







1 引言
今年四五月,新模型不断发布。4.18 发布的是 Llama3,5.13 的 Gpt-4o,5.14 的 Gemini Flask 1.5。还有国内模型 5.7 发布 DeepSeek V2,5.15 的豆包模型,而且价格也越来越便宜。今天我们就来对比一下各家的性价比,以及降价背后的原因。
2 当前价格
以各个版本的 ChatGPT 作为基准,按照 7 的汇率进行计算,240517 收集的数据对比如下:
| Model | Input | Output |
|---|---|---|
| gpt-4o | $5.00 / 1M tokens | $15.00 / 1M tokens |
| gpt-4-turbo | $10.00 / 1M tokens | $30.00 / 1M tokens |
| gpt-4 | $30.00 / 1M tokens | $60.00 / 1M tokens |
| gpt-3.5-turbo-0125 | $0.50 / 1M tokens | $1.50 / 1M tokens |
| gpt-3.5-turbo-instruct | $1.50 / 1M tokens | $2.00 / 1M tokens |
| KIMI moonshot-v1-8k | $1.71 / 1M tokens (12元) | $1.71 / 1M tokens (12 元) |
| DeepSeekV2 | $0.14 / 1M tokens (1元) | $0.28 / 1M tokens (2 元) |
| 豆包 通用模型 Pro 32k | $0.11 / 1M tokens (0.8 元) | 没查到 |
3 模型效果
我们可以将模型简单地分为三个层级。
第一级以 GPT-4 为代表,包括最新的 Gemini,Claude,LLAMA3 400B 等模型。
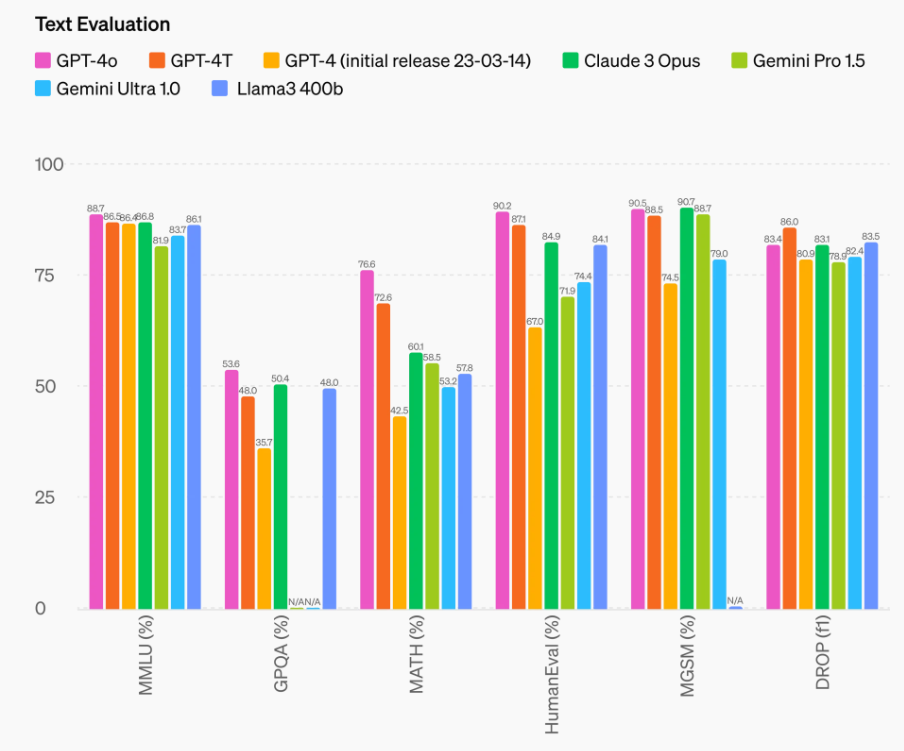
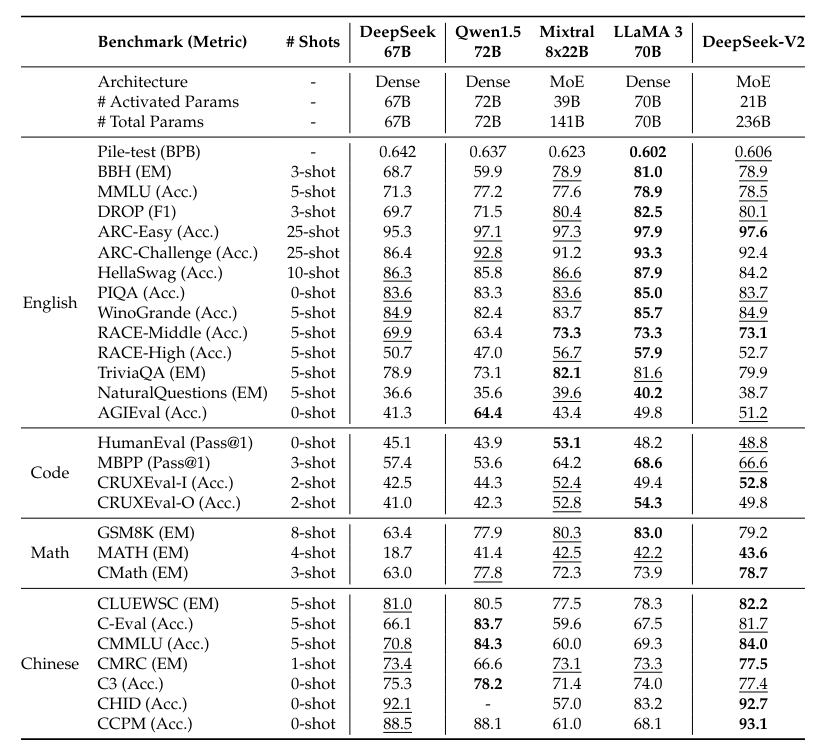
第二级以 LLAMA3 70B 为代表,包含了一系列与 LLAMA 架构类似的模型,以及多数国内模型。其性能基本上处于 GPT-3.5 到 GPT-4 之间。国内模型的优势在于对中文支持良好,但也常常对英文的支持不佳,导致了许多英文提示题无法直接使用,从而给开发带来更多负担。从论文中可以看到,这些模型效果也主要是与同级模型对比得出的。
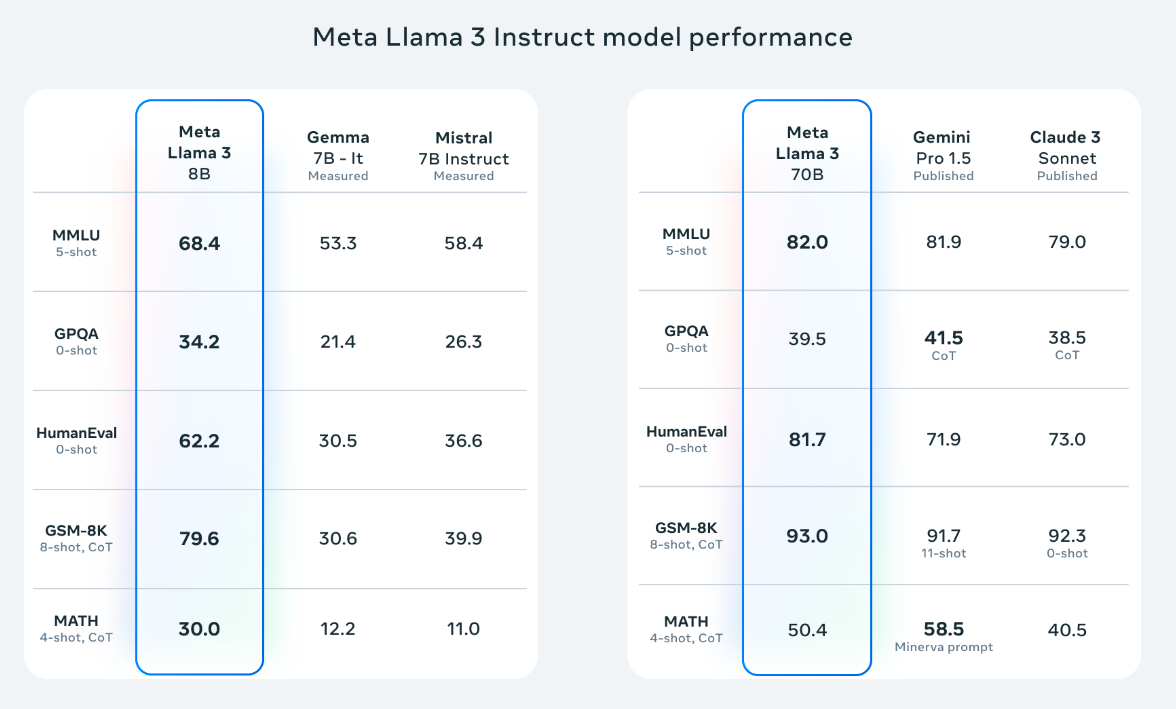
第三级以 LLAMA3 8B 为代表,其性能接近 GPT-3.5。更为经济实惠,可以在个人的消费级 GPU 上运行,效果一般,个人使用是不错的选择,但如果想用它开发产品,则需要大量的前处理和后处理,开发成本也不低。
LLAMA3 8B/70B 对比如下:
4 技术进步
这次的降价并非恶性竞争的结果,不可能用户使用越多越亏钱。这次降价主要是由于技术改进的推动。虽然大多数模型并未公开它们的核心优化算法,但我们仍可以从开源的 DeepSeekV2 论文以及微软最近发布的一篇让大模型降本增效的论文中窥见一二。
