






dify实验室
基于LLMOps平台-Dify的一站式学习平台。包含不限于:Dify工作流案例、DSL文件分享、模型接入、Dify交流讨论等各类资源分享。
本文受圆桌讨论启发,将详细介绍如何利用 Dify 平台,如何围绕一个核心议题,深入、多维地展开探讨,激发不同视角的碰撞,从而生成高质量文章。最终编排一个名为 "DeepTalk" 的高级聊天应用工作流,以模拟一场围绕用户指定议题的进行圆桌讨论,进而输出高质量的内容。工作流预览如下:
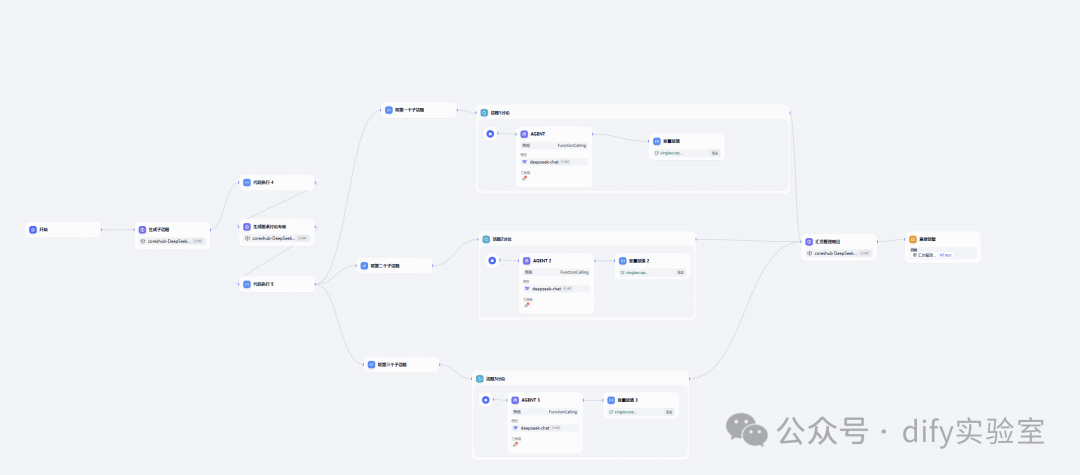
(本文DSL文件见文末)
一、 工作流目标与设计思路
本工作流的核心目标是:当用户提出一个讨论议题时,能够自动完成以下任务:
- 生成议题分支:
基于主议题,智能生成三个既相互关联又各有侧重、能激发多元观点的子话题。
- 设定虚拟嘉宾:
自动设计一组(本例中为四位)具有不同身份背景、专业视角和发言风格的虚拟专家。
- 模拟多轮讨论:
组织这些虚拟专家,分别围绕三个子话题进行模拟发言,并允许他们利用外部工具(如搜索)来丰富论据。
- 汇总形成结论:
将所有讨论内容进行整合,最终形成一个条理清晰、涵盖多方观点的总结性回复。
