







一、创建环境
1. 加载 anaconda, 创建⼀个opennmmlab_mmsegmentation的conda环境。
# 加载anaconda
module load anaconda/2021.05
# 创建 python=3.7 的环境
conda create --name opennmmlab_mmsegmentation python=3.7
# 激活环境
source activate opennmmlab_mmsegmentation
2. 安装PyTorch & MMCV && mmengine
由于北京超算GPU资源为RTX3090, 因此加载的cuda版本需要大于等于11.1。使用 pip 安装的torch 不包括 cuda,所以需要使⽤ module 加载 cuda/11.3 模块。本教程使用的PyTorch版本1.10.0+cu113。
# 加载 cuda/11.3
module load cuda/11.3
# 安装torch
pip3 install install torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio==0.10.1+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
# 安装mmcv
pip install mmcv==2.0.0rc3 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html
3. 安装mmsegmentation
采用下载编译的方式安装mmdetection模块,要求编译器gcc版本大于5。由于超算上原本编译器版本低于5,因此需要module命令加载一个高版本的gcc,本教程指定gcc版本为9.3。
# # 加载 gcc
module load gcc/9.3
# 安装mmengine
git clone https://github.com/open-mmlab/mmengine.git
cd mmengine
pip install -e .
# 安装其它工具包
pip install opencv-python pillow matplotlib seaborn tqdm 'mmdet>=3.0.0rc1' -i https://pypi.tuna.tsinghua.edu.cn/simple
# git下载 MMSegmentation代码
git clone https://github.com/open-mmlab/mmsegmentation.git -b dev-1.x
# 源码编译安装
cd mmsegmentation
git checkout -b v1.0.0rc4
