






AI编译器TVM与MLIR框架分析 - 吴建明wujianming - 博客园 (cnblogs.com)
图5 常见ai compiler设计架构
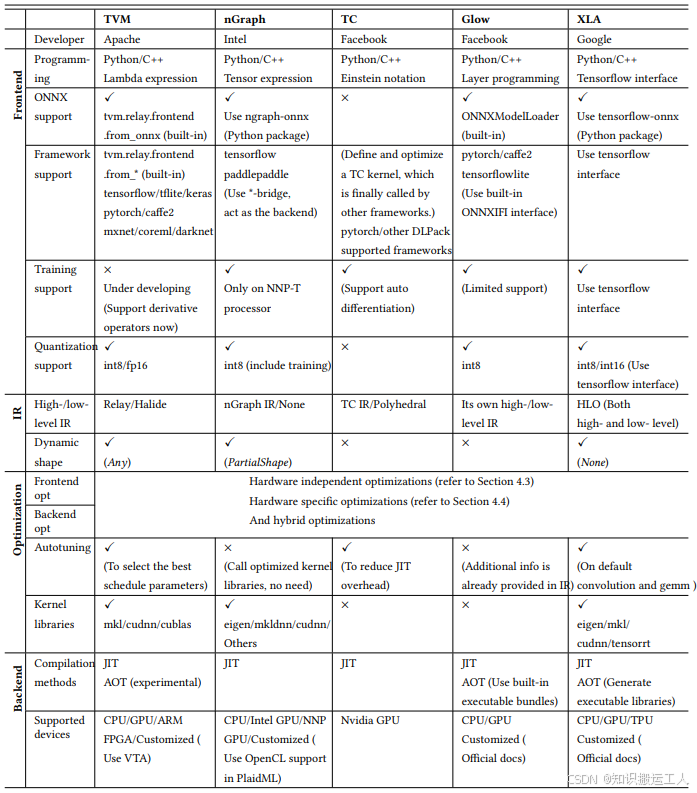
relay到tir算子expand的过程太陡峭,算子的负担可以稍微迁移一部分给图层,图层会有机会做更全局的优化。这些,对于交付来说,其实不痛不痒,mlir并没有带来巨大的收益。同时目前mlir还缺自定义算子的能力,类似tvm的dsl还没有构建出来,以及算子tiling或者tuning的工具也还没有。这些估计都需要时间去构建,估计2-3年?
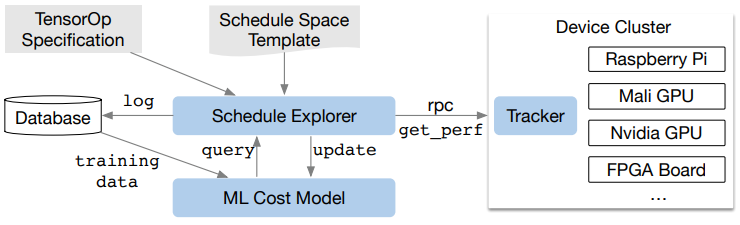
图11 AutoTVM自动优化架构
总体来说,tvm当前更能满足产品交付的需求。mlir想做到相同的能力(算子能力的差距,图层能力其实差不多),还需要更长时间。当然二者都在不停演进,相互吸收优点。

















 1325
1325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









