







前言
在人工智能领域,大语言模型的发展日新月异。近日,幻方量化旗下的深度求索(DeepSeek)公司推出的DeepSeek-V3模型引起了广泛关注。该模型以其强大的性能、高效的训练和出色的多语言处理能力,为自然语言处理领域带来了新的突破。本文将对DeepSeek-V3进行全面的介绍和分析,帮助读者深入了解这一先进的AI模型。
一、项目概述
DeepSeek-V3是一款自研的混合专家(MoE)模型,拥有高达6710亿参数,其中激活参数为370亿,在14.8万亿token上进行了预训练。它采用了先进的架构和训练方法,通过精细划分问题空间来优化处理能力,在多项任务中表现出色。与前代模型相比,DeepSeek-V3在性能和效率上都有了显著提升,尤其在知识获取、长文本处理、代码生成、数学计算以及中文理解方面取得了优异的成绩。

二、技术特点
- 强大的混合专家架构:采用MoE架构,能够根据不同的任务和输入自动选择最合适的专家模型进行处理,从而在处理复杂任务时显著提高效率和精度,同时降低了模型的计算量和存储需求。
- 大规模预训练与知识储备:在14.8万亿token上进行预训练,使其拥有丰富的知识储备,能够更好地理解和处理各种自然语言文本,为准确回答问题和生成高质量内容提供了坚实的基础。
- 高效的训练优化:支持FP8混合精度训练,提高训练速度的同时减少了GPU内存使用;设计DualPipe算法,实现高效的流水线并行处理;优化跨节点AI-IL通信,充分利用Infiniband和NVLink带宽,大大降低了训练成本。
- 出色的多语言处理能力:支持多达20种语言的实时翻译和语音识别,在多语言编程能力上也取得了重大突破,在Aider多语言编程测评中的表现超越了Claude 3.5 Sonnet v2等竞争对手,适用于跨国企业、翻译机构等多种场景。
- 卓越的代码生成与理解能力:可以根据用户的需求和描述,快速生成高质量的代码片段,涵盖多种编程语言,并且能够理解代码的逻辑和功能,进行代码审查、优化和调试等工作,为开发者提供了强大的编程辅助工具。
三、性能评测
-
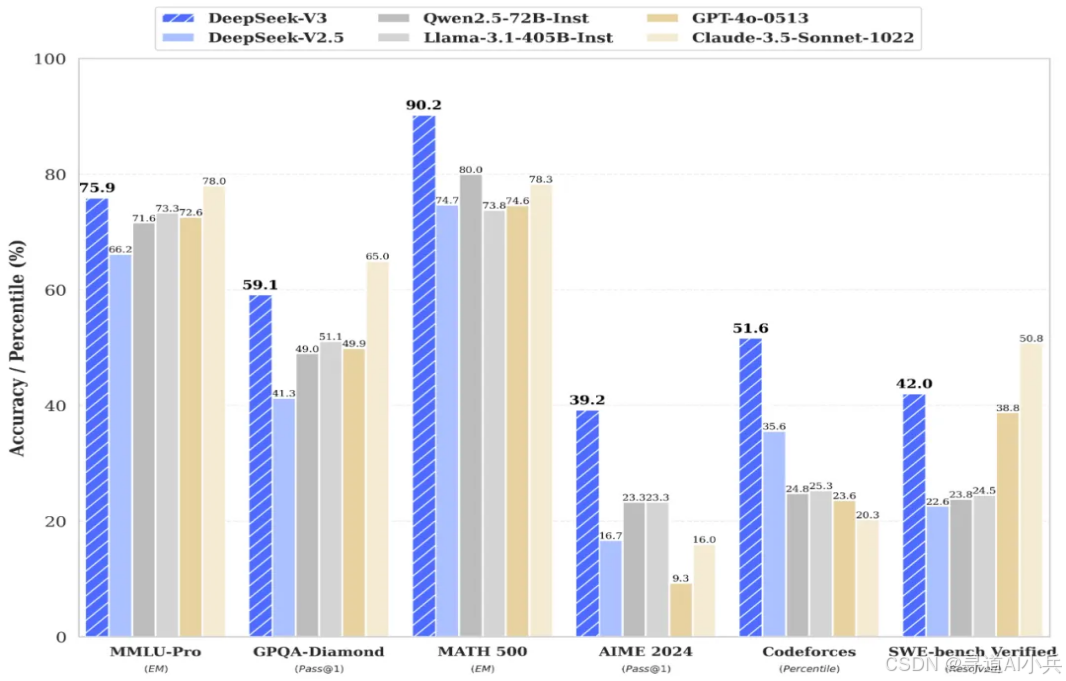
与开源模型对比:在一系列严格的基准测试中,DeepSeek-V3 展现出了强大的竞争力,其成绩显著超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他知名开源模型。在语言理解、文本生成、知识问答等多个任务领域,DeepSeek-V3 都表现出了更优的性能和更强的泛化能力,能够更好地适应不同场景和任务的需求,为用户提供更准确、更有用的结果。
-
与闭源模型对比:与世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 相比,DeepSeek-V3 在性能上毫不逊色,展现出了与它们不分伯仲的实力。尤其在数学能力方面,DeepSeek-V3 更是大放异彩,大幅超过了所有开源闭源模型。在美国数学竞赛和全国高中数学联赛题库等具有挑战性的测试中,DeepSeek-V3 凭借其卓越的数学推理和计算能力,取得了令人瞩目的成绩,展现出了在数学领域的深厚造诣和强大优势。
-
生成速度提升:DeepSeek-V3 在生成速度方面实现了重大突破,其生成吐字速度从 20tps 大幅提高至 60tps,相比 v2.5 模型实现了 3 倍的显著提升。这一速度的提升使得模型在实时交互应用中能够更加迅速地响应用户的请求,为用户带来更加流畅、自然的使用体验,满足了大多数实时应用对快速响应的严格要求,如在线客服、实时翻译等场景。
-
训练效率提高:在训练效率方面,DeepSeek-V3 同样表现出色,其训练成本大幅降低,仅为 2.788m H800GPU 小时,总成本为 5.576m 美元。与其他大规模模型相比,这一训练成本的显著减少无疑是一大亮点,使得更多的研究机构和企业能够在有限的资源条件下进行模型的训练和优化,降低了人工智能技术的应用门槛,为推动自然语言处理技术的广泛应用和发展提供了有力支持。
四、应用场景
- 聊天和编码场景:为开发者设计,能够理解和生成代码,提高编程效率,可用于辅助程序员编写代码、代码审查、算法设计等工作,还能在聊天中提供准确有用的信息和建议。
- 多语言自动翻译:支持多达20种语言的实时翻译和语音识别,适用于跨国企业、翻译机构、旅游行业等需要处理多种语言内容的场景,帮助用户快速准确地进行语言转换和沟通。
- 教育领域:在数学题解答中表现出色,可用于辅助学生学习数学、编程等知识,提供个性化的学习辅导和解答疑问,也可以帮助教师生成教学材料、设计课程等。
- 创意产业:如AI写作、AI绘画等领域,可根据用户的创意和描述生成高质量的文本和图像内容,为创作者提供灵感和素材,提高创作效率和质量。
五、在线使用和API服务
-
使用web服务:用户可以直接访问chat.deepseek.com进行在线体验和使用,无需进行本地部署和安装,方便快捷。在web界面上,用户可以直接输入文本进行交互,获取模型的回答和建议。
-
使用API:DeepSeek提供了API服务(platform.deepseek.com),用户需要按照官方文档进行注册和申请密钥。获取密钥后,可以通过HTTP请求或SDK进行调用。在调用时,需要按照API的规范传入相应的参数,如输入文本、请求类型等,即可获取模型的输出结果。