pip install -v -e .
二、创建数据集
1.下载数据集
# 进入mmsgementation目录
cd mmsegmentation
# 创建data目录
mkdir data && cd data
# 下载数据集
wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230130-mmseg/dataset/Glomeruli-dataset.zip
# 解压
unzip Glomeruli-dataset.zip
2.划分数据集
# 进入mmsgementation目录
cd mmsegmentation
# 创建脚本
vim split_data.py
# 执行数据划分
python split_data.py
split_data.py
import os
import random
# 获取全部数据文件名列表
PATH_IMAGE = 'data/Glomeruli-dataset/images'
all_file_list = os.listdir(PATH_IMAGE)
all_file_num = len(all_file_list)
# 随机打乱全部数据文件名列表
random.shuffle(all_file_list)
# 指定训练集和测试集比例
train_ratio = 0.8
test_ratio = 1 - train_ratio
train_file_list = all_file_list[:int(all_file_num*train_ratio)]
test_file_list = all_file_list[int(all_file_num*train_ratio):]
print('数据集图像总数', all_file_num)
print('训练集划分比例', train_ratio)
print('训练集图像个数', len(train_file_list))
print('测试集图像个数', len(test_file_list))
os.mkdir('data/Glomeruli-dataset/splits')
with open('Glomeruli-dataset/splits/train.txt', 'w') as f:
f.writelines(line.split('.')[0] + '\n' for line in train_file_list)
with open('Glomeruli-dataset/splits/val.txt', 'w') as f:
f.writelines(line.split('.')[0] + '\n' for line in test_file_list)
