







1. 数据预处理
1.1 数据增强
1.1.1 几何增强
原图:
image = cv2.imread('image.png')
gt = cv2.imread('label.png', 0)

- 水平翻转: 水平镜像图像有助于增加方向的不变性(例如,行人可以以不同的方向出现)。在自然场景下,不建议垂直翻转,因为物体的垂直外观在场景中增加了重要的一致性(例如,网络知道天空是由它的位置决定的),但是像遥感图像这种俯瞰图,是可以垂直翻转的。
image_flip = cv2.flip(image, 1) # 1代表水平翻转,0代表垂直翻转,-1代表对角翻转
gt_flip = cv2.flip(gt, 1)

- 平移: 移动图像会阻止CNN总是看到训练图像的相同位置,因此它不会总是从第一层产生相同的激活(移位不变性)。
# 定义平移矩阵
M = np.float32([[1, 0, 100], [0, 1, 0]])
# 变换公式:dst(x, y) = src(M11x + M12y + M13, M21x + M22y + M23)
image_shift = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
gt_shift = cv2.warpAffine(gt, M, (gt.shape[1], gt.shape[0]))

- 随机裁剪和缩放: 随机调整图像大小有助于模型看到每个对象的不同比例,并提高网络对不同图像分辨率的不变性。
h, w = image.shape[0], image.shape[1]
# 获取随机裁剪长度
crop_scale = np.random.randint(h//2, h) / h
crop_h = int(crop_scale * h)
crop_w = int(crop_scale * w)
h_begin = np.random.randint(0, h - crop_h)
w_begin = np.random.randint(0, w - crop_w)
image_crop = image[h_begin: h_begin+crop_h, w_begin:w_begin+crop_w, :]
gt_crop = gt[h_begin: h_begin+crop_h, w_begin:w_begin+crop_w]
# resize函数使用时dsize先是w再是h,正好相反
image_resize = cv2.resize(image_crop, (w, h))
gt_resize = cv2.resize(gt_crop, (w, h))

- 旋转: 将小的随机度旋转到图像会增加对可能在场景中出现轻微角度变化的对象的不变性。在遥感图像增强时,一般采用90度间隔旋转来模拟飞行方向的不同。

1.1.2 纹理增强
- 亮度和对比度: 物体在图像中的清晰度取决于场景照明和相机灵敏度。通过随机增加或减少图像亮度来增加输入图像的虚拟变化,改善了网络的照明不变性。对比度就是图像中最暗和最亮区域之间的分隔。通过随机增强来增加这个范围有助于增加对阴影的不变性,并且通常会提高网络在低光照条件下的性能。
from albumentations import (
Compose,
RandomBrightnessContrast
)
aug = Compose([RandomBrightnessContrast(brightness_limit=(0, 0.4), contrast_limit=(0, 0.4), p=1)])
augmented = aug(image=image, mask=gt)
image_bright_contrast = augmented['image']
gt_bright_contrast = augmented['mask']

- 色调 饱和度 明度(HSV): 色调的取值范围是0~360度,用来表示颜色的类别,其中红色是0度,绿色是120度,蓝色是240度。饱和度高,颜色则深而艳。亮度的用来表示颜色的明暗程度。
from albumentations import (
Compose,
HueSaturationValue
)
aug = Compose([HueSaturationValue(hue_shift_limit=20,
sat_shift_limit=30,
val_shift_limit=20,
p=1)])
augmented = aug(image=image, mask=gt)
image_hsv = augmented['image']
gt_hsv = augmented['mask']

- 运动模糊: 对图像进行模糊可以模拟部分拍摄场景的运动模糊,让网络对模糊图像的边界也具有较强的识别能力。
from albumentations import (
Compose,
MotionBlur
)
aug = Compose([MotionBlur(blur_limit=7, p=1.0)])
augmented = aug(image=image, mask=gt)
image_MotionBlur = augmented['image']
gt_MotionBlur = augmented['mask']