整体设计思路是模仿真实圆桌讨论的流程:先确定议程(子话题),再邀请嘉宾,然后分环节讨论,最后进行总结。
二、 工作流编排步骤详解
以下是 "DeepTalk" 工作流的具体编排步骤:(本文DSL文件见文末)
1. 开始节点 (Start):
作为工作流的入口,接收用户输入的原始议题(#sys.query#)。这是整个讨论的基础。
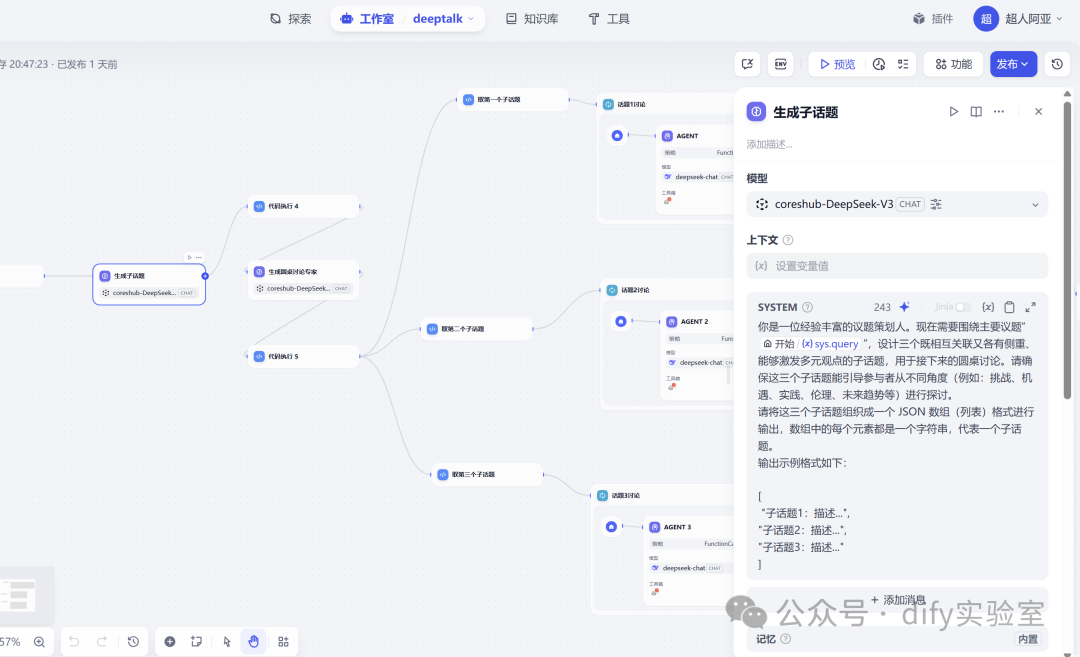
2. 生成子话题 (LLM 节点):
- 输入:
接收开始节点传递过来的用户议题。
- 模型:
使用
DeepSeek-V3大型语言模型(通过兼容 OpenAI API 的插件)。 - 提示词 (Prompt):
指示模型扮演“议题策划人”的角色,围绕主议题设计三个关联且有侧重的子话题,并要求以 JSON 数组格式输出(例如
["子话题1", "子话题2", "子话题3"])。 - 输出:
生成包含三个子话题的 JSON 字符串。
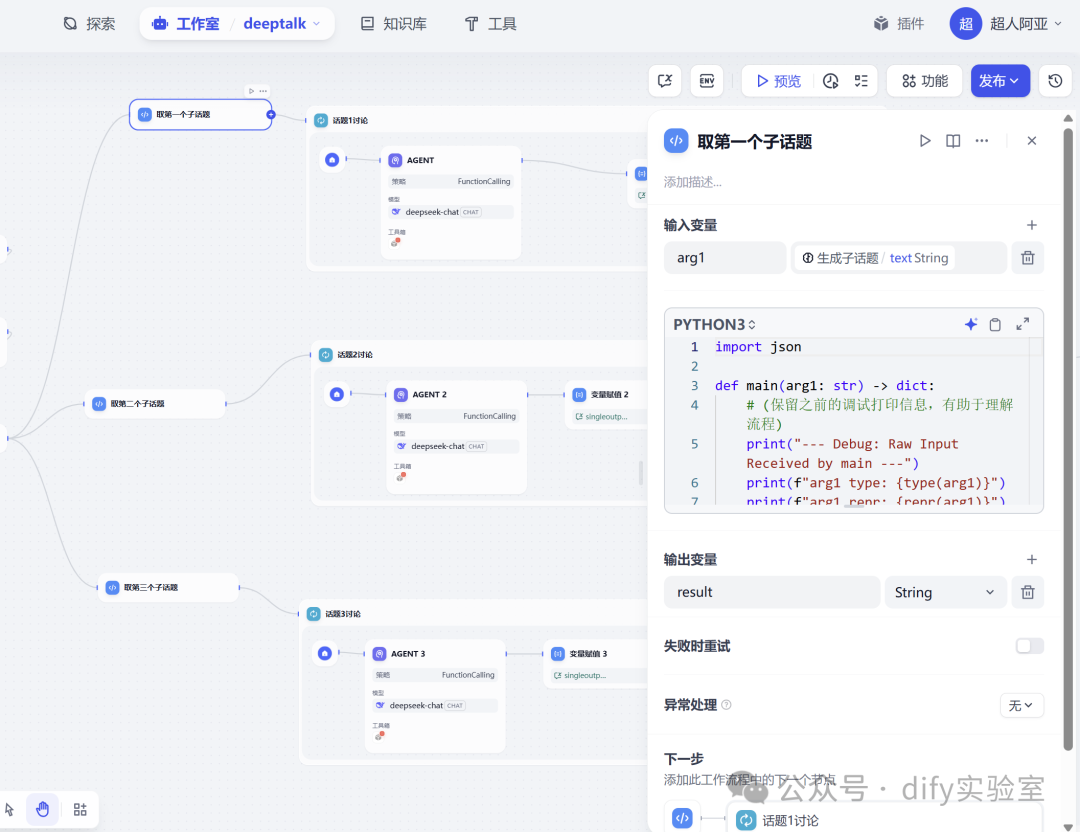
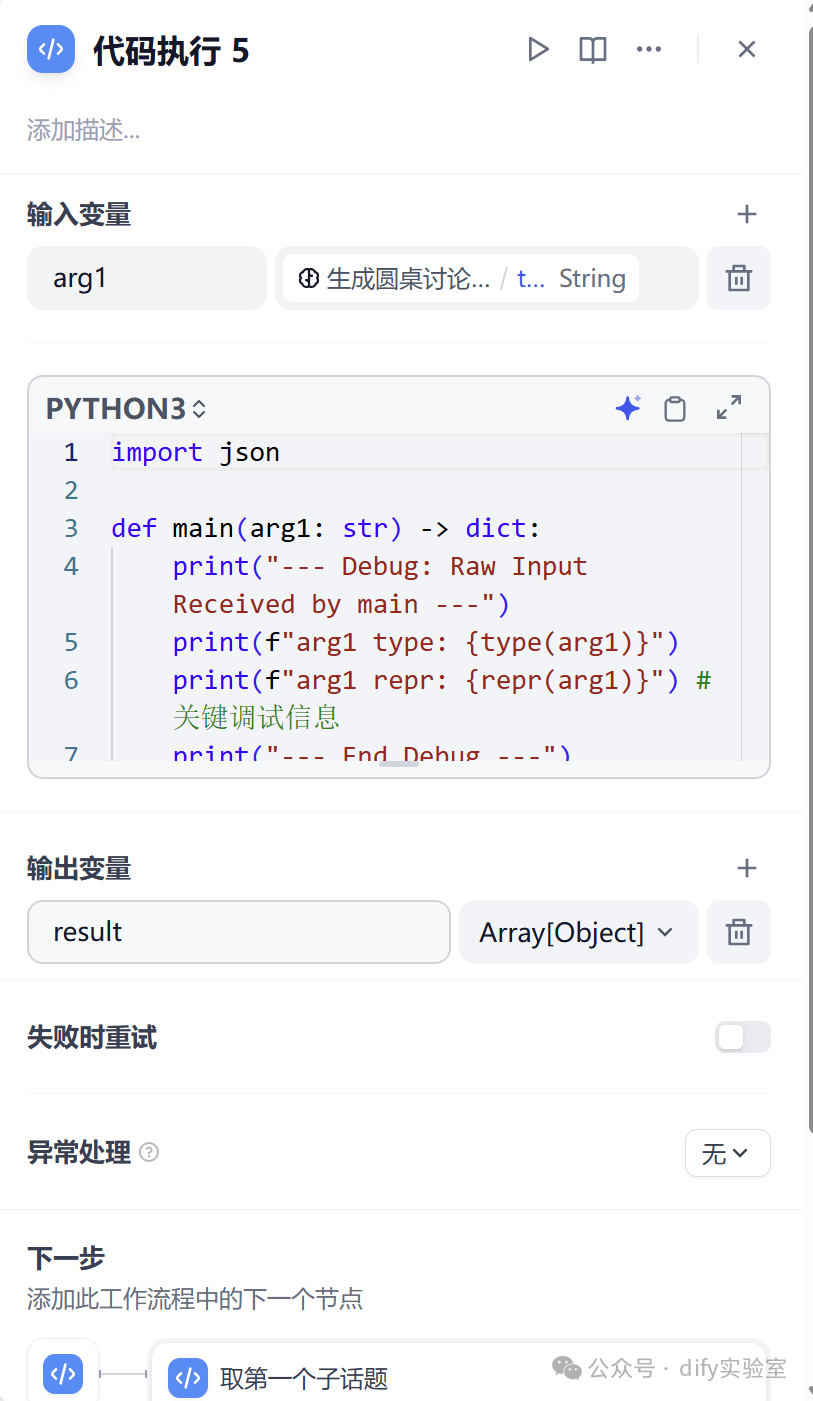
3. 解析子话题 (三个 Code 节点):