执行之后,在Glomeruli-dataset多了一个splits文件夹,该文件夹下有一个train.txt和val.txt文件。
三、编写配置文件
1.下载权重
# 进入mmsgementation目录
cd mmsegmentation
mkdir checkpoints && cd checkpoints
wget https://download.openmmlab.com/mmsegmentation/v0.5/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth
2.配置文件
# configs目录下新建mouse_glomeruli文件夹
cd configs
mkdir mouse_glomeruli && cd mouse_glomeruli
vim pspnet_r50-d8_4xb2-40k_cityscapes-512x1024_mouse.py
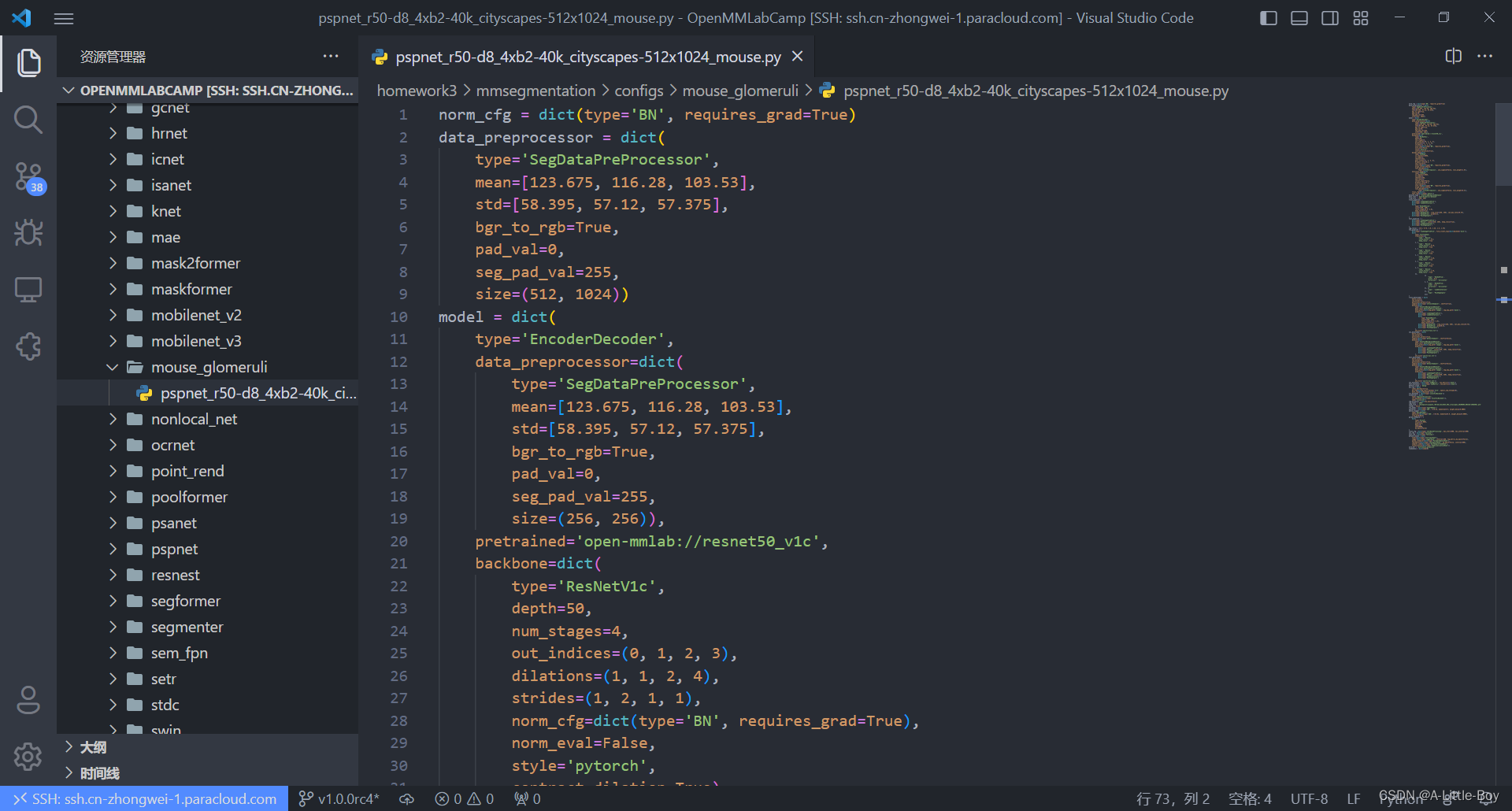
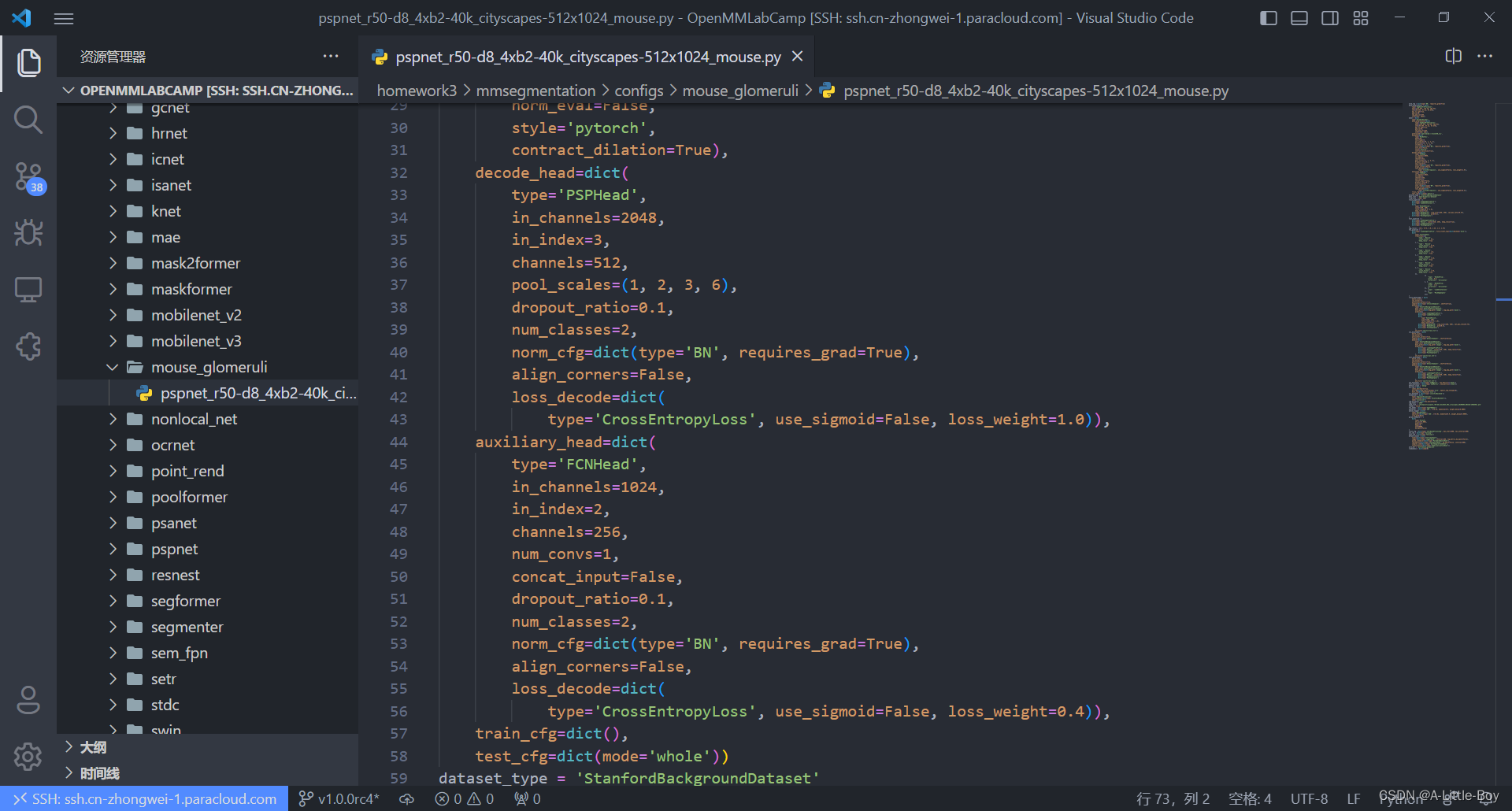
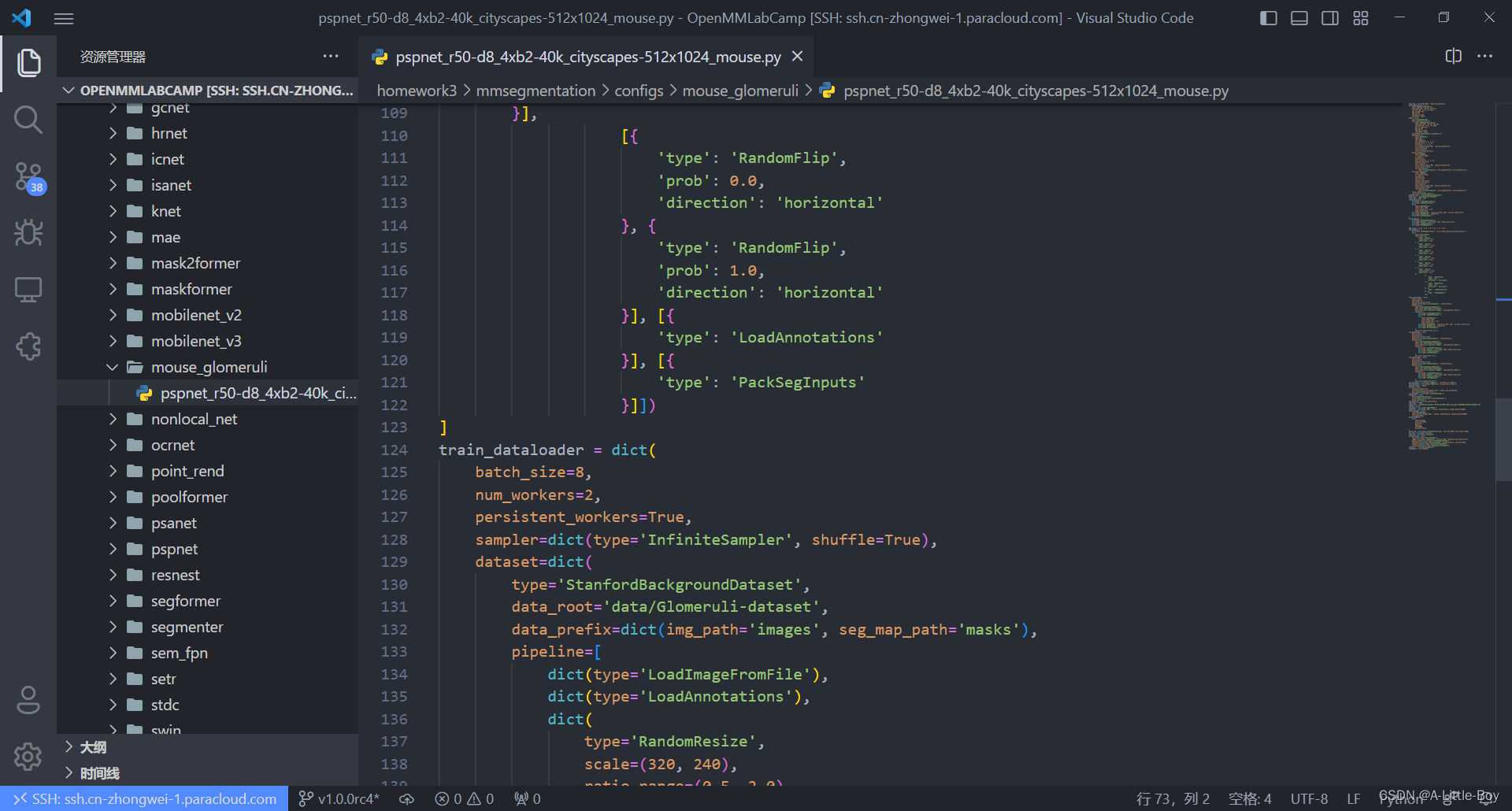
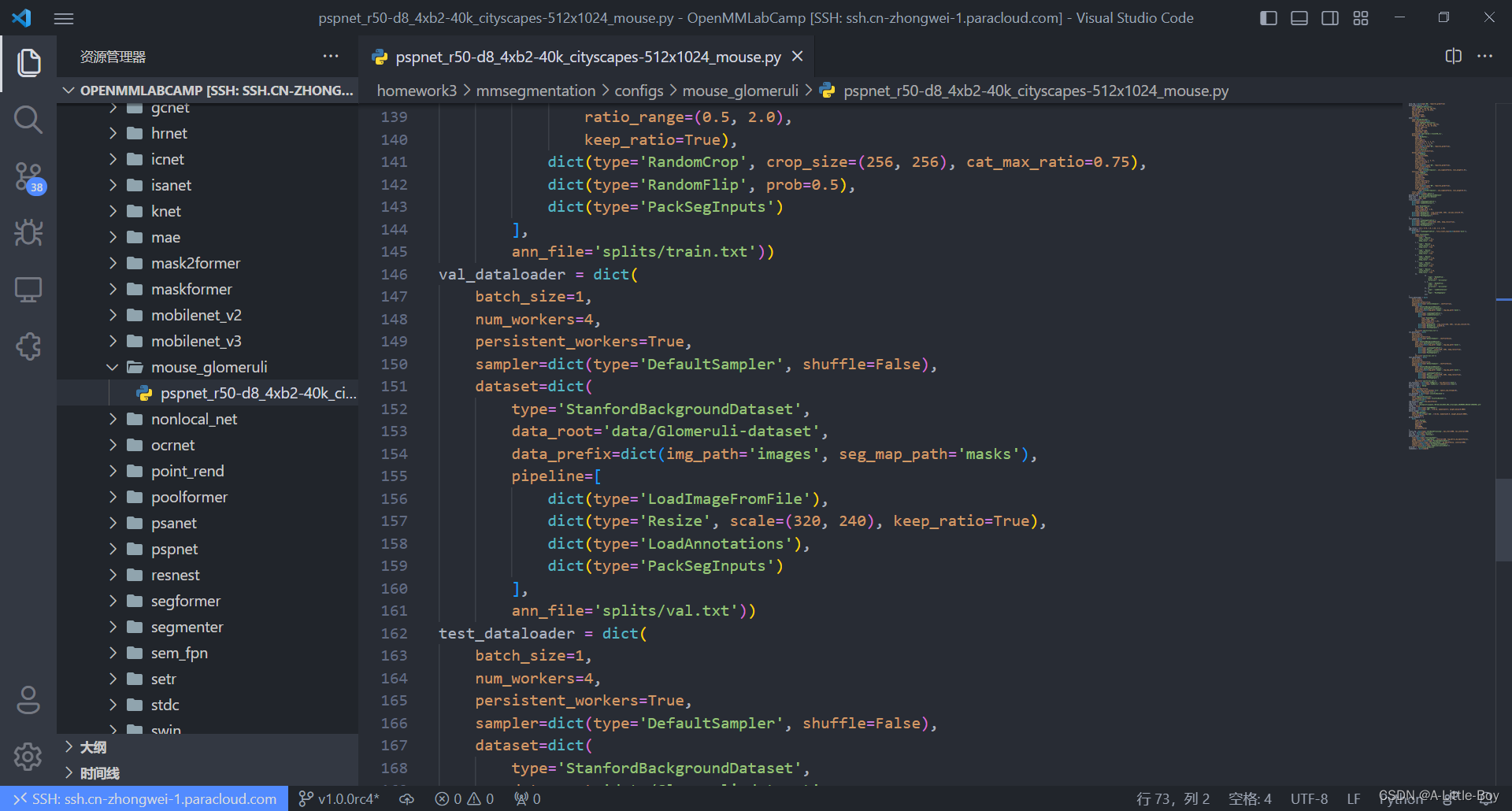

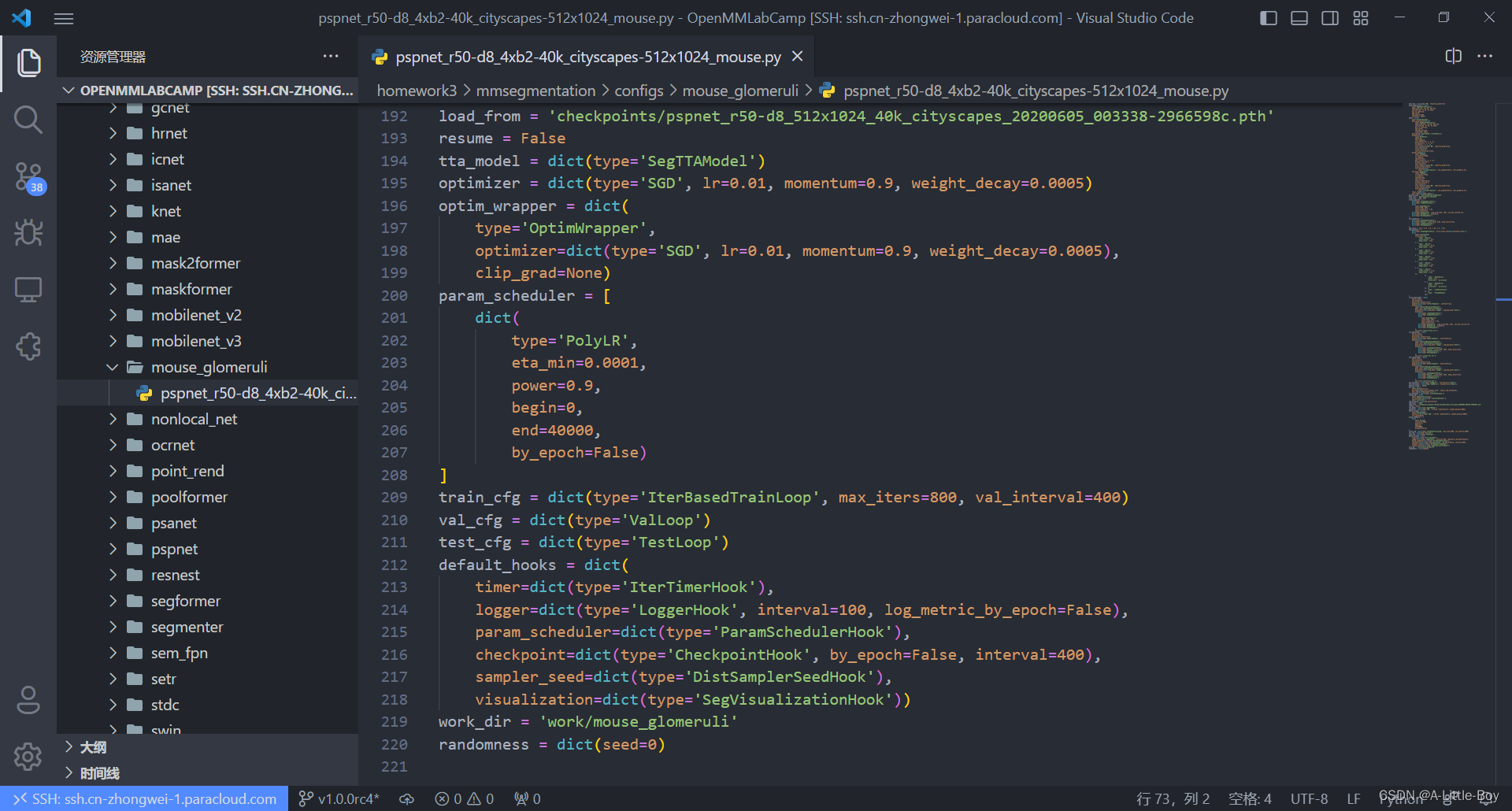
四、训练模型
训练脚本 train_data.py
import numpy as np
from PIL import Image
import os.path as osp
from tqdm import tqdm
import mmcv
import mmengine
import matplotlib.pyplot as plt
# 数据集图片和标注路径
data_root = '../data/Glomeruli-dataset'
img_dir = 'images'
ann_dir = 'masks'
# 类别和对应的颜色
classes = ('background', 'glomeruili')
palette = [[128, 128, 128], [151, 189, 8]]
from mmseg.registry import DATASETS
from mmseg.datasets import BaseSegDataset
@DATASETS.register_module()
class StanfordBackgroundDataset(BaseSegDataset):
METAINFO = dict(classes = classes, palette = palette)
def __init__(self, **kwargs):
