







 本文详细记录了使用CenterNet训练针对特定物体(如手部)关键点检测模型的过程,包括环境配置、数据集准备、CenterNet代码修改等步骤。作者在训练中遇到的问题及解决方案,特别是针对单类别三关键点的数据集进行了代码调整,并分享了训练和测试阶段的代码修改细节。最后展示了训练结果和测试效果。
本文详细记录了使用CenterNet训练针对特定物体(如手部)关键点检测模型的过程,包括环境配置、数据集准备、CenterNet代码修改等步骤。作者在训练中遇到的问题及解决方案,特别是针对单类别三关键点的数据集进行了代码调整,并分享了训练和测试阶段的代码修改细节。最后展示了训练结果和测试效果。
概述
网上搜了一圈,关于CenterNet 训练关键点数据的资料非常少,而且讲得都很模糊,没法解决实际问题,也未说明细节和要素。在踏坑许久之后,才跑通CenterNet的关键点训练,于是记录一下踏坑历程,以备后忘
环境
cuda11.0
torch1.7.1
torchvision0.8.2
numpy 1.19.2
这是我的环境版本,不是非得这个版本
数据集准备
参考我的另一篇文章
COCO KeyPoints关键点数据集准备
CenterNet 代码修改
训练代码修改
我的数据集 的类别是1类, 关键点是3个
新的数据集代码创建
CenterNet/src/lib/datasets/datasets 目录, coco_hp.py是原来的coco keypoints官方数据集的数据集代码, 我们从这文件copy一份, 命名为handKeyPoints.py
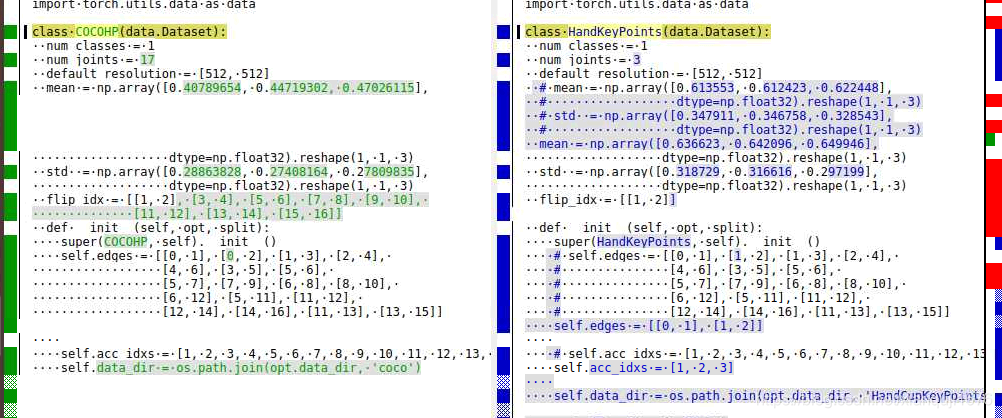
修改其中内容, 先看下对比图
修改代码
num_classes = 1 #类别1
num_joints = 3 #关键点个数3
default_resolution = [512, 512]
mean = np.array([0.636623, 0.642096, 0.649946],
dtype=np.float32).reshape(1, 1, 3) #数据集计算出的mean
std = np.array([0.318729, 0.316616, 0.297199], #数据集计算出的std
dtype=np.float32).reshape(1, 1, 3)
flip_idx = [[1, 2]] #图像翻转,这个我也不懂, 就照着官方的写了一个,跟实际的关键点数对应
def __init__(self, opt, split):
super(HandKeyPoints, self).__init__()
self.edges = [[0, 1], [1, 2]]
self.acc_idxs = [1, 2, 3]
#数据集文件夹 目录 data/HandCupKeyPoints , 这个文件夹里面是annotations、test2017 、train2017三个文件夹
self.data_dir = os.path.join(opt.data_dir, 'HandCupKeyPoints')
if split == 'val': #这里我们的是test而不是val,所以改一下
split = 'test'
self.img_dir = os.path.join(self.data_dir, '{}2017'.format(split))
if split == 'test':
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'test.json') #直接指定文件名
else:
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'train.json') #直接指定文件名
这个文件就修改完毕, 其他不用动
修改文件 CenterNet/src/lib/datasets/dataset_factory.py
对比如下:
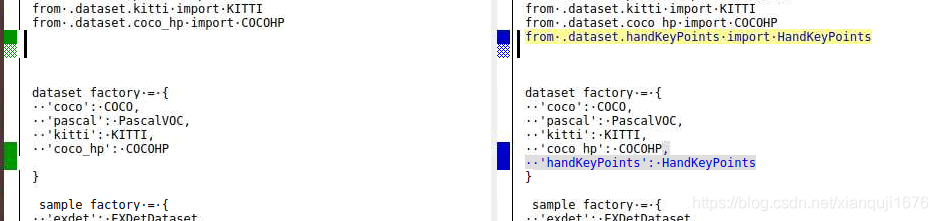
我这里大小写不一致,不用管, dataset_factory 字段 key 就是 刚刚创建的handKeyPoints.py 的前缀 , value就是 文件里 class 的类名

