







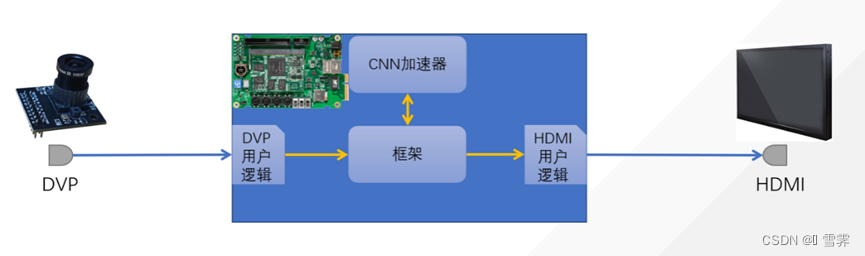
1 系统架构分析
整体上,首先设计一个FPGA模块来解析DVP摄像头的时序信号,完成图像预处理(对图像进行缩放和剪裁,数据归一化,将RGB图像转换为灰度图),使用赛方提供的ssd_detection模型(对其剪枝、量化使模型轻量化)和cnn加速器对输入图像的每一帧进行推理,并将推理结果叠加到原视频流,通过PL端HDMI接口进行输出。
2 关键技术分析
2.1 demo融合(叠加推理结果到图像上)
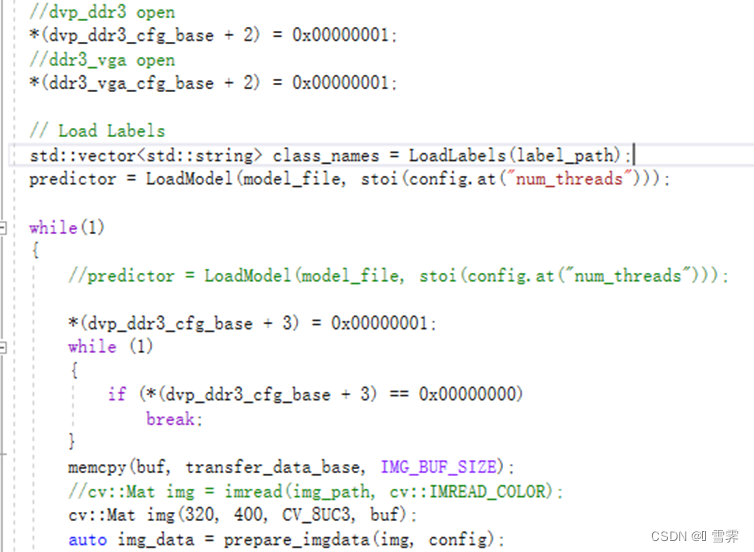
(1)在ssd_detection.cc文件中重新编写RunModel函数,该函数具有以下功能:
①将dvp_ddr3和ddr3_vga的start_statu分别置为1,使两者的IP工作状态寄存器使能;
②PL端接收原始视频流的一帧图像,将图像数据存储到buf中
③对图像进行预处理和推理,将推理结果(例如边界框、类别标签等)绘制到原始视频流上;
④利用双buffer机制,轮流输出叠加后的视频流,通过HDMI显示。
(2)提升点
①将LoadModel函数的调用放在while循环外面,即在视频检测过程中只加载一次模型;
②设置一个标志flag,用于只在第一帧图像推理时实现warm up过程,减少每次循环推理刷新的时间,进而提升hdmi的速度。
(3)部分代码如下:

2.2 优化PL端cnn加速器
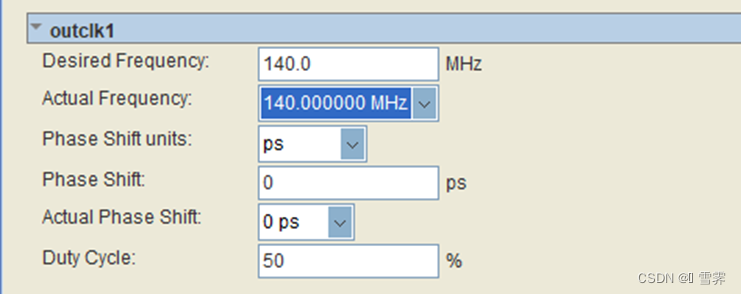
在quartus工程中修改PLL intel FPGA IP的cnn加速器的时钟频率,由50MHz修改为140MHz,可以较大幅度提高推理速度,推理时间由模型量化后的630ms可以提升到350ms,进而也可以提高HDMI的有效刷新速率。
2.3 对输入数据重排进行优化
删除InputRearrange函数中对数组dout进行清零的部分代码,该段代码是在数据重排后进行初始化操作,没有必要进行,很大程度上浪费了推理时间,删除后input_organize_time由原来的60多ms降低为30多ms。
操作如下所示:

2.4 图像后处理非极大值抑制
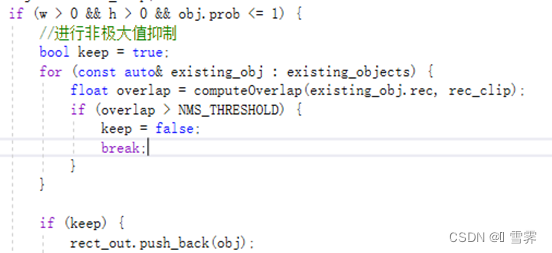
官方提供的代码在处理检测结果时,可能会出现重复绘制同一物体的情况,因为在循环中对data指针的处理没有考虑不同物体之间的关联。从数据存储结构的角度处理这个问题,需要对代码进行修改,以确保每个物体只绘制一次。
在代码优化的过程中使用了非极大值抑制的方法(Non-Maximum Suppression, NMS),NMS是一种常用的方法,用于去除冗余的检测框,只保留置信度最高的框。下面是修改后的部分代码,添加了NMS的过程:

2.5 修改common.h
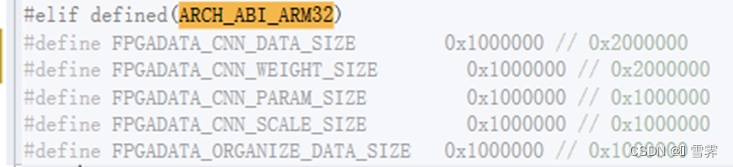
将FPGADATA_CNN_DATA_SIZE和FPGADATA_CNN_WEIGHT_SIZE由0x2000000改为0x1000000,没有发生内存越界,模型的第一次推理时间可以减少200ms,进而HDMI有效刷新速率也相应提升。
2.6 对AI框架进行深度优化
2.6.1 模型压缩
(1)网络剪枝:
我们采⽤基于敏感度的卷积通道裁剪,即对卷积⽹络的通道进⾏⼀次剪裁。剪裁⼀个卷积层的通道,是指剪裁该卷积层输出的通道。卷积层的权重形状为 [output_channel, input_channel, kernel_size, kernel_size] ,通过剪裁该权重的第⼀维度达到剪裁输出通道数的⽬的。实际剪裁时考虑到每层通道的敏感度,在验证集上测试精度得到敏感度,将敏感度低的剪裁掉来压缩模型。
模型剪枝的主要流程如下:首先训练⼀个性能较好的原始模型。原模型⽹络参数量较⼤,推理速度较慢;然后判断原模型中参数的重要程度,去除重要程度较低的参数;接着在训练集上微调,尽量避免由于⽹络结构变化而出现的性能下降;之后判断模型⼤小、推理速度、效果等是否满⾜要求,不满⾜则继续剪枝。
针对MobileNet_v1⽹络结构,⾸先调⽤paddle.summary()函数计算剪枝之前的模型相关信息,返回模型的详细参数量Params和Flops。移除模型中的冗余参数或层,降低模型复杂度。
(2)模型量化
在深度模型训练和推理过程中,我们最常使⽤的是32bit浮点型精度。但是⾼⽐特意味着模型的体积更⼤,推理速度更慢,硬件资源的消耗更多。这对于部署在计算资源和存储资源有限的边缘设备上是很不友好的。通过使⽤更低⽐特的精度,在尽量保持原模型效果的同时,获得尺⼨更小、推理速度更快、硬件资源占⽤更少的模型是理想的解决⽅案。量化过程不可避免的会带来模型精度的损失,为了能够尽量保持原模型的精度,通常会对量化后的模型做fine tuning,或者进⾏重新训练。这种⽅式称作“训练感知量化”。
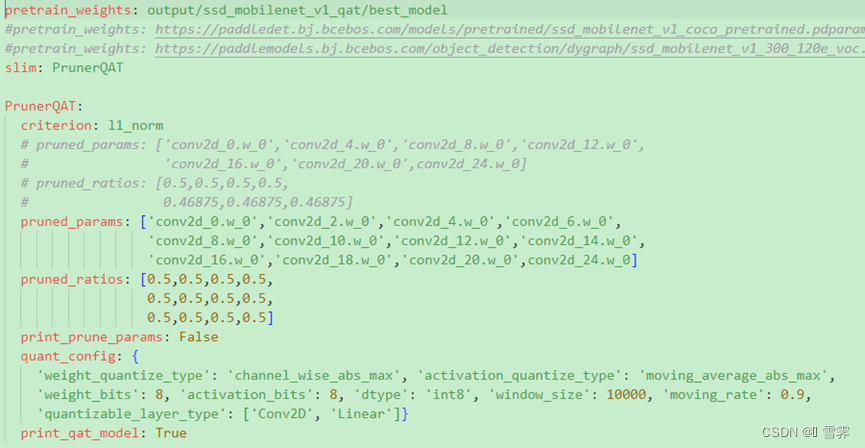
针对该项⽬,我们选择在线剪枝+量化训练⽅法,通过使用PaddleDection2.6的剪枝工具(位于./ppdet/slim/prune.py),使用比赛官方提供的训练方法,首先利用3个原版的py脚本(layers.py,ssd_head.py,quant.py)进行全精度模型训练,然后替换这3个py脚本,使用自己编写的yml文件中的PrunerQAT类剪枝后添加量化节点进⾏模型剪枝量化。
FLOPs before pruning: 5005271.424GFLOPs