super().__init__(img_suffix='.png', seg_map_suffix='.png', **kwargs)
from mmengine import Config
cfg = Config.fromfile('../configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py')
cfg.norm_cfg = dict(type='BN', requires_grad=True) # 只使用GPU时,BN取代SyncBN
cfg.crop_size = (256, 256)
cfg.model.data_preprocessor.size = cfg.crop_size
cfg.model.backbone.norm_cfg = cfg.norm_cfg
cfg.model.decode_head.norm_cfg = cfg.norm_cfg
cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg
# modify num classes of the model in decode/auxiliary head
cfg.model.decode_head.num_classes = 2
cfg.model.auxiliary_head.num_classes = 2
# 修改数据集的 type 和 root
cfg.dataset_type = 'StanfordBackgroundDataset'
cfg.data_root = data_root
cfg.train_dataloader.batch_size = 8
cfg.train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='RandomResize', scale=(320, 240), ratio_range=(0.5, 2.0), keep_ratio=True),
dict(type='RandomCrop', crop_size=cfg.crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PackSegInputs')
]
cfg.test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', scale=(320, 240), keep_ratio=True),
# add loading annotation after ``Resize`` because ground truth
# does not need to do resize data transform
dict(type='LoadAnnotations'),
dict(type='PackSegInputs')
]
cfg.train_dataloader.dataset.type = cfg.dataset_type
cfg.train_dataloader.dataset.data_root = cfg.data_root
cfg.train_dataloader.dataset.data_prefix = dict(img_path=img_dir, seg_map_path=ann_dir)
cfg.train_dataloader.dataset.pipeline = cfg.train_pipeline
cfg.train_dataloader.dataset.ann_file = 'splits/train.txt'
cfg.val_dataloader.dataset.type = cfg.dataset_type
cfg.val_dataloader.dataset.data_root = cfg.data_root
cfg.val_dataloader.dataset.data_prefix = dict(img_path=img_dir, seg_map_path=ann_dir)
cfg.val_dataloader.dataset.pipeline = cfg.test_pipeline
cfg.val_dataloader.dataset.ann_file = 'splits/val.txt'
cfg.test_dataloader = cfg.val_dataloader
# 载入预训练模型权重
cfg.load_from = '../checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
# 工作目录
cfg.work_dir = '../work/mouse_glomeruli'
# 训练迭代次数
cfg.train_cfg.max_iters = 800
# 评估模型间隔
cfg.train_cfg.val_interval = 400
# 日志记录间隔
cfg.default_hooks.logger.interval = 100
# 模型权重保存间隔
cfg.default_hooks.checkpoint.interval = 400
# 随机数种子
cfg['randomness'] = dict(seed=0)
cfg.dump("../configs/mouse_glomeruli/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024_mouse.py")
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
