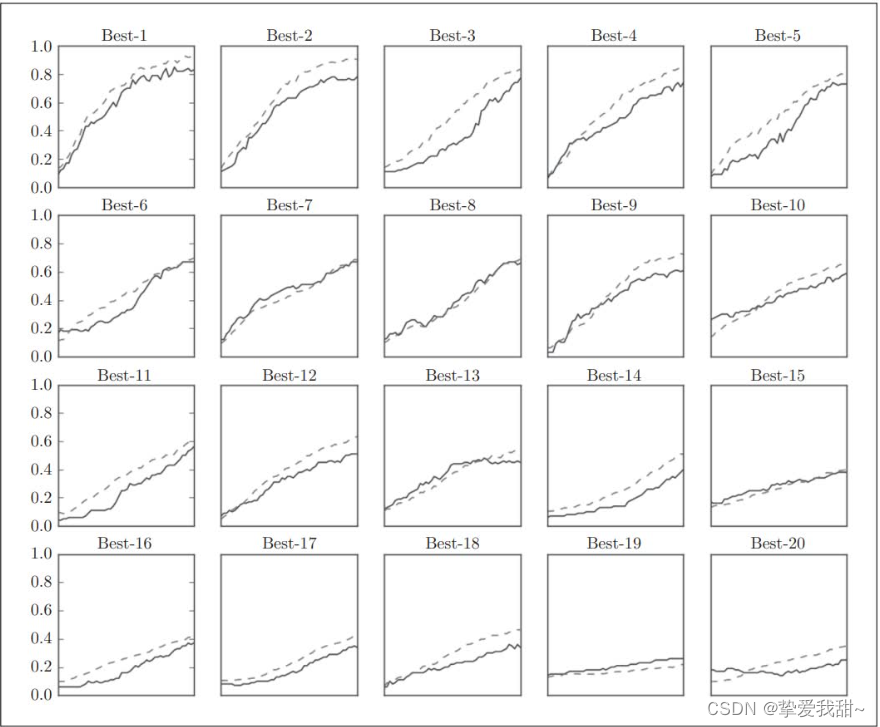
Best-1 (val acc:0.83) | lr:0.0092, weight decay:3.86e-07
Best-2 (val acc:0.78) | lr:0.00956, weight decay:6.04e-07
Best-3 (val acc:0.77) | lr:0.00571, weight decay:1.27e-06
Best-4 (val acc:0.74) | lr:0.00626, weight decay:1.43e-05
Best-5 (val acc:0.73) | lr:0.0052, weight decay:8.97e-06
后面的数据太差不进行展示说明,大家可以根据自己的需要进行调整。
2.批量大小的选择
批量大小(Batch Size)在机器学习模型的训练过程中是一个重要的超参数,它指的是在每次权重更新时使用的样本数量。选择合适的批量大小对于模型的训练效率和性能都有显著影响。以下是一些关于选择批量大小的一般指导原则:
-
计算资源:较大的批量大小需要更多的内存和计算资源。如果你的硬件资源有限,可能需要选择一个较小的批量大小以避免内存溢出。
-
梯度稳定性:较大的批量大小可以减少梯度估计的方差,从而使得训练过程更加稳定。但是,如果批量大小太大,可能会导致模型在训练数据上的表现不佳,尤其是在数据分布不均匀或有噪声的情况下。
-
学习率:批量大小和学习率之间存在一定的关系。一般来说,较大的批量大小需要较小的学习率,而较小的批量大小可以使用较大的学习率。这是因为较大的批量大小会导致梯度的方向更加稳定,因此可以采取更小的步长。
-
模型泛化能力:较小的批量大小可能会导致模型在训练数据上的泛化能力更强,因为每次更新都是基于少量的样本,这样模型被迫更加频繁地调整权重。
-
数据集大小:如果数据集非常小,可能需要使用较小的批量大小或者甚至使用批量大小为1的在线学习(也称为小批量大小)。
-
实验和验证:最终,批量大小的选择应该基于实验和验证。在不同的数据集和模型上,最佳的批量大小可能会有所不同。通常,研究者会尝试一系列不同的批量大小,并通过验证集上的性能来选择最佳的设置。
在实际应用中,常见的批量大小范围可能从2的幂次(如4、8、16、32、64、128、256等)到数千不等。选择合适的批量大小是一个需要综合考虑多个因素的过程,通常需要通过实验来找到最佳值。
3.迭代次数
迭代次数(Number of Epochs),在机器学习模型训练中,指的是整个数据集被模型完整地遍历并用于训练的次数。每次遍历数据集的过程称为一个epoch。迭代次数的选择对模型的训练效果有重要影响:
-
训练时间:迭代次数越多,模型训练所需的时间越长。因此,在选择迭代次数时,需要考虑计算资源的可用性和训练时间的限制。
-
模型性能:一般来说,随着迭代次数的增加,模型在训练数据上的性能会逐渐提高,直到达到一个饱和点。超过这个点,继续增加迭代次数可能只会导致边际性能提升,或者甚至开始出现过拟合。
-
过拟合风险:如果迭代次数过多,模型可能会过度拟合训练数据,这意味着模型在训练数据上的性能很好,但在未见过的新数据上的性能会下降。为了避免过拟合,可以采用早停(Early Stopping)等技术。
-
数据集大小和多样性:对于小型或简单的数据集,可能只需要少量的迭代次数。而对于大型或复杂的数据集,可能需要更多的迭代次数。此外,如果数据集具有很高的多样性,更多的迭代次数可能有助于模型学习到更多的特征。
-
实验和验证:通常,最佳的迭代次数是通过实验和验证来确定的。训练过程中,可以监控模型在验证集上的性能,一旦性能不再显著提升,就可以停止训练。这通常是通过早停策略实现的。
-
学习率调整:迭代次数也与学习率的调整策略有关。例如,如果使用学习率衰减,可能需要更多的迭代次数来观察学习率变化对模型性能的影响。
总之,选择合适的迭代次数是一个需要平衡训练时间、模型性能和过拟合风险的过程。通常,研究者会通过交叉验证和其他模型评估技术来确定最佳的迭代次数。
深度学习之与学习相关的技巧分享结束啦,期待大家的关注,下期再见!















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









