









前言
继谷歌推出了Tryon Diffusion,阿里推出了Outfit Anything后, 亚马逊终在上周也推出了Diffuse to Choose。至此几大头部电商也都在虚拟试衣技术上完成了布局。基于扩散模型的技术基本已经成为现在主流应用的基石。
在之前的文章中已经详细的介绍了谷歌的Tryon Diffusion和阿里的Outfit Anything, 感兴趣的小伙伴可以点点击下面链接阅读~
电商模特危机!谷歌最新模型Tryon Diffusion一键试衣,线上购物被革命_tryondiffusion-CSDN博客文章浏览阅读905次,点赞17次,收藏18次。谷歌的新AI模型TryOnDiffusion,直接解决了AI换装的两大难题——既保留衣服细节,又能随意换姿势。以后再剁手,恐怕要更容易了!你只要给它一张自己的全身照,和服装模特的照片,就能知道自己穿上这件衣服之后是什么样子了。一键换装,被谷歌给实现了!Try_tryondiffusion https://blog.csdn.net/xs1997/article/details/135784937?spm=1001.2014.3001.5501AI一键换衣,阿里Outfit Anyone来了,电商人的福音!_outfit anyone和anydoor-CSDN博客文章浏览阅读969次,点赞17次,收藏18次。继谷歌推出Tryon Diffusion虚拟试穿后,国内的头部电商阿里也推出的Outfit Anyone虚拟试穿技术。该技术采用双流条件扩散模型,处理模特和服装数据,通过衣物图像实现逼真的虚拟试穿效果,结合Animate Anyone技术,轻松制作任意角色的换装视频。只需要一张人物照片和服装照片,就可以为不同的姿势和身体形状创建高质量的虚拟试穿。国内的电商革命也终于要到来了!_outfit anyone和anydoorhttps://blog.csdn.net/xs1997/article/details/135816476?spm=1001.2014.3001.5501 亚马逊推出的Diffuse to Choose工具也是基于扩散模型改进,可以为网购客户提供身临其境的虚拟试穿服务。