runner.train()
GPU任务脚本 run_mouse_glomeruli.sh
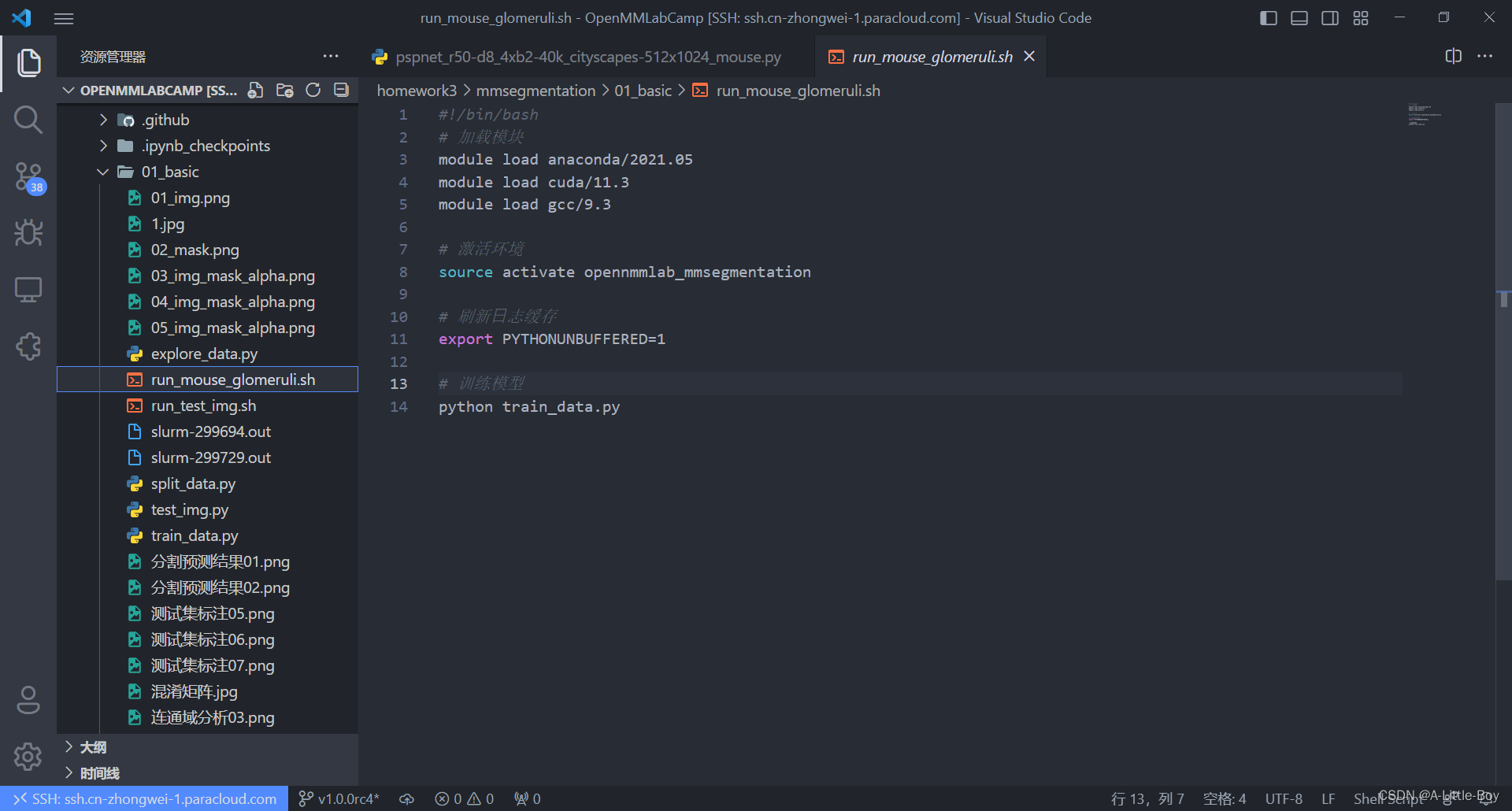
#提交云计算中心执行
sbatch --gpus=1 run_mouse_glomeruli.sh
五、测试模型
单张图片测试脚本 test_img.py
import numpy as np
import matplotlib.pyplot as plt
from mmseg.apis import init_model, inference_model, show_result_pyplot
import mmcv
import cv2
from sklearn.metrics import confusion_matrix
import itertools
# 载入 config 配置文件
from mmengine import Config
cfg = Config.fromfile("../configs/mouse_glomeruli/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024_mouse.py")
from mmengine.runner import Runner
from mmseg.utils import register_all_modules
# register all modules in mmseg into the registries
# do not init the default scope here because it will be init in the runner
register_all_modules(init_default_scope=False)
runner = Runner.from_cfg(cfg)
# 初始化模型
checkpoint_path = '../work/mouse_glomeruli/iter_800.pth'
model = init_model(cfg, checkpoint_path, 'cuda:0')
img = mmcv.imread('../data/Glomeruli-dataset/images/VUHSK_1702_39.png')
result = inference_model(model, img)
print(result.keys())
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
print(pred_mask.shape)
print(np.unique(pred_mask))
plt.imshow(pred_mask)
