







 本文介绍了Non-negative Matrix Factorization (NMF)模型,通过将矩阵V分解为W和H两个非负矩阵,用于数据降维和聚类。特别地,文章探讨了如何使用NMF进行双聚类(biclustering)分析,以理解消费者购买行为。在案例研究中,利用R包`bayesm`中的Scotch数据集进行分析。
本文介绍了Non-negative Matrix Factorization (NMF)模型,通过将矩阵V分解为W和H两个非负矩阵,用于数据降维和聚类。特别地,文章探讨了如何使用NMF进行双聚类(biclustering)分析,以理解消费者购买行为。在案例研究中,利用R包`bayesm`中的Scotch数据集进行分析。
什么是NMF模型?
NMF = Non-negative Matrix Factorization.
V= WH
V, W , H 三个矩阵里的值都大于等于0.

NMF 的目的就是将矩阵V分解为较小的两个矩阵H和W。
我们把 V 称为Visible units , H 称作为 Hidden units, W 为 weights . V 通过 W 连接到H. H 被称为Hidden Factor, latent variables 或者basis.
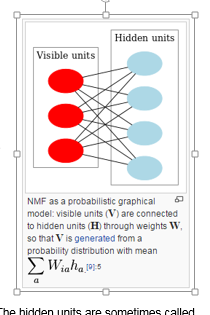
NMF 可以用来降维 或者 聚类。 在此文中,我们将把NMF模型应用到市场数据中,进行聚类分析。 这种聚类一般被称为 双聚类 biclustering .
我们的数据:
我们将使用 R package "bayesm" 中 的Scotch 数据
library(bayesm)
data(Scotch)
以下是Raw data:
Chivas.Regal Dewar.s.White.Label Johnnie.Walker.Black.Label J...B
1 1 0 0 0
2 0 0 1 0
3 0 0 0 0
4 1 0 1 0
5 1 0 1 0
6 0 0 0 0
7 0 0 0 0
8 0 1 0 1
|
|
|
#
|
Symbol
|
Brand
|
# Users
|
Price
|
Bottled
|
Type
|
|
1
|
CHR
|
Chivas Regal
|
806
|
21.99
|
Abroad
|
Blend
|
|
2
|
DWL
|
Dewar’s White Label
|
517
|
17.99
|
Abroad
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