- 颜色抖动: 向每个RGB像素添加小的随机噪声有助于获得对一些相机失真的不变性。
from albumentations import (
Compose,
RGBShift
)
aug = Compose([RGBShift(r_shift_limit=20,
g_shift_limit=20,
b_shift_limit=20,
p=1.0)])
augmented = aug(image=image, mask=gt)
image_rgbshift = augmented['image']
gt_rgbshift = augmented['mask']

- 限制对比度的自适应直方图均衡化:
from albumentations import (
Compose,
CLAHE
)
aug = Compose([CLAHE(clip_limit=2,
tile_grid_size=(8, 8),
p=1)])
augmented = aug(image=image, mask=gt)
image_CLAHE = augmented['image']
gt_CLAHE = augmented['mask']

1.1.3 其他增强
- 超像素: 随机将图像上某个超像素块内的颜色替换为超像素的均值。
from albumentations import Compose
from albumentations.imgaug.transforms import IAASuperpixels
aug = Compose([IAASuperpixels(p_replace=0.1,
n_segments=500,
p=1)])
augmented = aug(image=image, mask=gt)
image_Superpixels = augmented['image']
gt_Superpixels = augmented['mask']

- 锐化: 增强图像细节。
from albumentations import Compose
from albumentations.imgaug.transforms import IAASharpen
aug = Compose([IAASharpen(p=1)])
augmented = aug(image=image, mask=gt)
image_Sharpen = augmented['image']
gt_Sharpen = augmented['mask']

- 透视变换:
from albumentations import Compose
from albumentations.imgaug.transforms import IAAPerspective
aug = Compose([IAAPerspective(p=1)])
augmented = aug(image=image, mask=gt)
image_Perspective = augmented['image']
gt_Perspective = augmented['mask']