plt.savefig("分割预测结果01.png")
# plt.show()
# 可视化预测结果
print("可视化预测结果")
visualization = show_result_pyplot(model, img, result, opacity=0.7, show=False, out_file="1.jpg")
plt.imshow(mmcv.bgr2rgb(visualization))
plt.savefig("分割预测结果02.png")
# plt.show()
print("可视化预测结果")
print("连通域分析")
plt.imshow(np.uint8(pred_mask))
plt.savefig("连通域分析03.png")
# plt.show()
print("连通域分析")
connected = cv2.connectedComponentsWithStats(np.uint8(pred_mask), connectivity=4)
print("连通域个数:", connected[0])
print("用整数表示每个连通域区域:", connected[1].shape)
print(np.unique(connected[1]))
plt.imshow(connected[1])
plt.savefig("连通域分析04.png")
# plt.show()
# 每个连通域外接矩形的左上角X、左上角Y、宽度、高度、面积
print(connected[2])
# 每个连通域的质心坐标
print(connected[3])
label = mmcv.imread('../data/Glomeruli-dataset/masks/VUHSK_1702_39.png')
label_mask = label[:,:,0]
print(label_mask.shape)
print(np.unique(label_mask))
plt.imshow(label_mask)
plt.savefig("测试集标注05.png")
# plt.show()
# 测试集标注
print(label_mask.shape)
# 语义分割预测结果
print(pred_mask.shape)
# 真实为前景,预测为前景
TP = (label_mask == 1) & (pred_mask==1)
# 真实为背景,预测为背景
TN = (label_mask == 0) & (pred_mask==0)
# 真实为前景,预测为背景
FN = (label_mask == 1) & (pred_mask==0)
# 真实为背景,预测为前景
FP = (label_mask == 0) & (pred_mask==1)