与扩散模型相比,Diffuseto Choose模型能更好地捕捉商品细节,保证与环境的高度融合。用户可以上传一张全身自拍照,测试不同服装的试穿效果,或者上传多张人物照片,测试同件服装的穿着效果。消费者还可以拍摄家中的场景,选择不同的家具来测试商品和家装氛围的契合度。
https://blog.csdn.net/xs1997/article/details/135784937?spm=1001.2014.3001.5501AI一键换衣,阿里Outfit Anyone来了,电商人的福音!_outfit anyone和anydoor-CSDN博客文章浏览阅读969次,点赞17次,收藏18次。继谷歌推出Tryon Diffusion虚拟试穿后,国内的头部电商阿里也推出的Outfit Anyone虚拟试穿技术。该技术采用双流条件扩散模型,处理模特和服装数据,通过衣物图像实现逼真的虚拟试穿效果,结合Animate Anyone技术,轻松制作任意角色的换装视频。只需要一张人物照片和服装照片,就可以为不同的姿势和身体形状创建高质量的虚拟试穿。国内的电商革命也终于要到来了!_outfit anyone和anydoorhttps://blog.csdn.net/xs1997/article/details/135816476?spm=1001.2014.3001.5501 亚马逊推出的Diffuse to Choose工具也是基于扩散模型改进,可以为网购客户提供身临其境的虚拟试穿服务。与扩散模型相比,Diffuseto Choose模型能更好地捕捉商品细节,保证与环境的高度融合。用户可以上传一张全身自拍照,测试不同服装的试穿效果,或者上传多张人物照片,测试同件服装的穿着效果。消费者还可以拍摄家中的场景,选择不同的家具来测试商品和家装氛围的契合度。

相关链接
论文链接:https://arxiv.org/pdf/2401.13795.pdf