4.1 当前瓶颈
先复习一下 Transformer 架构注意力计算的原理:
Attention 机制的核心思想是通过查询 Q、键 K 和值 V 的匹配来计算加权和,以便模型聚焦于输入序列的相关部分。在 Transformer 模型中,对每个输入 token 都计算对应的 Q,K,V。通过提前计算并存储 K 和 V,可以提高计算效率和保持一致性。而同时随着上下文变长,层数变多,隐藏层维度增加,存储 KV 将占用大量内存。
4.2 DeepSeekV2
PLAINTEXT
1 2 3 4 5 6 7 | 英文名称: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model 中文名称: DeepSeek-V2:强大、经济高效的专家混合语言模型 链接: http://arxiv.org/abs/2405.04434v2 代码: https://github.com/deepseek-ai/DeepSeek-V2 作者: DeepSeek-AI 机构: DeepSeek-AI 深度探索公司 日期: 2024-05-07 |
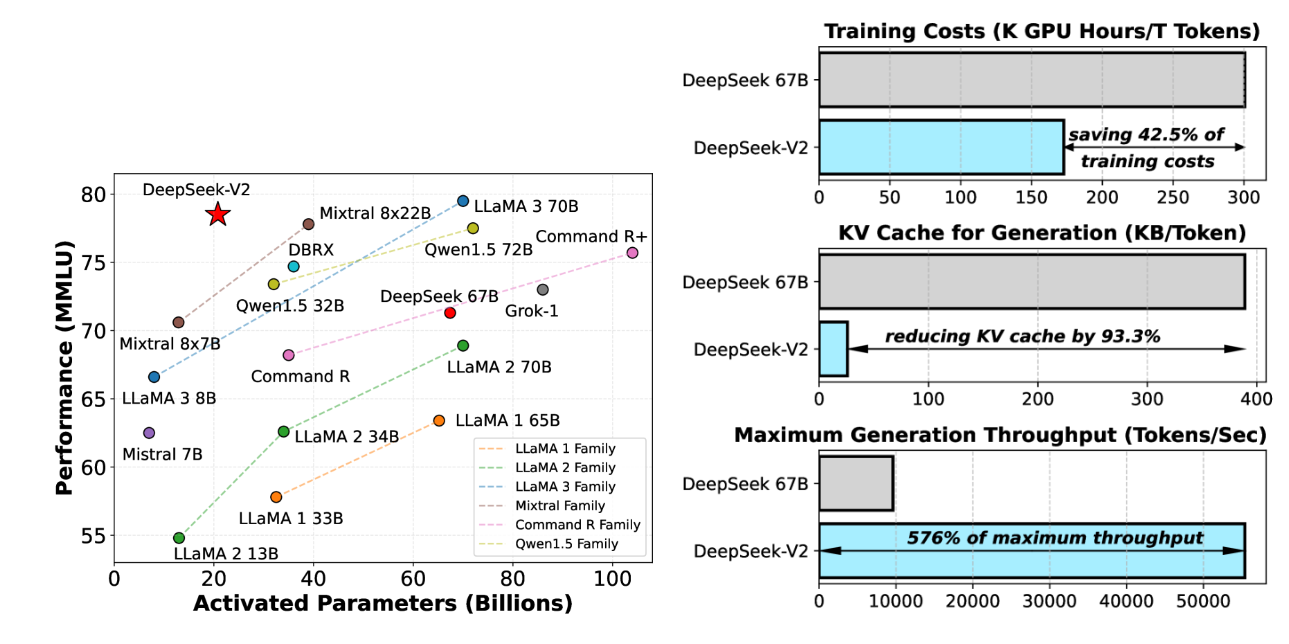
