







 本文介绍了卷积神经网络(CNN)的基本概念,包括局部感受野、权值共享、池化操作,以及网络架构的感性认识。通过实例展示了卷积层和池化层的工作原理,帮助理解CNN如何提取图像特征并减少数据量,为后续的深度学习实践奠定基础。
本文介绍了卷积神经网络(CNN)的基本概念,包括局部感受野、权值共享、池化操作,以及网络架构的感性认识。通过实例展示了卷积层和池化层的工作原理,帮助理解CNN如何提取图像特征并减少数据量,为后续的深度学习实践奠定基础。
最开始先把这篇笔记的博客和网络上面的资源先贴出来,方便大家查找。至于书在一开始的笔记中就已经提到过了,这里就不再反复写了。
http://neuralnetworksanddeeplearning.com/chap6.html
http://cs231n.github.io/convolutional-networks/
一.初识卷积网络结构
Ⅰ.概览
前面已经做过手写体识别的任务。之前我们只是使用了两层的全连接层,或者根据喜好多加几层。我更喜欢把这样的结构叫做多层感知机,即使用到了一些现代的权重初始化方式,更好的激活函数reLU等,我还是倾向于叫做多层感知机。
对于前面的这个手写体的识别任务,我们一开始就把图片展开成了一个一维的向量来做的(要是你有印象的话),虽然效果还行,但是却忽略了很重要的一点,那就是位置关系。

以这个喵的图片为例,我们的任务现在是想识别这只猫,按照之前的做法就是把这幅图片弄成一个一维向量,然后丢到网络里面去跑。但是人眼应该不是这样子的吧。虽然现在对于人眼识别东西原理还没有完全知道,但是你识别东西是先把你看到的弄成一个一维向量了去识别的?猫的鼻子下面有嘴巴,鼻子上面有眼睛,这都是很明确的位置关系,但是要是弄成了一维向量,那还有位置关系吗?也就没有了。