项目地址:https://diffuse2choose.github.io/
论文解读
Diffuse to Choose: Enriching Image Conditioned Inpainting in Latent Diffusion Models for Virtual Try-All
Mehmet Saygin Seyfioglu♠, Karim Bouyarmane♣
Suren Kumar, Amir Tavanaei, Ismail B. Tutar
Amazon
♠ University of Washington, work done during internship at Amazon
♣ Corresponding author at Amazon![]()

一、摘要
随着在线购物的增长,买家在他们的设置中虚拟可视化产品的能力--定义为"虚拟试衣"的现象--已经变得至关重要。最近的扩散模型本身包含一个世界模型,使它们适合在修复上下文中完成这项任务。然而,传统的图像条件扩散模型往往无法捕捉品的细粒度细节。相比之下,个性化驱动的模型(如DreamPaint)擅长保存项目的细节,但它们没有有针对实时应用进行优化。
Diffuse to Choose是一种新的基于扩散的图像条件修复模型,该模型能够有效地平衡快速推断与给定参考项中高保真细节的保留,同时确保在给定场景景内容中进行准确的语义操作。该方法是基于将参考图像的细粒度特征直接纳入主扩散模型的灌替在特征图,同时通过感知损失进一步保留参考项的细节。在内部和公开数据集上进行了广泛的的测试,表明了Diffuse to Choose优于现有的零样本扩散修复方法以及DreamPaint等少量样本扩散个性化算法。
二、模型结构
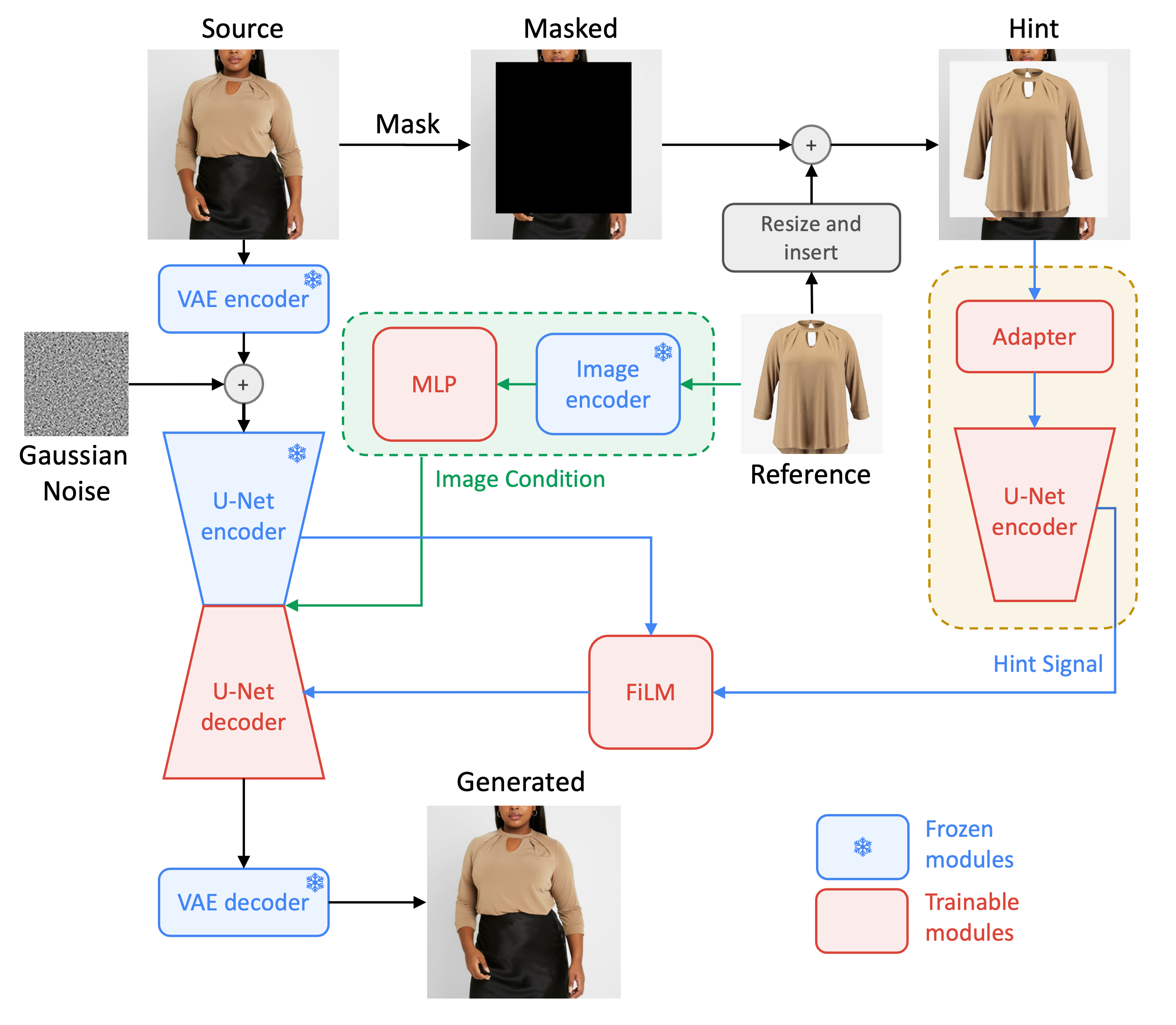