1.2 标准化与归一化
1.2.1 min-max归一化:
- 公式:对数据的数值范围进行特定缩放,但不改变其数据分布的一种线性特征变换。
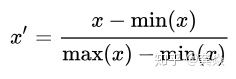
最常见的image = image / 255.0 就是min-max归一化的特例。
- 示例
import matplotlib.pyplot as plt
import cv2
import numpy as np
import seaborn as sns
image = cv2.imread('image.png')[:, :, 0]
min_ = np.min(image)
max_ = np.max(image)
new_image = (image-min_) / (max_-min_)
flat_image = np.reshape(image, -1)
flat_new_image = np.reshape(new_image, -1)
fig, ax = plt.subplots(1, 2)
sns.distplot(flat_image, ax=ax[0])
sns.distplot(flat_new_image, ax=ax[1])
plt.show()
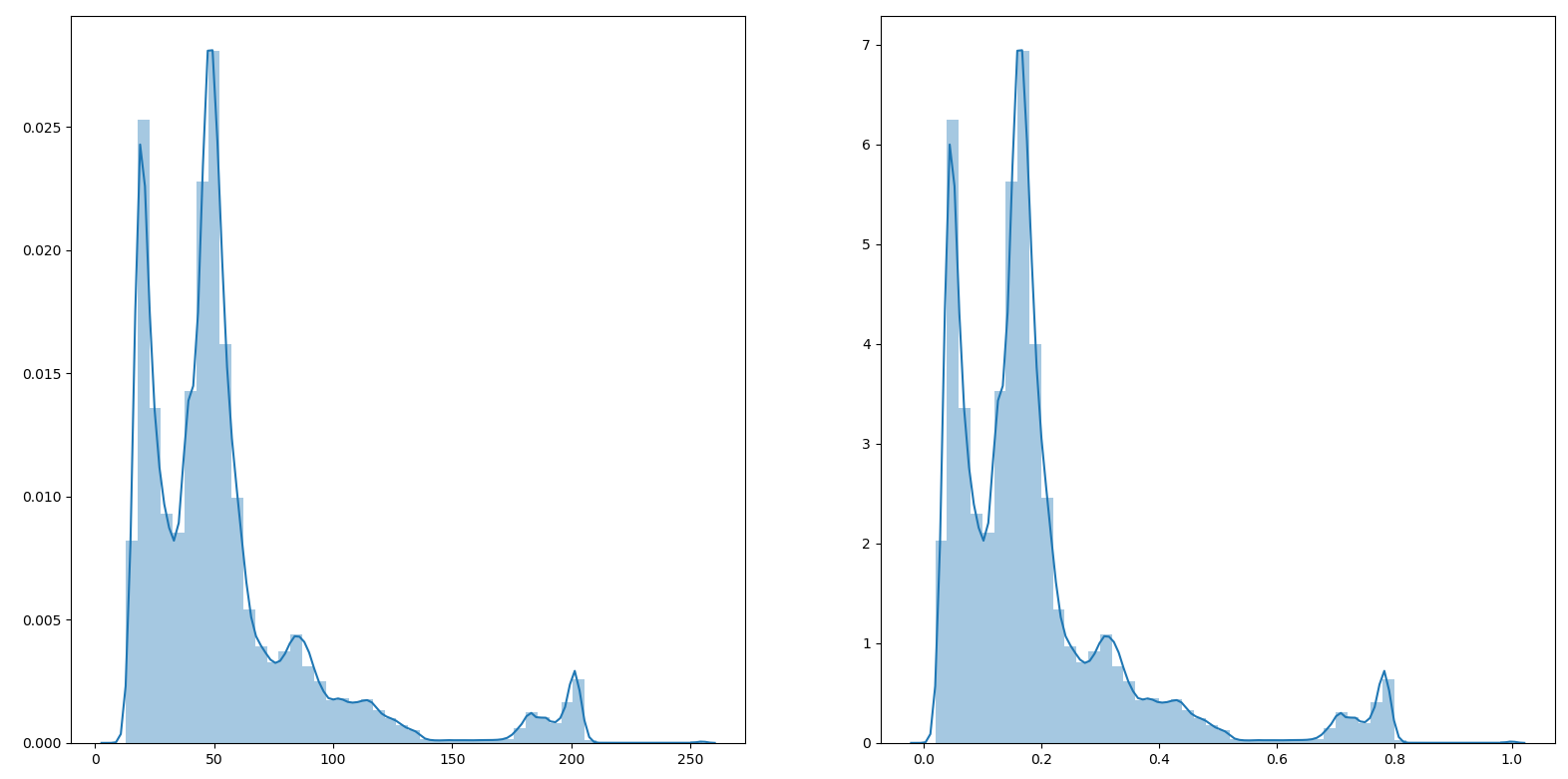
1.2.2 z-score 标准化
- 公式:将数值范围缩放到0附近, 但没有改变数据分布;
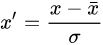
- 示例
import matplotlib.pyplot as plt
import cv2
import numpy as np
import seaborn as sns
image = cv2.imread('image.png')[:, :, 0]
mean_ = np.mean(image)
std_ = np.std(image)
new_image = (image-mean_) / std_
flat_image = np.reshape(image, -1)
flat_new_image = np.reshape(new_image, -1)
fig, ax = plt.subplots(1, 2)