DeepSeekV2 的创新的架构,包括 Multi-head Latent Attention(MLA)和 DeepSeekMoE。MLA 通过将 Key-Value(KV)缓存显著压缩为潜在向量,减少了 GPU 内存占用;而 DeepSeekMoE 通过稀疏计算实现提升了计算速度。与 DeepSeek 67B 相比,DeepSeek-V2 表现更强,同时节省了 42.5% 的训练成本,将 KV 缓存减少了 93.3%,并将最大生成吞吐量提升了 5.76 倍。
4.3 YOCO
PLAINTEXT
1 2 3 4 5 6 | 英文名称: You Only Cache Once: Decoder-Decoder Architectures for Language Models 中文名称: 只缓存一次:用于语言模型的解码器-解码器架构 链接: http://arxiv.org/abs/2405.05254v2 作者: Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, Furu Wei 机构: 微软研究院, 清华大学 日期: 2024-05-08 |
微软和清华的论文 YOCO 提出了 Decoder + Decoder 架构,它与仅 Decoder 的 Transformer 类似,其特点是只缓存一次 Key-Value。架构包括两个主要组件,分别是 Self Decoder 和 Cross Decoder。Self Decoder 负责有效地编码全局键值(KV)缓存,这些全局键值(KV)被交叉解码器重复使用,
