







打开要提取的新闻页面
右键-》审查元素(N)进入开发者界面
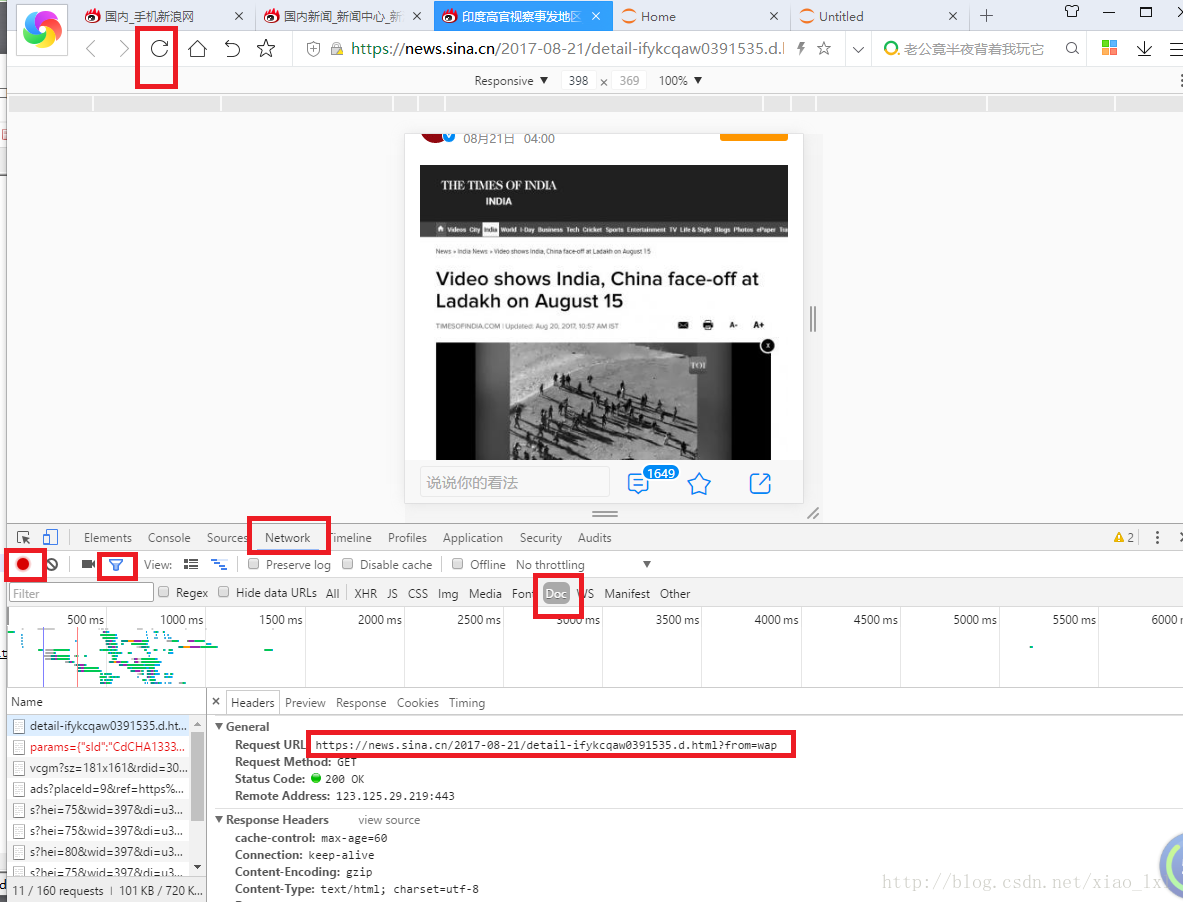
进入Network,选中recording network log(红色圆点),筛选
(蓝色漏斗),然后重新加载页面。选择doc,左下第一列即为所选目标。通过headers 和 Responses可以确认是不是我们所要选择的内容。
headers中 Request URL:https://news.sina.cn/2017-08-21/detail-ifykcqaw0391535.d.html?from=wap 就是我们所要爬取的网页的网址,将其复制到requests.get()中
- 标题的选取。
点击“选择元素”图标,将光标放在标题上,即可看到标题所在代码行。
