






 研究人员提出DiffMorpher,首个使用扩散模型进行平滑图像插值的方法,通过LoRA拟合和插值技术改善了图像变形效果。尽管与GAN相比存在可编辑性挑战,但该工作为扩散模型在图像变换任务中的应用开辟新路径。
研究人员提出DiffMorpher,首个使用扩散模型进行平滑图像插值的方法,通过LoRA拟合和插值技术改善了图像变形效果。尽管与GAN相比存在可编辑性挑战,但该工作为扩散模型在图像变换任务中的应用开辟新路径。
相信大家在网上看过一些图像变换的动图以及视频。比如生成两张人脸之间的渐变图。

狮子变老虎

那么这种功能是如何实现的呢?
计算机科学中有一种专门描述此应用的任务—图像变形(image morphing)。给定两张图像,图像变形算法会输出一系列合理的插值图像。当按顺序显示这些插值图像时,它们应该能构成一个描述两张输入图像平滑变换的视频。

今天给大家介绍的是DragGAN作者的新作DiffMorpher:可以实现两张图像间的平滑变形。该研究由 DragGAN 作者潘新钢教授指导,经清华大学、上海人工智能实验室、南洋理工大学 S-Lab 合作完成。目前,该工作已经被 CVPR 2024 接收。
相关链接
论文链接:https://arxiv.org/pdf/2312.07409.pdf
项目地址:https://github.com/Kevin-thu/DiffMorpher
Web demo: https://openxlab.org.cn/apps/detail/KaiwenZhang/DiffMorpher
论文阅读

DiffMorpher:释放图像变形扩散模型的能力
摘要
扩散模型取得了超越以前的生成模型的卓越图像生成质量。然而与GAN相比,扩散模型的一个显着局限性是由于其高度非结构化的潜在空间,它们难以在两个图像样本之间平滑插值。这种平滑的插值很有趣,因为它自然可以作为许多应用程序的图像变形任务的解决方案。
在这项工作中,我们提出了DiffMorpher,这是第一种使用扩散模型实现平滑、自然图像插值的方法。关键思想是通过分别拟合两个LoRA来捕获两个图像的语义,并在LoRA参数和潜在噪声之间进行插值,以确保平滑的语义转换,其中对应关系会自动出现,无需注释。
此外,我们提出了一种注意力插值和注入技术、一种自适应归一化调整方法和一种新的采样方案,以进一步增强连续图像之间的平滑度。大量实验表明,DiffMorpher在各种对象类别上实现了比以前的方法明显更好的图像变形效果,弥补了区分扩散模型和GAN的关键功能差距。
方法概述
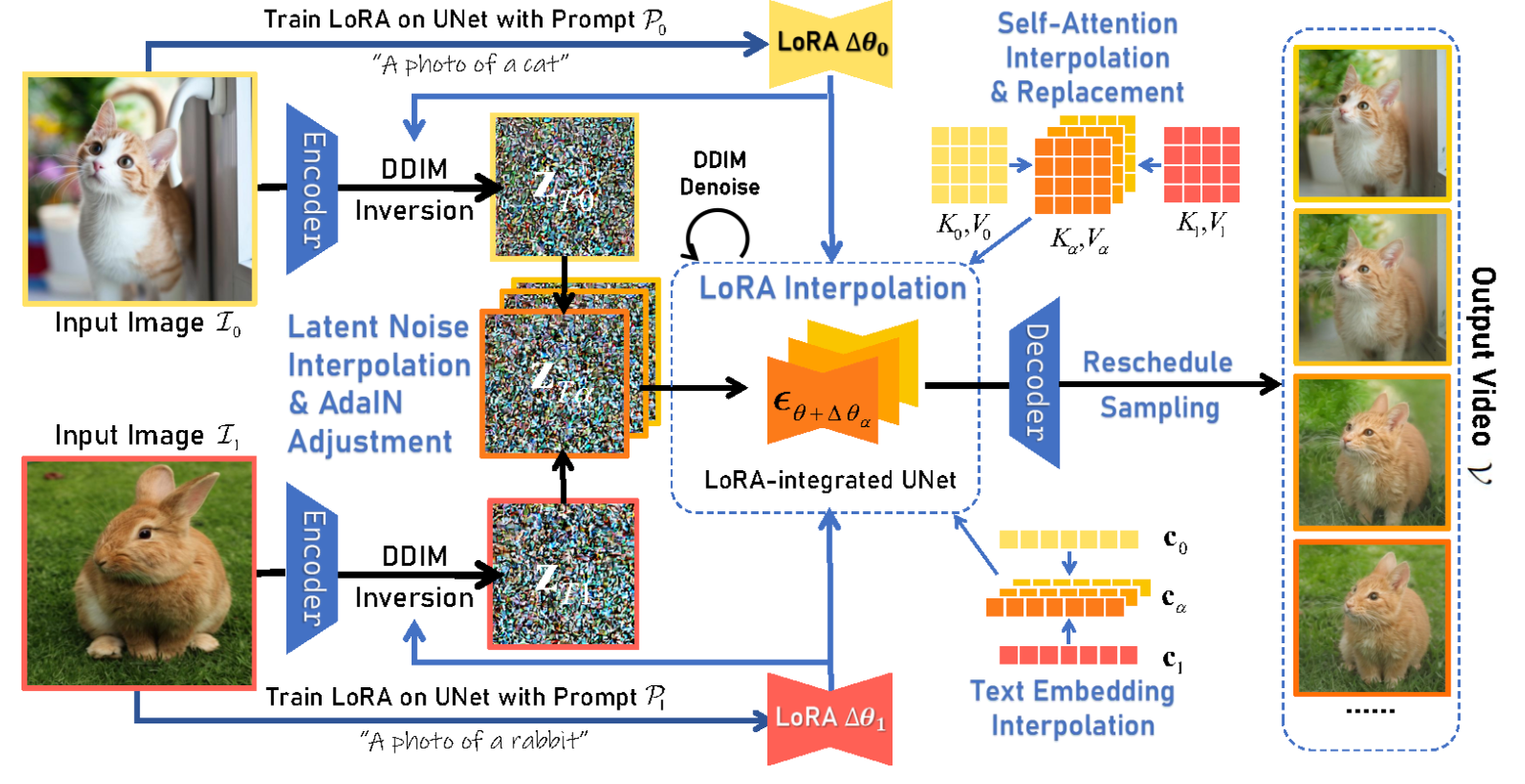
给定两个图像I_0和I_1,训练两个LoRA来分别拟合这两个图像。然后通过DDIM反演获得两幅图像的潜在噪声。
插值噪声的平均值和标准差通过AdaIN进行调整。为了生成中间图像,通过插值比α在LoRA参数和潜在噪声之间进行插值。此外,文本嵌入以及自注意力模块中的K和V也被替换为相应组件之间的插值。使用α序列和新的采样计划,我们的方法将生成一系列高保真图像,描绘I_0和I_1之间的平滑过渡。
结果
动物

艺术作品

人脸

建筑物

其他物品

动画

总结
尽管DiffMorpher已经算是一个不错的图像变形工具了,该方法并没有从本质上提升扩散模型的可编辑性。相比GAN而言,逐渐对扩散模型的隐变量修改难以产生平滑的输出结果。
比如在拖拽式编辑任务中,DragGAN只需要优化GAN 的隐变量就能产生合理的编辑效果,而扩散模型中的类似工具(如 DragDiffusion, DragonDiffusion)需要更多设计才能达到同样的结果。从本质上提升扩散模型的可编辑性依然是一个值得研究的问题。



















 7476
7476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