六、本地部署推理
1、安装依赖
在进行本地部署推理时,首先需要安装所需的依赖库。上述命令通过指定特定的链接,使用 pip 工具安装了包括 sglang 在内的所有相关依赖,确保了后续服务的正常运行。
pip install "sglang[all]" --find-links https://flashinfer.ai/whl/cu124/torch2.4/flashinfer
2、启动服务
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --enable-dp-attention --tp 8 --trust-remote-code
在安装好依赖后,通过运行上述命令启动服务。其中,指定了模型为 deepseek-ai/DeepSeek-V3,并启用了 dp-attention,设置了 tp 为 8 以及信任远程代码等参数,使得模型能够在本地环境中顺利运行,为后续的调用和使用做好准备。
3、调用示例
import openai
client = openai.Client(
base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
# Chat completion
response = client.chat.completions.create(
model="default",
messages=[
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."},
],
temperature=0,
max_tokens=64,
)
print(response)
结语
DeepSeek-V3作为一款开源的AI模型,以其强大的性能、高效的训练和丰富的功能,为自然语言处理领域带来了新的活力和机遇。它的出现不仅提升了中国在全球AI领域的影响力,也为开发者和企业提供了一个高性能、低成本的解决方案。然而,我们也应该意识到,AI技术的发展还面临着一些挑战和问题,如模型的安全性、隐私保护、伦理道德等。在使用和发展AI技术的过程中,我们需要不断地探索和创新,以实现AI技术的可持续发展和社会价值的最大化。
官网地址:https://www.deepseek.com/
仓库地址:https://github.com/deepseek-ai/deepseek-v3
模型地址:https://huggingface.co/deepseek-ai/DeepSeek-V3

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!



















 5281
5281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