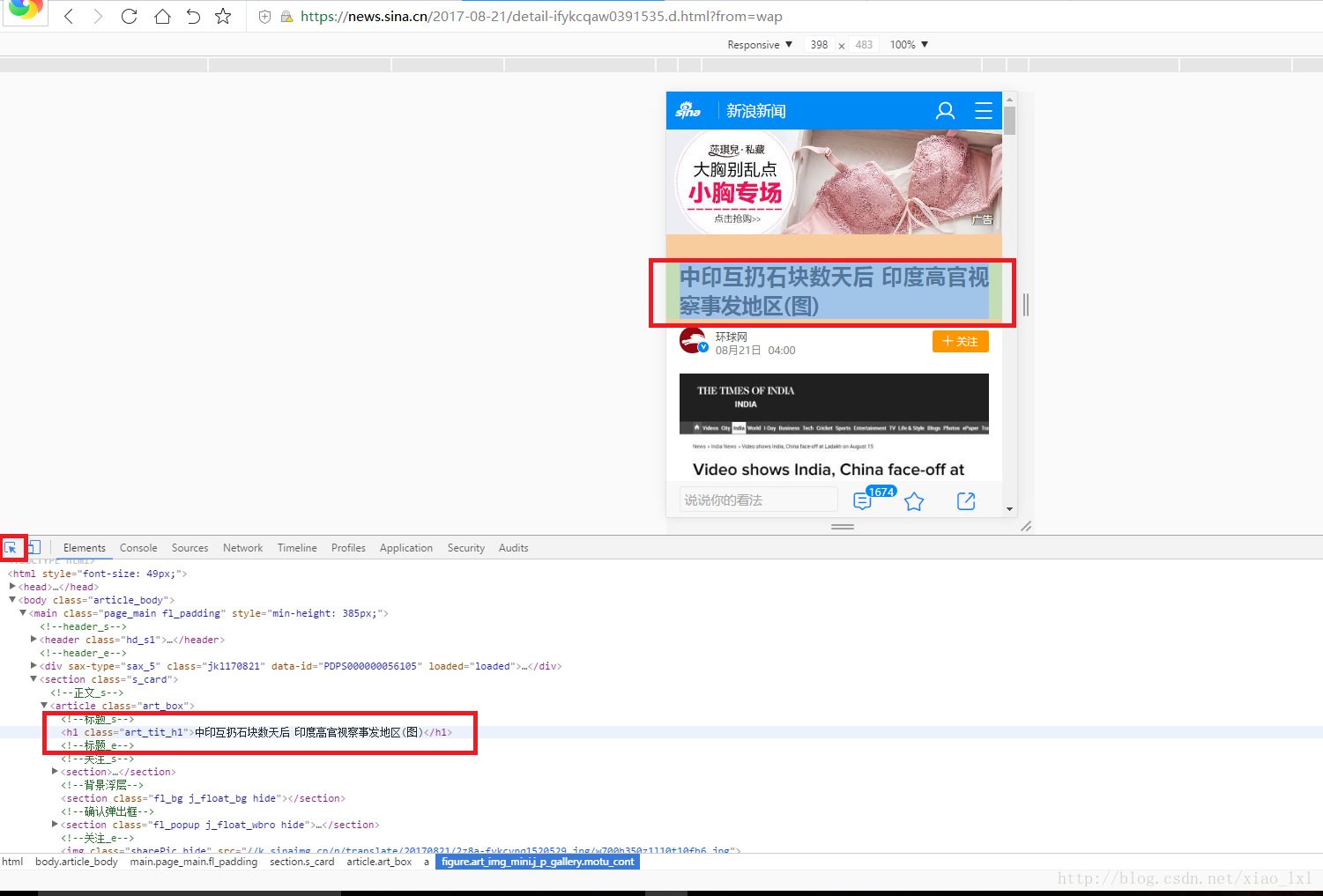
这里可以看到标题的calss 为
<h1 class="art_tit_h1">....</h1>双击复制art_tit_h1,放入我们的soup.select()中 。
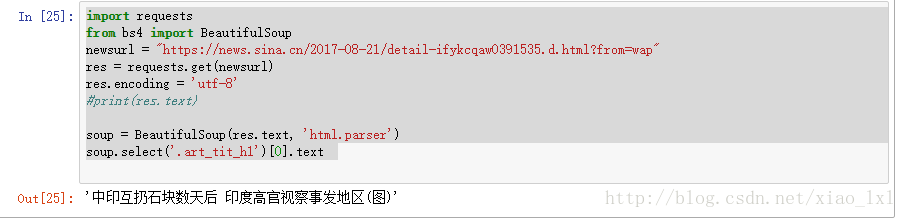
- 获取时间
timesource = soup.select('.weibo_time')[0].contents[1].text.strip()
type(timesource)
timesource
注意:
soup.select()调用的时候
class 用 ‘.*’
id 用 ‘#*’















 2460
2460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