修改文件 CenterNet/src/lib/opts.py
第15行 修改默认数据集为 handKeyPoints 数据集

第323行
opt.flip_idx = False#dataset.flip_idx
opt.heads = {'hm': opt.num_classes, 'wh': 2, 'hps': 34} #17个点的x、y 共 34个值
修改为:
# opt.flip_idx = False
opt.flip_idx = dataset.flip_idx
opt.heads = {'hm': opt.num_classes, 'wh': 2, 'hps': 6} #3个点的x、y 共 6个值
第345行
'multi_pose': {
'default_resolution': [512, 512], 'num_classes': 1,
'mean': [0.408, 0.447, 0.470], 'std': [0.289, 0.274, 0.278], #数据集的 mean std
'dataset': 'coco_hp', 'num_joints': 17, #关键点个数 17个
'flip_idx': [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10],
[11, 12], [13, 14], [15, 16]]}, #flip_idx
修改为 自己数据集的 mean 和std
flip_idx 修改为相应的
'multi_pose': {
'default_resolution': [512, 512], 'num_classes': 1,
'mean': [0.614, 0.612, 0.622], 'std': [0.348, 0.347, 0.329], #数据集的 mean std
'dataset': 'handKeyPoints', 'num_joints': 3, #关键点个数 3个
'flip_idx': [[1, 2]]}, #flip_idx 看情况写
到此,训练部分的代码就修改完了, 可以开始训练了
编写脚本train.sh, 内容
python main.py multi_pose --arch dla_34 --dataset handKeyPoints --lr 0.25e-4 --batch_size 16 --gpus 0 --load_model ../models/multi_pose_dla_3x.pth
学习率自定义设置,
–batch_size 依据GPU显存大小, 如果CUDA out of memery 就改小点
–load_model …/models/multi_pose_dla_3x.pth 这个是官方训练好的模型,
开始训练
报一堆警告,不用管, 如下:
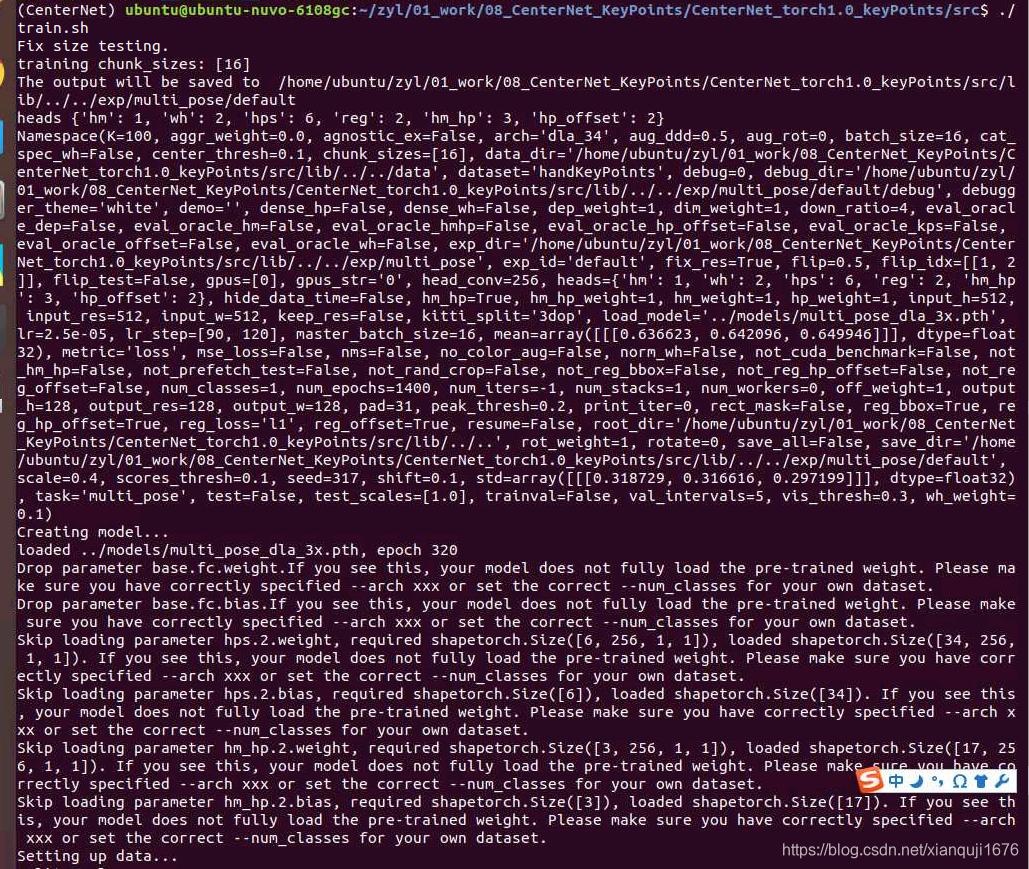
输出训练过程日志
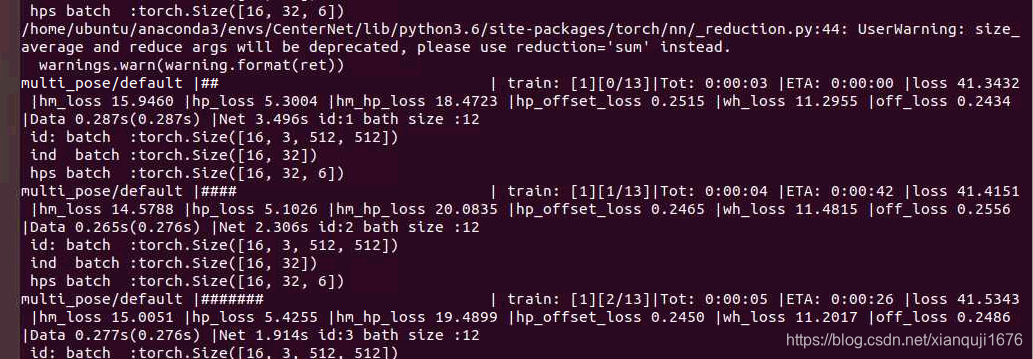
看损失值, 在验证损失不再下降的时候停止训练
训练的结果
训练的结果保存在exp目录下