FLOPs after pruning: 1810391.424GFLOPs; pruned ratio: 0.6383030467999651
yml文件内容如下所示:
2.6.2 模型加速
模型融合:将多个相邻层(例如卷积层和激活层)融合成一个操作,减少运算次数。
2.6.3 测试和部署
我们的模型部署流程主要分为两个阶段:
(1)模型训练阶段:主要解决模型训练,利⽤标注数据训练出对应的模型⽂件。⾯向端侧进⾏模型设计时,需要考虑模型⼤小和计算量。
(2)模型部署阶段:剪枝量化完成后成功部署。
2.7 解析DVP时序获取帧图像过程
我们自行用Verilog语言设计了一个PL端的模块dvp_capture,该模块支持RGB888和RGB565两种数据格式,对于不同的数据格式通过修改DVP_DATA_FORMAT参数的定义即可实现对应的支持。支持宽为1365以内、高为4095以内的任意分辨率的图像输入。
(1)主要信号:
iRST_n(复位信号):对整个模块进行复位。
CAM_PCLK(像素时钟):用于同步数据传输。
CAM_HREF(水平参考):指示水平有效数据。
CAM_VSYNC(垂直同步):指示新帧的开始。
CAM_D(图像数据):输入图像数据。
capture_en(模块使能):控制dvp_capture模块工作。
capture_f:帧计数器输出。
capture_h_szie:列计数器输出。
capture_v_size:行计数器输出。当读取的数据格式为RGB888时,capture_h_szie = 行宽*3;当读取的数据格式为RGB565时,capture_h_szie = 行宽*2。
rx_data:输出图像数据。当读取的数据格式为RGB888时,rx_data= {16'b0, cam_d_3},延迟到CAM_D输入后的第四个时钟上升沿输出,每个时钟周期输出一个rx_data,按顺序循环输出一个像素的R、G、B其中一色信息;当读取的数据格式为RGB565时,rx_data= {rx_data_red, 3'b000, rx_data_blue, 3'b000, rx_data_green, 2'b00},每两个时钟周期输出一个rx_data,包含一个像素的RGB三色信息。
(2)解析DVP时序:
以CAM_PCLK作为时钟对摄像头数据进行捕获并解析,整体使用状态机实现。
当检测到CAM_VSYNC信号为高电平时,表示上一帧的结束和新一帧的开始。输出行计数器的值和帧计数器的值,重置行计数器和列计数器。帧计数器加一(从第一帧结束时开始)。
当检测到CAM_HREF信号为高电平时,表示当前行的数据有效,递增列计数器。
在CAM_HREF为低电平期间,输出列计数器的值,并重置列计数器,行计数器加一。
(3)仿真测试:
A.输入数据格式为RGB888,分辨率为400*320,仿真结果如下:
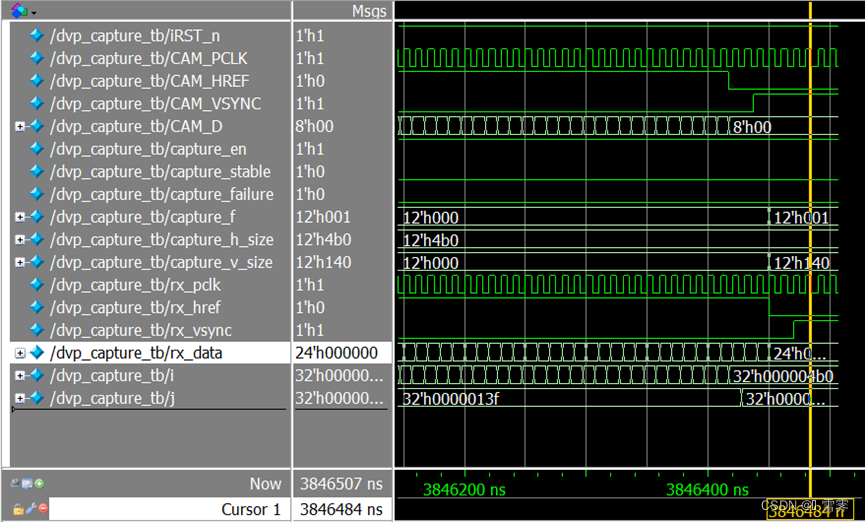
其中,在一帧的输入结束后,capture_v_size输出为12’h140,转化为十进制为320,与预期一致。capture_h_szie输出为12’h4b0转化为十进制为1200,与预期一致。rx_data的低八位均为延迟四个时钟周期的CAM_D,与预期一致。
B.输入数据格式为RGB565,分辨率为500*300,仿真结果如下:
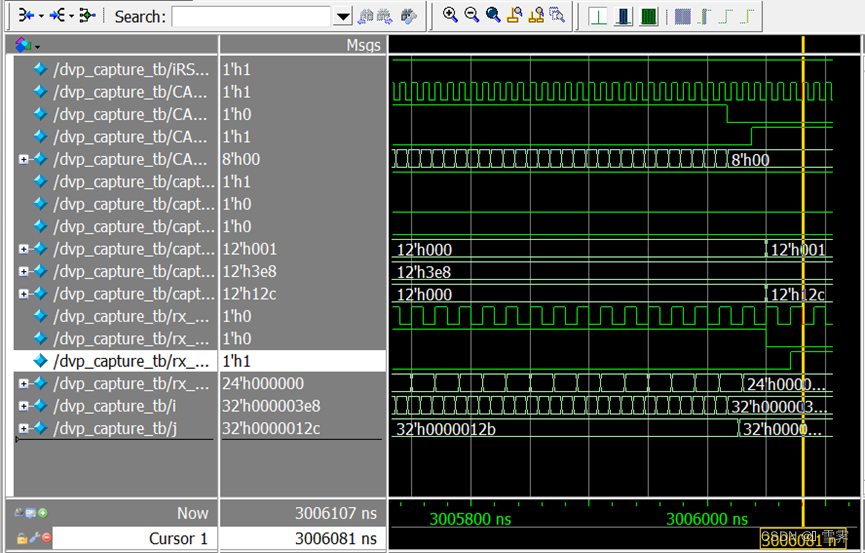
其中,在一帧的输入结束后,capture_v_size输出为12’h12c,转化为十进制为300,与预期一致。capture_h_szie输出为12’h3e8转化为十进制为1000,与预期一致。rx_data={rx_data_red, 3'b000, rx_data_blue, 3'b000, rx_data_green, 2'b00}与预期一致。
C.结论:
dvp_capture模块可以正确实现其设计预期的功能,即从dvp接口捕获并解析视频信号,输出视频像素数据、画面的分辨率(宽和高)、已捕获的帧数。其支持数据格式RGB888和RGB565,并支持宽为1365以内、高为4095以内的任意分辨率。
(4)说明:
由于使用signal tap logic analyzer抓取运行程序的开发板上的信号报错,导致无法抓取波形,我们没有搞清楚所有dvp_ddr3模块所有接口的交互逻辑,故只实现了部分功能并完成仿真测试,最后没有部署到开发板上。
2.8 从ddr3读取数据输出到vhdmi
我们自行用Verilog语言设计了一个PL端的模块ddr3_vga,该模块的功能是从ddr3中读取视频数据,并按照vga时序要求输出RGB888格式的视频信号。
- 主要信号:
rst_n(复位信号):对整个模块进行复位。
clk(输入时钟):50MHz的输入时钟。
avl_rdata(读数据):从ddr3读取的视频数据。
avl_addr(地址信号):从ddr3读取的视频数据的地址。、
avl_be(字节使能):byteenable,用于使能读数据的指定字节。
avl_read_reg(读使能):使能从ddr3读取的操作。
avl_size(突发长度):本次使能从ddr3读取的数据的个数。
vga_clk(输出时钟):输出vga的时钟。
vga_de(输出数据使能):使能输出的vga_rgb数据。
vga_rgb(输出视频数据):并行输出rgb888格式的视频数据。
vga_vsync(垂直同步):指示新帧的开始。
- 设计思路:
输出分辨率为400*320的帧率为30fps的视频,每秒所需的最小时钟周期数为400*320*30=3840000,已知赛方提供的黄金工程中,ddr3_vga模块的输入时钟clk频率为50MHz,考虑到为满足最小时钟周期数和留出足够的间隔时间以满足vga时序要求,设计输出时钟vga_clk的频率为12.5MHz。黄金工程中ddr3_vga模块从ddr3读取数据的端口avl_rdata位宽为128,输出端口vga_rgb位宽为24,故设计的ddr3_vga模块也沿用此位宽,其中,vga_rgb并行输出rgb888格式的视频数据,avl_rdata仅用低96位(通过设置avl_be字节使能信号实现),每次读取12字节的数据。每四个vga_clk时钟周期从ddr3读取一次数据,每个vga_clk时钟周期输出一次vga_rgb数据。
(3)仿真测试:
输出数据格式为RGB888,分辨率为400*320,帧数为每秒30帧,仿真结果如下:
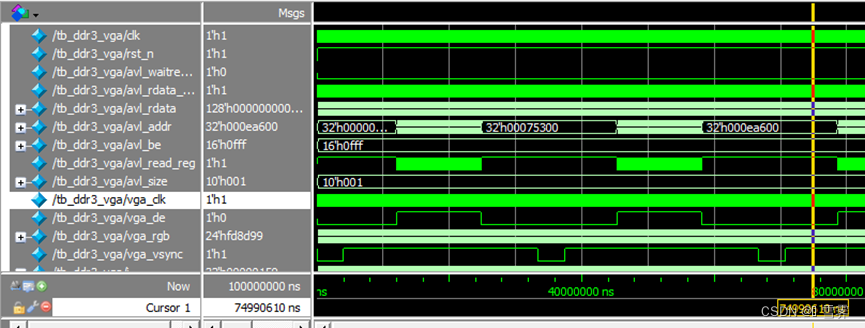
可以看到:
1、仿真结果中的vga_rgb与avl_rdata是对应的(一个avl_rdata的低96位对应连续的四个vga_rgb)。
2、输出的信号是满足vga时序要求的,vga_vsync和vga_de之间无论是拉高还是拉低都留出了足够的间隔时间。
3、每帧的时间与每秒30帧的设计目标相符。
结论:
ddr3_vga模块可以正确实现其设计预期的功能,即从ddr3中读取视频数据,并按照vga时序要求输出RGB888格式的视频信号,且每帧的时间与每秒30帧的设计目标相符。
(4)说明:
由于使用signal tap logic analyzer抓取运行程序的开发板上的信号报错,导致无法抓取波形,我们没有搞清楚所有ddr3_vga模块所有接口的交互逻辑,故只实现了其功能并完成仿真测试,最后没有部署到开发板上。
3 性能分析
1. 对赛方提供的视频中10副缺陷样本进行推理,全部推理正确,准确度达到100%,并在hdmi外设输出。
2. 在最新版nna上部署,没有经过处理的原模型推理时间(inference_time)为660ms,经过量化处理后可以达到630ms;经过PL端优化(提升cnn时钟的频率)和对common.h修改后,推理时间可以达到340ms,上下浮动1ms;对输入数据重排进行优化后,可以减少30ms;对ssd_mobilenet_v1进行0.638比例的剪枝和8bit量化后,推理时间可以达到149ms,最大浮动至161ms;
3. 由于图像帧数据传入后经预处理、推理预测、后处理后直接从hdmi输出,所以hdmi输出间隔时间和预处理、推理预测、后处理时间之和一致,为215ms,可以达到平均4.625帧(理论值应该为185ms,5.405帧,可能有网络传输延迟)。



















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