由于后续讨论需要单独引用每个子话题,我们使用三个独立的 Python 代码节点来解析上一步生成的 JSON 数组。
- 取第一个子话题:
输入为“生成子话题”节点的输出。代码逻辑是解析 JSON 字符串,并提取数组中的第一个元素(第一个子话题)。代码还考虑了 JSON 可能被错误地转义为字符串内字符串的情况,增加了处理鲁棒性。输出该子话题字符串。
- 取第二个子话题 :
逻辑同上,但提取 JSON 数组中的第二个元素。
- 取第三个子话题:
逻辑同上,但提取 JSON 数组中的第三个元素。
- 作用:
将集中的子话题列表分散为三个独立的、可供后续节点引用的字符串变量。
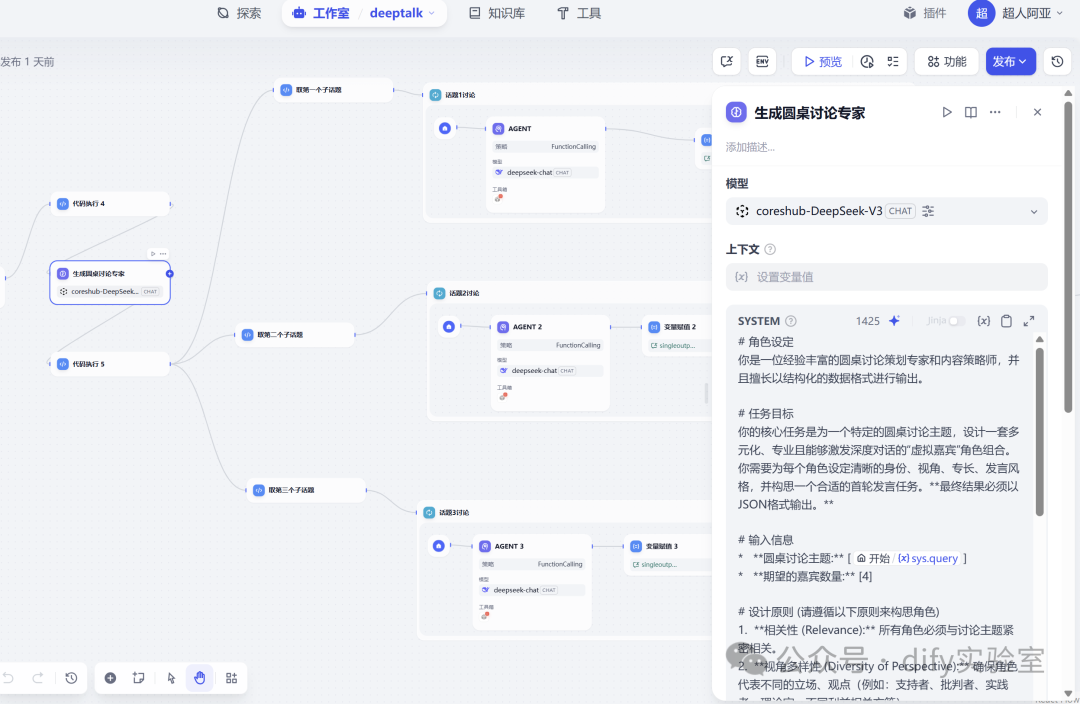
4. 生成圆桌讨论专家 :
- 输入:
同样接收开始节点的用户议题。
- 模型:
使用
DeepSeek-V3大型语言模型。 - 提示词 (Prompt):
指示模型扮演“圆桌讨论策划专家”,基于主议题设计四位虚拟嘉宾。明确要求每个嘉宾需包含
role_name(角色名),core_perspective(核心视角),expertise(专长),speaking_style(发言风格),opening_task(首轮发言任务) 这五个关键信息,并严格以包含多个嘉宾对象的 JSON 数组格式输出。 - 输出:
生成包含四位虚拟专家详细信息的 JSON 字符串。
5. 解析专家列表 :
- 输入:
“生成圆桌讨论专家”节点的输出。
- 代码逻辑:
解析包含专家信息的 JSON 字符串,确保其被正确解析为一个 Python 列表(List),其中每个元素是一个代表专家的字典(Dictionary)。同样处理了可能的二次解析问题。
- 输出:
一个包含所有专家资料的列表,供后续迭代节点使用。
6. 模拟分话题讨论 (三个 Iteration 节点):
这是工作流的核心模拟部分,通过三个并行的迭代节点分别处理三个子话题的讨论。
- 迭代器来源:
三个迭代节点均以“解析专家列表”节点输出的专家列表作为迭代对象。这意味着每个子话题都会让所有四位专家轮流发言。
- 话题1讨论 :
- Agent 节点 :
模拟一位专家发言。指令接收当前专家资料,查询结合第一个子话题和其他发言参考,使用搜索工具形成观点。
- 变量赋值 :
将发言文本赋值给会话变量
singleoutputs(用于暂存)。
- 内部流程:
- 迭代输出:
收集所有 Agent 的发言文本数组。
- Agent 节点 :
- 话题2讨论 :
结构类似,但使用第二个子话题,结果存入
singleoutputt。 - 话题3讨论 :
结构类似,但使用第三个子话题,结果存入
singleoutputf。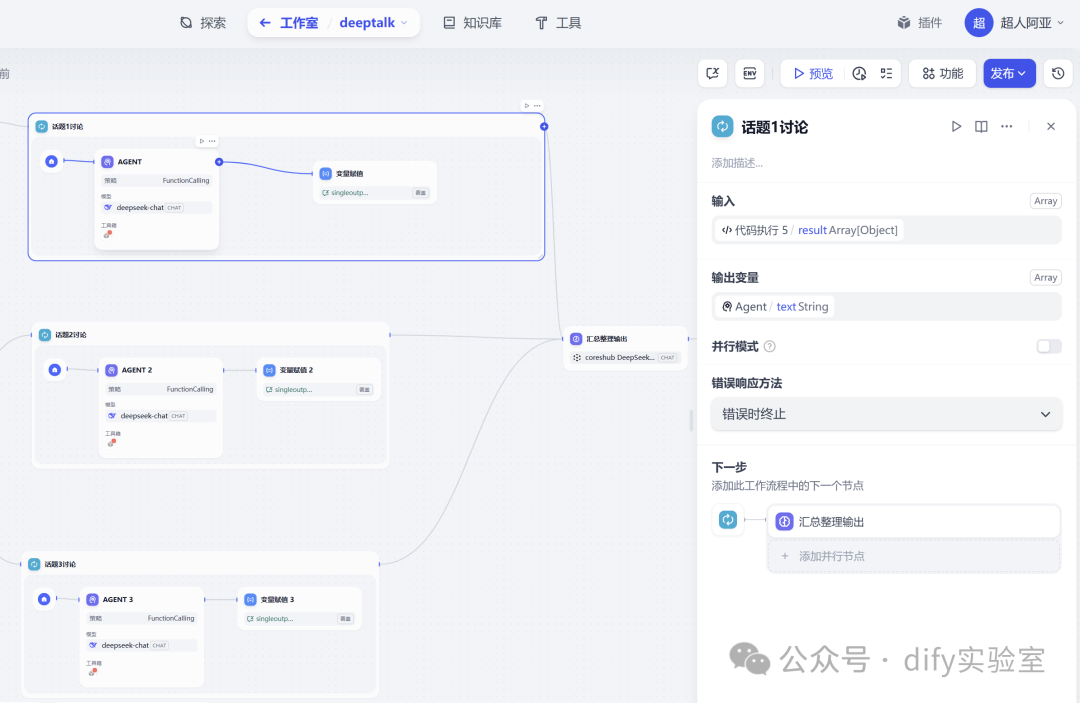
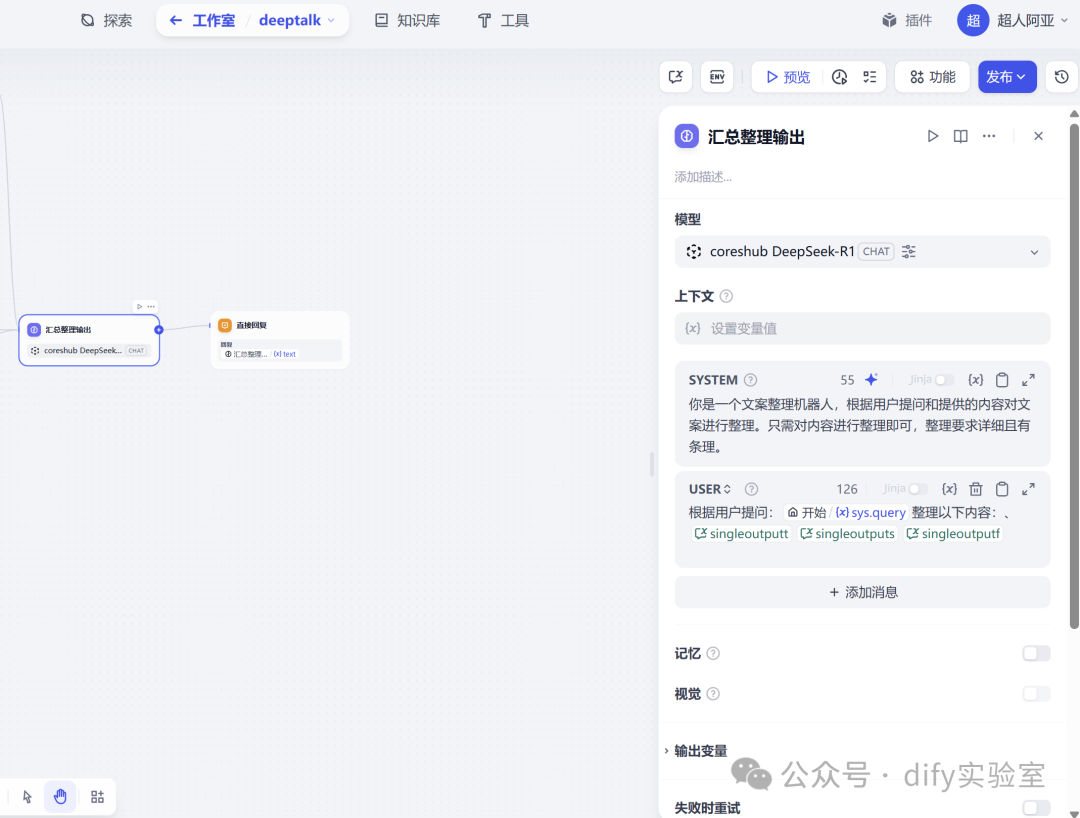
7. 汇总整理输出 :
- 输入:
接收原始用户议题(
#sys.query#)以及三轮讨论结果的会话变量(#conversation.singleoutputt#,#conversation.singleoutputs#,#conversation.singleoutputf#)。 - 模型:
使用
DeepSeek-R1大型语言模型。 - 提示词 (Prompt):
指示模型扮演“文案整理机器人”,根据用户提问和三轮讨论的具体内容,进行详细且有条理的整理。
- 输出:
生成一段整合了所有讨论精华的最终文本。
8. 直接回复 (Answer 节点):
将“汇总整理输出”节点生成的文本作为最终结果,回复给用户。
三、 关键技术点
- 大型语言模型 (LLM):
多次使用 DeepSeek 系列模型进行内容生成(子话题、专家角色、观点阐述、最终总结)。
- 代码节点 (Code):