因此接下来就引入卷积神经网络以及卷积神经网络的一些基本概念:
局部感受野(local receptive fields)
权值共享(Shared weights and biases)
池化(pooling)
Ⅱ.局部感受野(local receptive fields)
在讲局部感受野之前,首先要知道的是,这个中文名词看到很多地方都是这么翻译,所以就这么翻译了,我本人并不知道怎么翻译这个。你也可以叫做局部感知。要是都是不对你胃口,那就直接看英文就行了。
更重要的是我们不再需要将一幅图片做成一个一维向量了。比如你现在的输入是28x28,那就是28x28,或者当有颜色通道的时候,比如28x28x3,就是宽高都是28,有3个颜色通道。这个很简单很好理解。
没有图的话理解肯定是不是很直观的,这里开始搬图了。

从Deep learning 搬过来,上图就已经代表你的输入了,你原来是什么输入,不用再变成一维了,直接拿过来用就行了(可能有一些预处理什么的,但是不足以改变位置信息)
既然输入是上面这个样子了,这里就可以开始讲局部感受野了。有了输入之后,肯定要把输入连接到隐藏层的神经元了,这里应该怎么连接呢?还是像以前的全连接层那样每个输入都连接一个神经元?那肯定不是的,那样就和多层感知机没什么区别了。这里很大的一个改变就是采用了“可以滑动的窗口”。可以滑动的窗口在这里是一个非常不正规的名词,但是确是很通俗的。搬一张图片先感受一下。
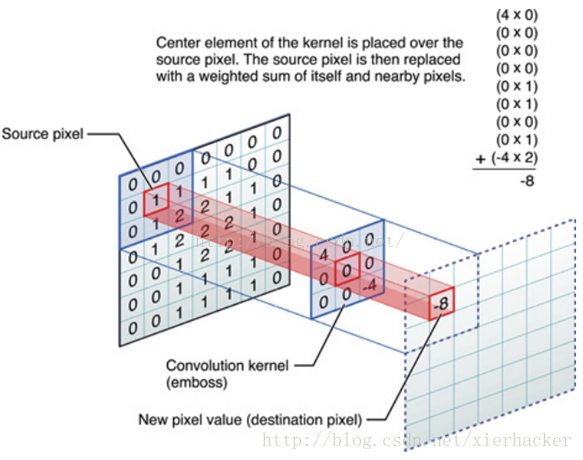