实验结果显示,与 Transformer 相比,YOCO 在扩大模型大小和训练令牌数量的不同环境下,都能有效降低 GPU 内存需求、预填充延迟和吞吐量。

从而有效地降低了其内存复杂度:
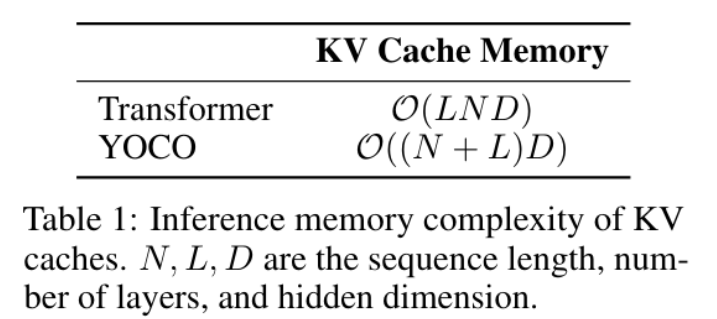
|300
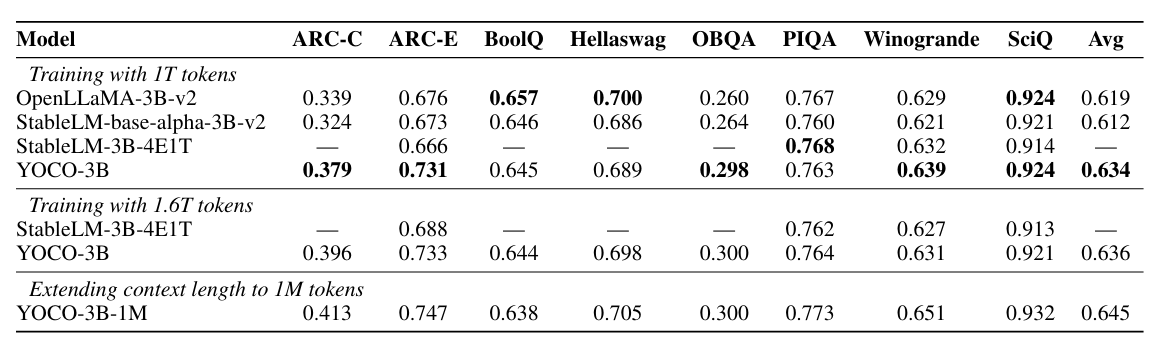
架构修改之后也没有影响模型效果,实验效果还略有提升:
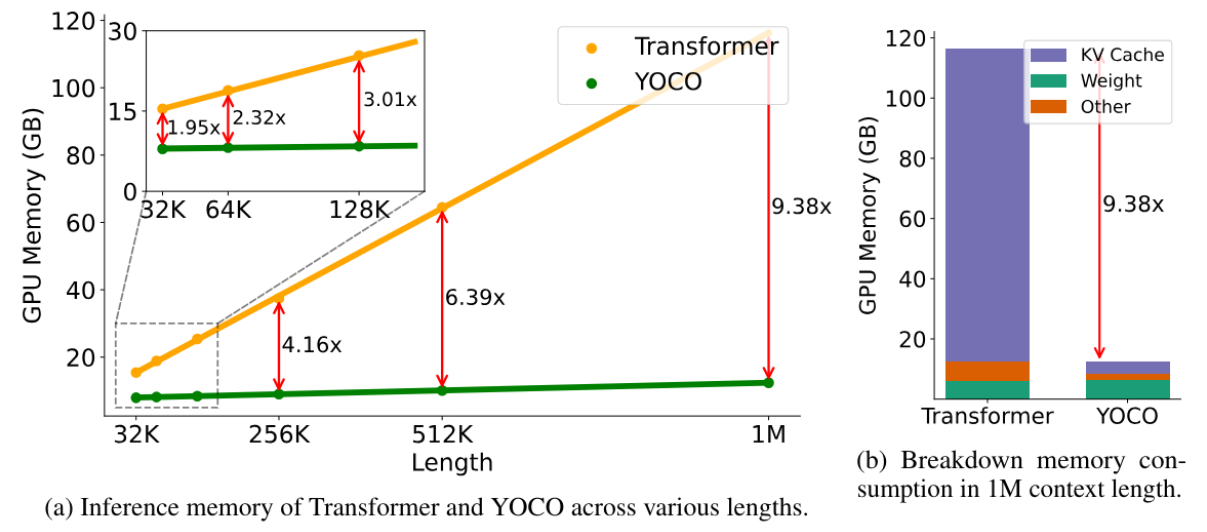
有效地优化了长下文的内存占用:
4.4 总结
这两篇论文都是五月初提交 arxiv 的,实验结果证明,改进 KV 存储后可以解决 GPU 内存的瓶颈问题,从而降低成本。这一方面证明了 Transformer 架构本身存在冗余,有优化的空间;另一方面,这也间接验证了 KV 是一个重要的优化方向。当然,还有其他很多优化方法可供选择。
5 展望
试想一下,如果这种优化方法在大多数大模型中都有效,那么许多约 70G 级别的模型就有可能在只有 10-20G 显存的机器上运行。这将大大提升本地模型的效果。公司或者个人只需花费一两万块钱,就能部署一个效果相当于 GPT-3.5~4 的 llama-70B 模型。当 AI 的使用成本仅限于电费,或者可以忽略不计时,是否还有必要使用大型公司的服务呢?这可能会引起行业布局的变化。















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









