









本文内容来自公众号粉丝投稿,作者来自复旦大学的视觉与学习实验室(FVL)。研究团队提出了一种可靠、高效的概念移除方法(RECE)。该方法以解析解的形式,迭代地进行风险概念移除、风险概念嵌入推导,从而确保模型彻底移除风险概念。本篇工作的论文和代码均已开源。
相关链接
论文链接:https://arxiv.org/abs/2407.12383
论文阅读

问题背景
近年来,基于扩散模型的文生图(T2I)技术取得了重大进展,已经可以生成十分逼真的图像。然而,在生成高质量图像内容的同时,上述模型也存在被滥用的风险,例如生成侵犯版权和包含风险内容(如虚假新闻、暴力色情内容)的图像。尤其是Stable Diffusion(SD)的开源,使得文生图技术变得更加普及。
目前,已有的安全措施包括使用安全检查器对输出进行检查,以及应用无分类器引导来规避风险概念等。然而,由于代码和模型参数的开源,这些方法都容易被攻击者轻易绕过。
针对上述问题,一种有效的解决方案是从T2I扩散模型中移除风险概念,即通过微调模型参数,使其不再具备生成特定不当内容的能力。这种方法不需要从头训练模型,也不易被绕过。尽管概念移除取得了一定进展,但仍存在问题。首先,现有的大多数概念移除方法在微调时需要大量的迭代,导致模型生成能力下降并消耗大量计算资源。其次,已有方法都不能充分移除不当概念,即模型仍有很大几率生成风险图像。
方法简介
为了解决上述问题,研究团队提出了一种可靠、高效的概念移除方法(RECE)。该方法以解析解的形式,迭代地进行风险概念移除、风险概念嵌入推导,从而确保模型彻底移除风险概念。RECE借鉴了对抗训练的思想,通过计算目标函数的解析解,高效地推导出新的风险概念嵌入,然后通过修改交叉注意力层,将它们与无害概念对齐。此外,为了保留模型的生成能力,RECE在嵌入推导过程中证明并引入了一个额外的正则项,从而最小化对生成能力的损害。
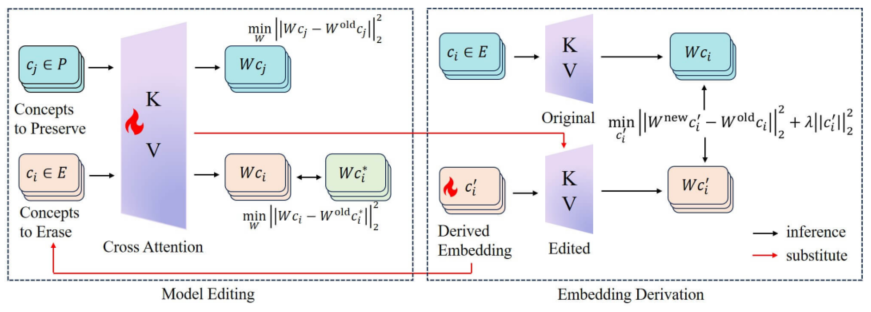
可靠高效的概念移除
前置知识
SD等T2I模型通过CLIP对文本进行编码,并通过交叉注意力层将文本嵌入集成到U-Net中。在交叉注意力中,SD用文本嵌入生成key和value,用视觉特征生成query,然后计算交叉注意力输出:

现有的一些概念移除方法需要进行大量微调,效率较低。与之相比,UCE是一种高效的概念移除方法,通过解析解来编辑交叉注意力的权重。
UCE需要一个“源”概念(例如,“裸露”)和一个“目标”概念(例如,空文本“ ”)。给定一个交叉注意力的K/V投影矩阵,UCE的目标是找到新权重,使得新权重下的源概念的映射值对齐到目标概念。同时,为了控制参数变化,UCE最小化对无关概念映射值的影响,并引入L2正则化项:
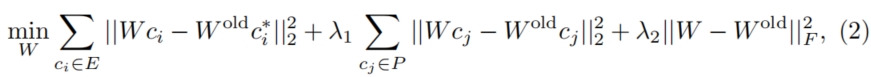
这是一个凸函数,可以直接求出解析解,并赋值给新权重,速度极快:
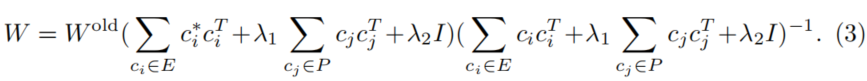
可靠高效的概念移除
风险概念嵌入推导
尽管UCE的效率很高,但它概念删除很不彻底,仍有很大几率生成风险图片。为了充分移除风险概念,研究团队首先推导得到风险概念的新嵌入表示,这些新嵌入表示可以使UCE编辑后的模型重新生成风险图片:

以“裸露”为例,我们的目标是得到一个新的概念嵌入,其在新交叉注意力下能引导生成裸露图片。换句话说,经过映射后,应当接近经过的映射值:
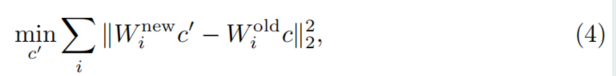
上式为凸函数,因此具有解析解:

上述推导得到的可以引导编辑后的模型重新生成裸露图片。
正则项
我们发现直接编辑交叉注意力来将公式(5)中的擦除,会对模型能力产生极大的破坏。因此研究团队引入额外的约束来保证概念移除后模型的能力,即在两轮概念移除过程中,约束无关概念映射值的变化:
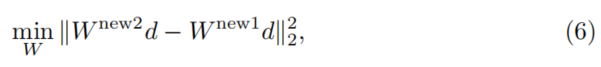
利用矩阵范数的相容性,可证明得到:
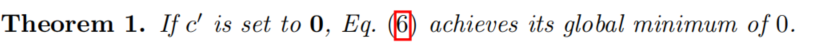
因此得到最终推导的目标函数为:
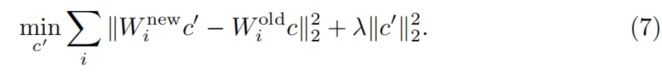
其解析解为:
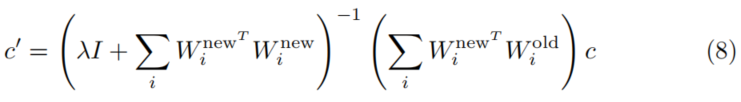
综上,RECE的算法流程归纳为:

实验
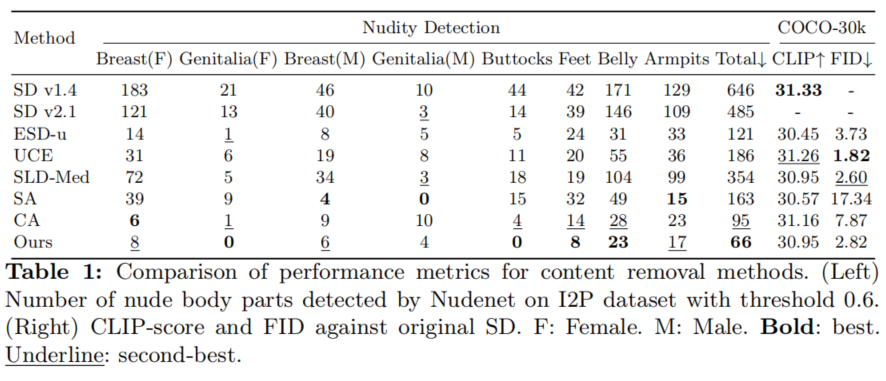
不安全概念移除
研究团队在I2P基准数据集上对比了不同概念移除方法对裸露的移除效果,所提出方法的移除效果超过了全部已有方法。编辑后的模型在无关概念集COCO-30k上的FID指标,也远超CA等方法。
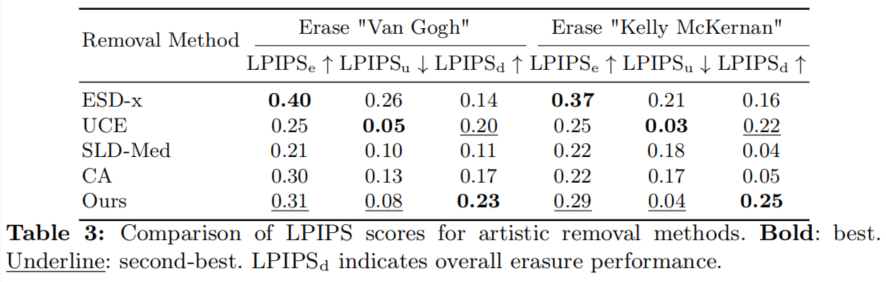
艺术风格移除
对于艺术风格移除,所提方法在目标艺术家擦除效果,无关艺术家保留效果以及综合效果方面都表现极佳。
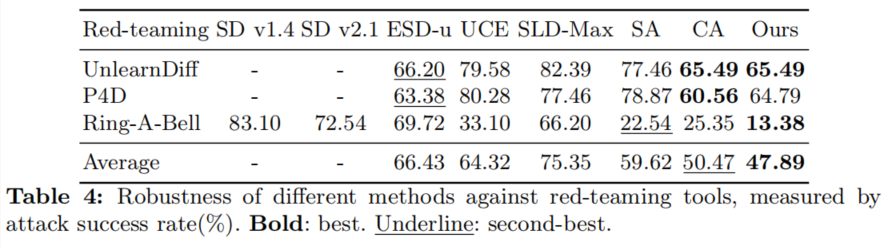
红队鲁棒性
此外,研究团队还验证了RECE对于恶意红队工具的鲁棒性。实验表明,即使在红队攻击下,RECE生成风险图片的几率仍是最低。
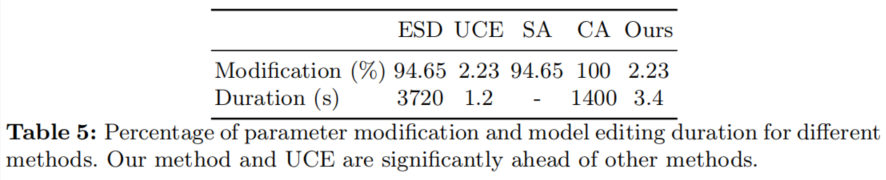
模型编辑耗时
研究团队还统计了参数改动比例、模型编辑所需时间。RECE的参数改动比例、编辑耗时远低于CA等方法。尽管UCE的耗时也很短,但RECE的概念移除效果远远好于UCE。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