sns.distplot(flat_image, ax=ax[0])
sns.distplot(flat_new_image, ax=ax[1])
plt.show()
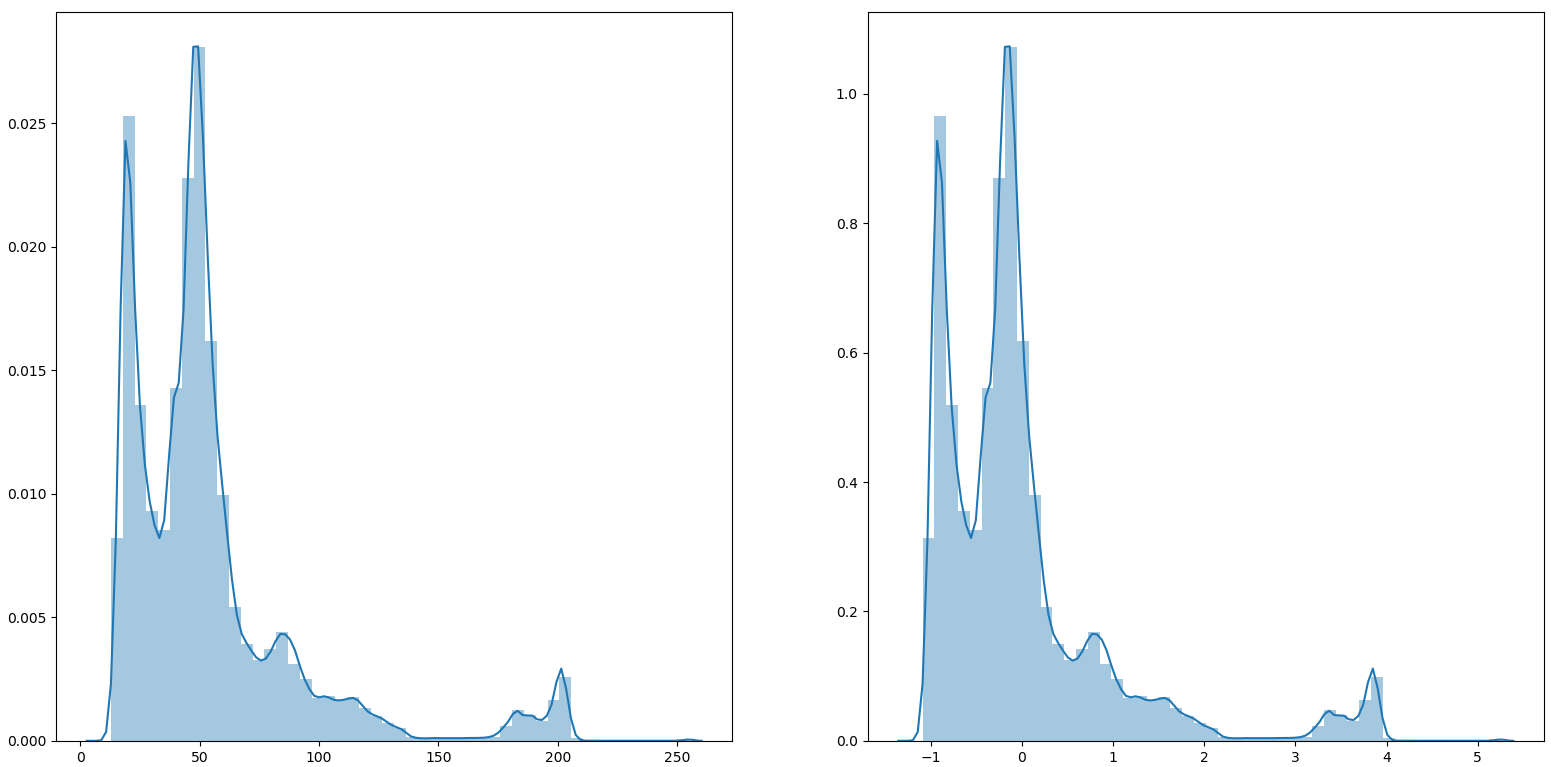
1.2.3 box-cox标准化
对数据的分布的进行转换,使其符合某种分布(比如正态分布)的一种非线性特征变换。
暂时放下,参考链接https://www.zhihu.com/question/20467170中对随机生成的指数分布的数据变换结果就是可以的,但是其他分布或者拉直的图像变换完结果就不对。
1.2.4 使用预训练模型
如果采用了imagenet数据预训练的模型,你的模型的预处理应与原始模型的训练相同对于[Keras模型](https://papers.nips.cc/paper/5347-how-transferable-are-features-in-deep-neural-networks.pdf /),应使用preprocess_input函数进行数据预处理,如下:
# VGG16
keras.applications.vgg16.preprocess_input
# InceptionV3
keras.applications.inception_v3.preprocess_input
# ResNet50
keras.applications.resnet50.preprocess_input
2. 模型结构
使用批量标准化的Keras模型可能不可靠。 当前Keras实施的问题在于,当批量规范化(BN)层被冻结时,它在训练期间继续使用小批量统计。但是当BN被冻结时更好的方法是使用它在训练期间学到的移动均值和方差。为什么?出于同样的原因,为什么在冻结图层时不应更新小批量统计信息:由于下一层未经过适当的训练,因此可能导致结果不佳。Keras模型从训练模式切换到测试模式时,这种差异导致模型性能显着下降。
3. 损失函数
4. 优化器
5. 学习率
预训练模型的学习率稍小一些
















 6352
6352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