DTC利用一个辅助U-Net编码器将细粒度的细节注入扩散过程。这开始于掩蔽源图像,然后在掩蔽区域内插入参考图像。产生的像素级"提示"随后由一个浅层CNN进行调整,与源图像的VAE输出维度对齐,然后逐个添加到它。接下来,一个U-Net编码器处理调整整后的提示,其中在U-Net的每个尺度上,一个FILM模块将来自主U-Net编码器的跳跃连接特征与来自提示U-Net编码器的像素级特征进行仿射对齐。最后,这些对齐的特征图与主图像调节相结合,有助于掩蔽区域的修复。
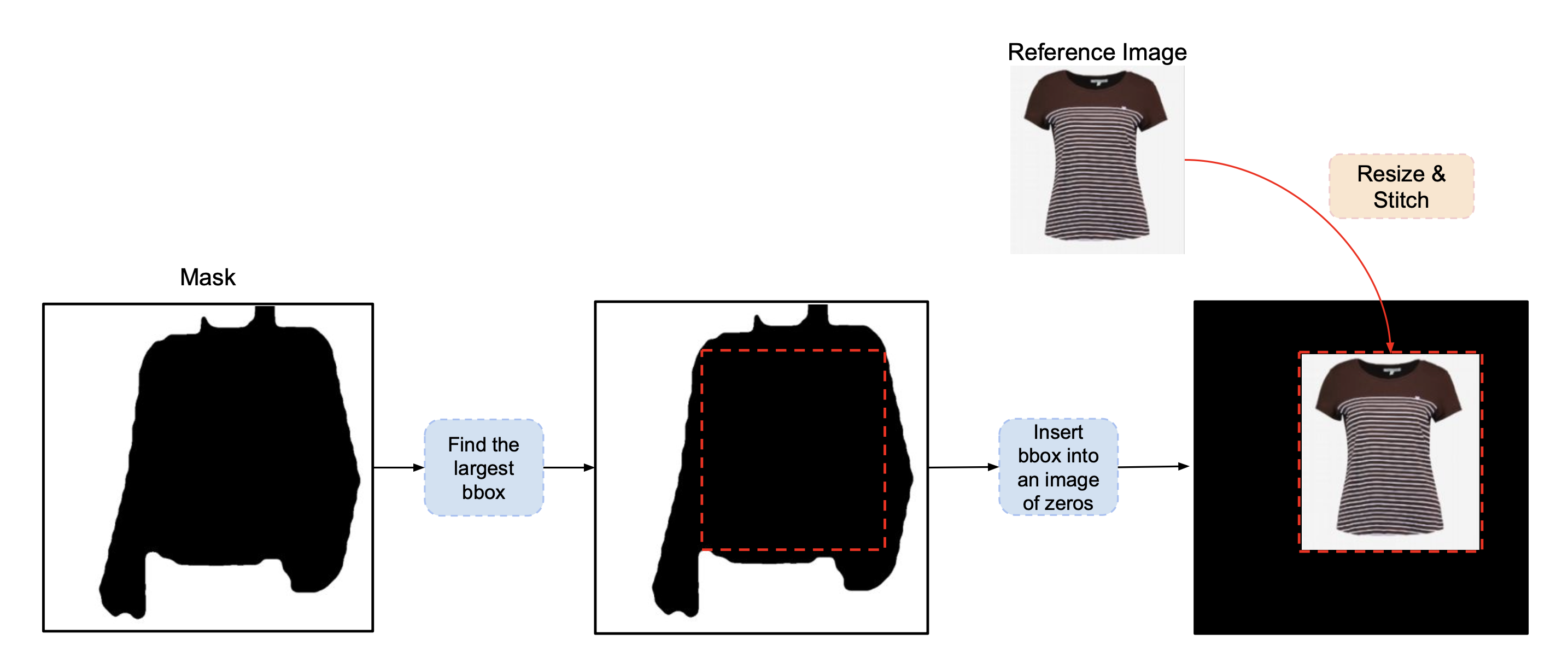
三、掩码策略
为了在推理过程中处理任意遮罩形状和野外示例,DTC实现了一种掩码增强技术。通过这种方法,我们在训练过程中使用边界框掩码(来自细粒度掩码)或细粗度掩码本身的概率是相等的。当选择细粒度掩模时,将参考图像整合到掩模的最大矩形区域内。
四、定性结果
DTC可以在随意参考图像和源图像中工作,具有任意或刚性遮罩形状。
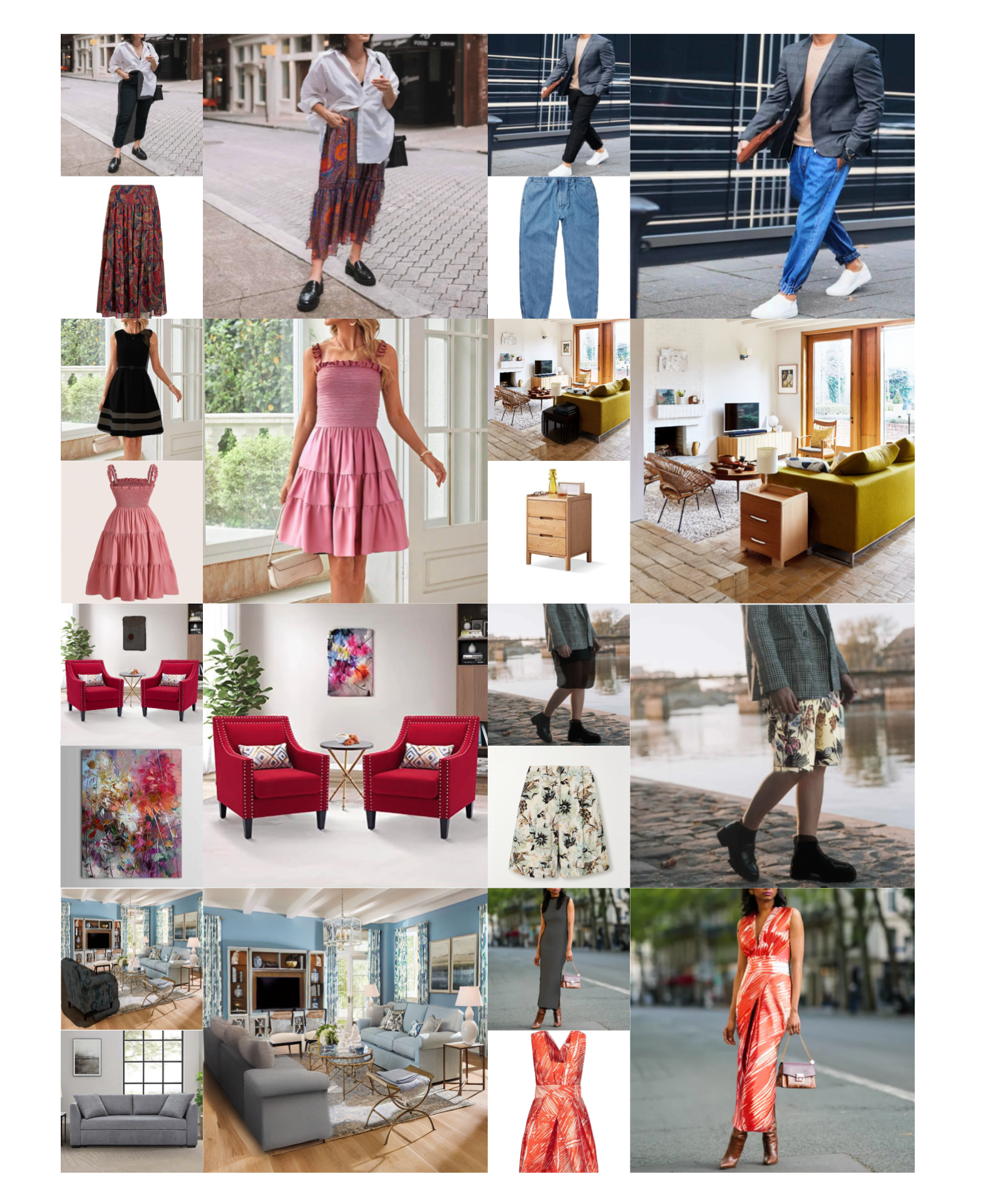
五、有趣的应用
可以使用DTC来反复装饰你的房间。 
或者不受任何限制地尝试不同的衣服组合 
调整口罩可以改变服装风格,比如把衣服掖好或卷起袖子。


总结分析
DTC在实验中展示了其在虚拟试穿应用中的有效性,特别是在保留产品细节和实现快速推理方面。尽管存在一些局限性,如DTC在处理某些物品(如鞋子)时可能无法生成满意的结果,这可能是由于SAM(Semantically Aware Masking)无法为成对出现的物品(如鞋子)生成适当的遮罩。模型可能会改变人体姿势,因为它不考虑姿势信息,这可能导致与遮罩无关的全身覆盖场景中的不一致性。但DTC在与现有方法的比较中表现出色,尤其是在零样本设置下。
感谢你看到这里,也欢迎关注下方公众号,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion等相关技术,欢迎一起交流学习~



















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