plt.imshow(TP)
plt.savefig("测试集标注06.png")
# plt.show()
confusion_map = TP * 255 + FP * 150 + FN * 80 + TN * 10
plt.imshow(confusion_map)
plt.savefig("测试集标注07.png")
# plt.show()
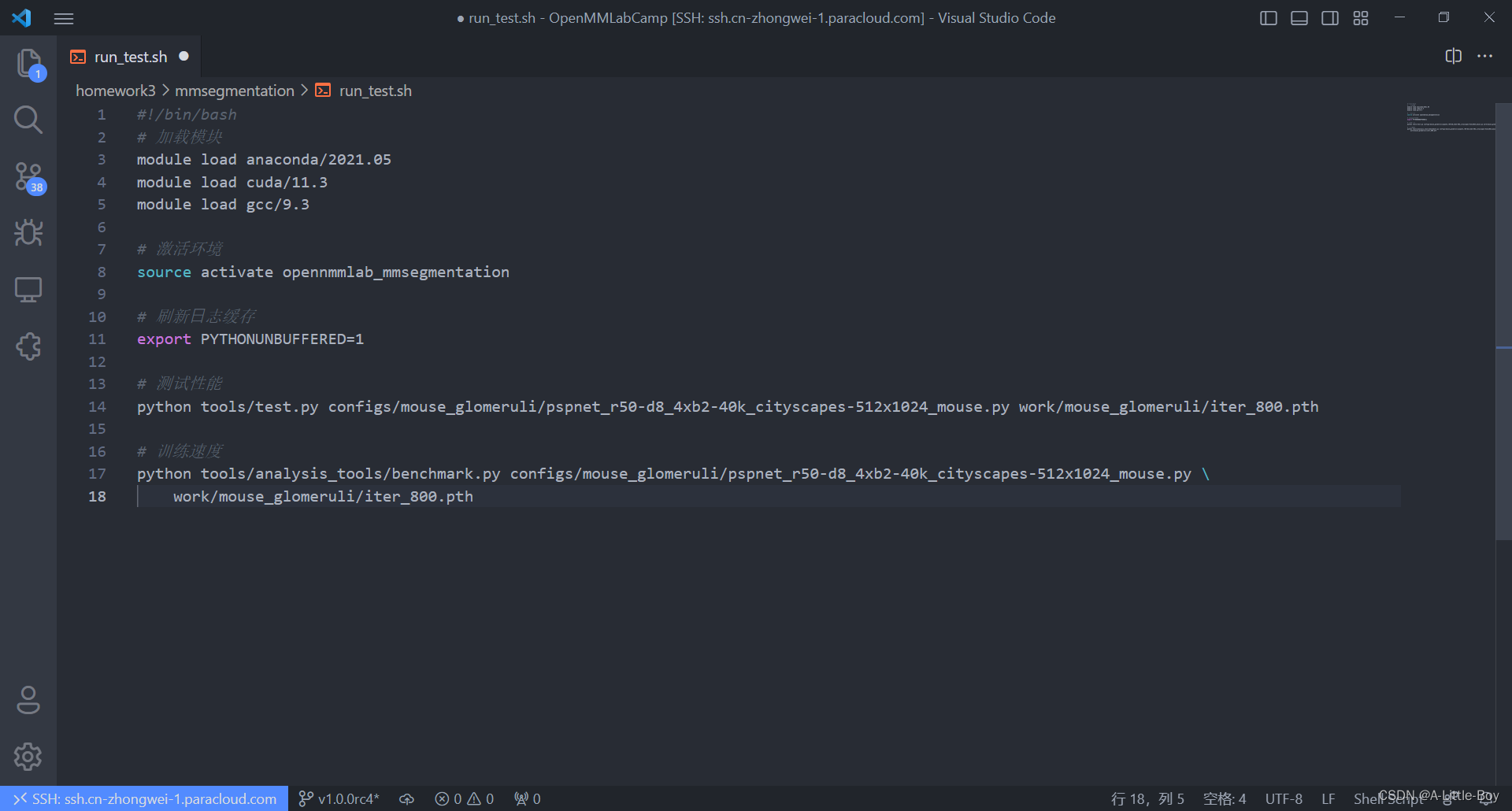
confusion_matrix_model = confusion_matrix(label_mask.flatten(), pred_mask.flatten())
def cnf_matrix_plotter(cm, classes, cmap=plt.cm.Blues):
"""
传入混淆矩阵和标签名称列表,绘制混淆矩阵
"""
plt.figure(figsize=(10, 10))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
# plt.colorbar() # 色条
tick_marks = np.arange(len(classes))
plt.title('Confusion Matrix', fontsize=30)
plt.xlabel('Pred', fontsize=25, c='r')
plt.ylabel('True', fontsize=25, c='r')
plt.tick_params(labelsize=16) # 设置类别文字大小
plt.xticks(tick_marks, classes, rotation=90) # 横轴文字旋转
plt.yticks(tick_marks, classes)
# 写数字
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
fontsize=12)
plt.tight_layout()
plt.savefig('混淆矩阵.jpg', dpi=300) # 保存图像
plt.show()
cnf_matrix_plotter(confusion_matrix_model, classes=["background", "glomeruili"], cmap='Blues')
GPU单张图片测试脚本 run_test_img.sh
六、性能测试
以上就是本季OpenMMLab 实战营的全部打卡笔记,感谢每个努力坚持的人,一起学习,一起进步呀,如果觉得还不错的话,欢迎关注点赞评论~














 1860
1860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