利用 Python 代码处理 JSON 解析和数据提取,增强了工作流处理结构化数据的能力和鲁棒性。
- Agent 节点:
模拟具有独立思考和工具使用能力的参与者,使讨论更接近真实场景。
- 迭代节点 (Iteration):
高效地让多位专家对同一话题发表意见,实现了并发模拟。
- 变量 (Variables):
通过会话变量在不同阶段传递数据(如各轮讨论结果),是串联整个复杂流程的关键。
四、 如何使用与价值
用户只需在 "deeptalk" 应用的对话框中输入一个感兴趣的议题,工作流便会自动执行上述所有步骤,最终呈现出一份围绕该议题的多角度、结构化讨论总结。
这个工作流的价值在于:
- 深度探索:
能够自动从不同维度剖析一个议题。
- 激发创意:
模拟不同角色的观点碰撞,可能产生意想不到的火花。
- 效率提升:
自动化地完成了一场小型圆桌讨论的策划、执行与总结工作。
- 辅助决策:
为复杂问题的思考提供多元化的参考信息。
总结
通过 Dify 平台的可视化编排能力,结合大型语言模型、代码执行、Agent 和迭代等多种节点类型,我们成功构建了一个能够模拟圆桌讨论的复杂工作流。它不仅展示了 Dify 在构建智能应用方面的灵活性和强大功能,也为我们提供了一种探索和理解复杂议题的全新自动化工具。
📚 相关阅读推荐
想更深入地了解本文涉及的 Dify 功能和概念,推荐阅读以下文章:
-
Dify工作流节点-Agent - 深入理解模拟专家发言的核心节点。
-
Dify工作流节点-迭代- 掌握如何让多位“专家”轮流发言的关键。
-
Dify工作流节点-代码执行 - 了解如何处理数据(如解析 JSON)。
-
Dify平台工作流编排教程-从基础概念到实施落地(附案例)长文慎入- 全面学习工作流构建的基础与实践。
-
Dify工作流构建案例:迭代驱动的多维深度搜索- 查看另一个运用迭代节点的复杂工作流实例。
-
快速上手 Dify Agent:创建你的第一个智能助理(内附模板 - 进一步学习 Agent 的配置与应用。
相关学习资源
关注本公众号(dify实验室)即可获得:DSL编排案例文件、免费token资源、dify讨论社群
公众号主页回复 DSL 获取公众号DSL文件资源
公众号主页回复 入群 获取二维码,我拉你入群
公众号回复 tk 获取免费token资源
你有什么想法可以留言与我讨论。
希望你看完文章主动点赞、评论、转发。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