模型文件如下:

这样我们就得到了 训练好的模型,
我的数据集较少,不知道是由于标注质量的问题还是学习率的问题,最终验证损失loss=2.7左右时不再下降。
测试
训练代码修改
修改文件 CenterNet/src/lib/utils/debugger.py
增加handKeyPoints 数据集类别判断

第45行增加
elif num_classes == 1 or dataset == 'handKeyPoints': #增加自定义的handKeyPoints类别
self.names = handKeyPoints_class #类别名称
self.names = ['p'] #类别名称
self.num_class = 1 #类别数
self.num_joints = 3 #关键点数量
self.edges = [[0, 1], [1, 2]] #关键点连接关系
self.ec = [(255, 0, 0), (0, 0, 255), (255, 0, 0)] #颜色
self.colors_hp = [(255, 0, 255), (255, 0, 0), (0, 0, 255)]
第467行增加
handKeyPoints_class = ['hand']
修改文件 CenterNet/src/lib/detectors/multi_pose.py
第85行
dets[:, :, :4] *= self.opt.down_ratio #bbox 的4个值
dets[:, :, 5:39] *= self.opt.down_ratioemmina.mo #5~39 是17个关键点的坐标34个值
这里修改为:
dets[:, :, :4] *= self.opt.down_ratio #bbox 的4个值
dets[:, :, 5:11] *= self.opt.down_ratioemmina.mo #5~11 是3个关键点的坐标6个值
第101行
debugger.add_coco_bbox(bbox[:4], 0, bbox[4], img_id='multi_pose') #bbox 的4个值
debugger.add_coco_hp(bbox[5:39], img_id='multi_pose') #5~39 是17个关键点的坐标34个值
修改为
debugger.add_coco_bbox(bbox[:4], 0, bbox[4], img_id='multi_pose') #bbox 的4个值
debugger.add_coco_hp(bbox[5:11], img_id='multi_pose') #5~11 是3个关键点的坐标6个值
到这里测试代码就修改好了
编写测试脚本test_keyPoints.sh, 内容如下:
python demo.py multi_pose --demo ../images/16.jpg --load_model ../models/model_best_keypoints.pth
模型用的就是上述训练好的模型
测试结果
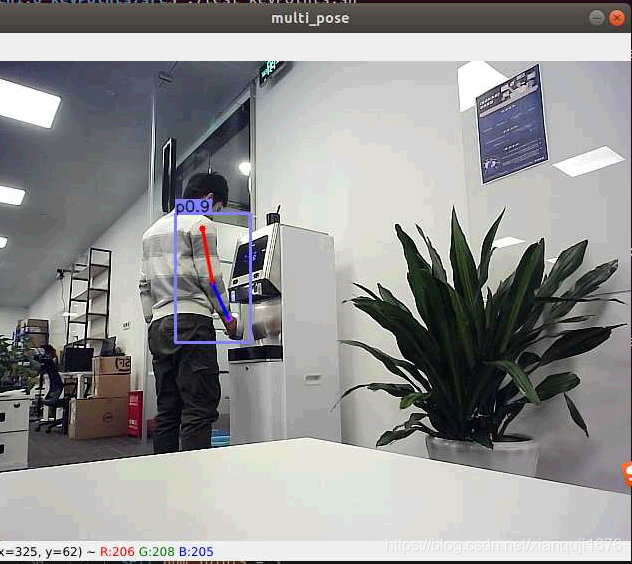
识别出了手臂, 置信度为0.9

















 9324
9324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