图中间的那个就是可以滑动的窗口了,他的作用是和输入相应的“感受域”下的像素做运算得到新的值。这个运算就是“卷积”运算了。图上面有详细的运算过程。实际上就是每个相应元素的值相乘,然后把得到的都加起来。很简单。
重点说明,中间的这个窗口的本质是其中的数字和一个偏置构成的,非常常见的是把这个窗口叫做滤波器或者卷积核,要是看见了这两个名词,要能够知道是什么意思。
这里说两点,第一点就是上图是对于一个颜色通道的输入做卷积操作的。你看到这里只有一个通道。但是并不是意味输入只能够是一个通道。常见的三通道也是可以的。这个后面会再讲,原理差不多,很简单。
第二点就是,你看到的那个窗口是可以滑动的,你可以指定每次的滑动步长。这里太抽象,直接上经典的动图看感性理解一下。
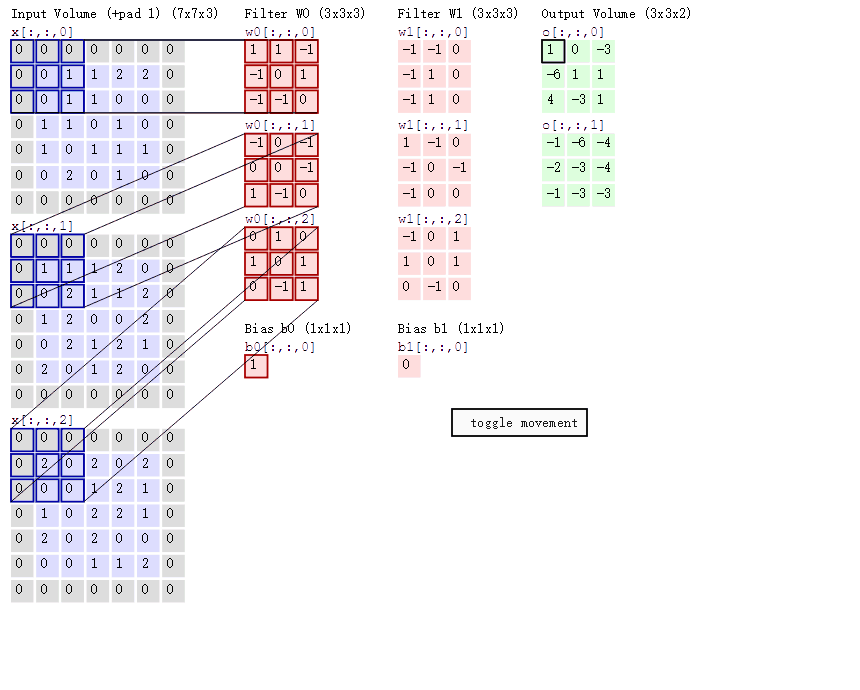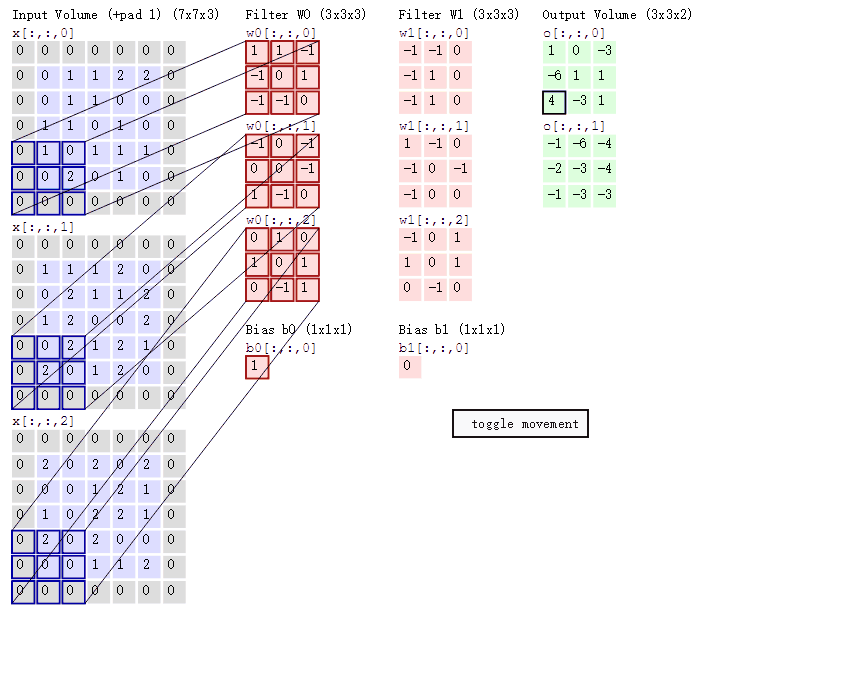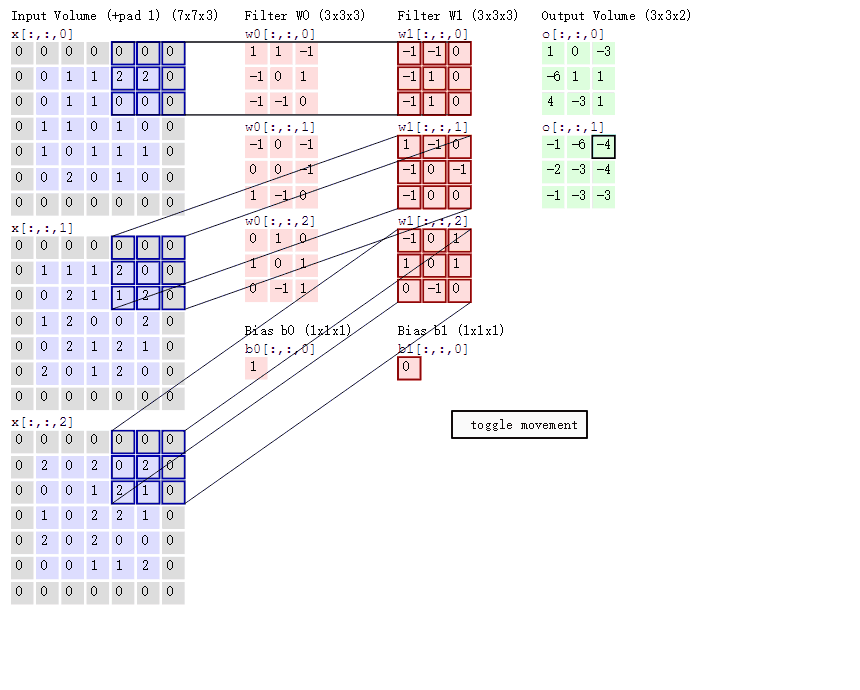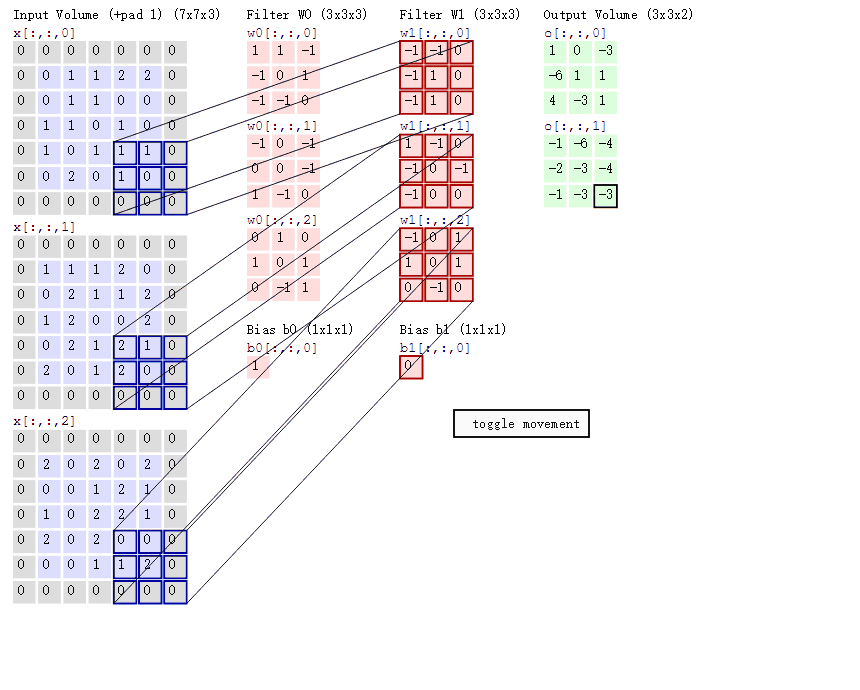
这幅动图是一个三个通道的输入,然后“滑动窗口”的维度是3x3x3,至于为什么会是这样的维度后面会详细来讲。在这幅图片里面你暂时能够得出的信息就是他的滑动的直观理解,窗口是怎么样子的。知道这些就够了。这一节的目标就是建立一个感性的认识。等先有个模型在脑子里面,后面量化就简单了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









