







0. 背景
论文地址:Fast R-CNN
代码地址:Github
Fast R-CNN 发表在 ICCV 2015 上,主要是针对 R-CNN 速度慢问题做了优化,参考了微软亚研院 Kaiming He 设计的 SPPnets,加速了 R-CNN 大约 200 倍(测试用时),同时检测效果也比之前优秀(很小)。另外我想说,好久没有看到这么简洁的标题了。
1. 贡献
整合了自己提出来的 R-CNN 与 SPPnets,使得架构更加简洁。提升了速度与存储空间占用率。为接下来的 Faster R-CNN 打下基础。
2. 现状
- R-CNN 在训练期间分步完成操作,提 proposal + ConvNet 获取特征 + SVM 分类 + bounding box regression,整个算法看起来像是几个项目的拼接,not graceful,
- R-CNN 在训练期间需要提取神经网络的最后一层 fc 层的输出作为 feature,训练 SVM 和 bounding box regression,这些个 feature 需要保存到硬盘当中,费时,占地。 作者使用 VOC07 数据集,VGG16 网络,用时约2.5 GPU 天,约几百 GiB 空间,
- 物体检测用时比较慢。VGG16 的话每幅图片用时 47s,还是在使用 GPU 的情况,因为每幅图片的 proposal 存在大量重合,而每个 proposal 都要使用神经网络提取 feature,相当于多了很多重复计算,
- SPPnets 做 fine-tune 时不能更新 conv 层。
3. 方案
去除了 SVM 分类器,使用 softmax 层进行分类。大概流程如下:
- 对图片中的潜在物体进行定位,使用 sparse 的 proposal,如 selective search 产生的结果,每幅图片产生约 2000 个 proposal,
- 训练和测试时,每张图片对神经网络的输入只有这个图片,还有对应的 proposal 位置,
- 神经网络的卷积层与全连接层中,加入 RoI pooling 层,此层会对每个 proposal 提取相同维度的激活值到接下来的全连接层,解决重复计算问题,
- 神经网络的最后一层是 softmax 和 bbox regression 并联,所以这个网络能够同时输出物体类别和微调 proposal 的位置,所以 R-CNN 中提 proposal + ConvNet 获取特征 + SVM 分类 + bounding box regression,整合为提 proposal + 卷积神经网络两步,使得网络更加的简洁。最后仍然有非最大值抑制:-)

图片来源1
RoI Pooling 层 - forward
正如前面说到的,RoI Pooling 层会给每个 proposal 输出相同维度的激活值。这层的输入是整幅图片经过几次卷积层的之后的激活函数,以及各个 RoI 的位置信息
(r,c,h,w)
,分别代表左上角的横纵坐标,以及 RoI 的高宽像素数。输出为 #RoI 个
H×W
的激活函数。
一般 pooling 层都是固定
pooling size
,而在 RoI Pooling 层,
pooling size=h/H×w/W
,文中使用的是 max pooling,也就是取这些小格子当中的最大值,最终成为
H×W
维度的激活函数。这样每个 RoI 虽然大小不同,但激活函数的维度相同了。
RoI Pooling 层 - back propagation
在上面我们可以看到 RoI Pooling 层可以近似理解为一个
pooling size
可变的max pooling 层,那么做 back propagation 时,偏导数值肯定和 max pooling 类似了。
回顾一下 max pooling 层的偏导数值的计算方式。假设 max pooling 的
pooling size=2×2
,激活值如下图:

图片来源2
这里假设 max pooling 层值1, 3, 2, 4对应的 pooling 区域位置分别为右下、右上、左上、左下。则此时对应卷积层误差敏感值分布为:

图片来源3
当然,上面2种结果还需要点乘卷积层激发函数对应位置的导数值,这里省略。
RoI Pooling 层与 max pooling 区别是 RoI Pooling 层一个输入的激活值,可以对应多个 RoI 输出的激活值。文中使用了简单求和。
初始化网络和fine tune
修改已经 train 好的网络,保持现有参数不变,将最后面的 pooling 层换为 RoI pooling 层,最后一个全连接层改为两个全连接层,后面分别接 softmax 层(K + 1 个输出)和 bounding box regression 层(4 * K 个输出)。
使用前面的方法反向传导微调网络。
Loss function
本文档中的 Loss function 包含两部分,softmax 的差异以及 bounding box 位置的差异。
其中 p=(p0,...,pu,...,pK) 是 softmax 层输出的 K + 1 维的概率值, Lcls(p,u)=−log pu 表示了 groudtruth 是第 u 类时的误差。
[u≥1] 可以理解为 1{u≥1} 。 1{值为真的表达式}=1 , 1{值为假的表达式}=0 。

图片来源 4
作者认为梯度变化小的话更准确一些。
截断 SVD - Truncated SVD
在测试时作者发现神经网络大量的时间都是用在全连接层,假设 weight matrix 是 u×v 大小,类似 PCA ,做了一个截断 SVD 近似。
PCA 是对 WTW 做近似,截断 SVD 是对 W 近似。
这样一个全连接层就可以用两层表示了,一层是
4. 实验部分
文章使用了三种深度学习模型初始化神经网络,分别是AlexNet(S),VGG_CNN_M1024(M)和 VGG16(L)。可以看到 Fast R-CNN 确实能够得到最优的 mAP 值。
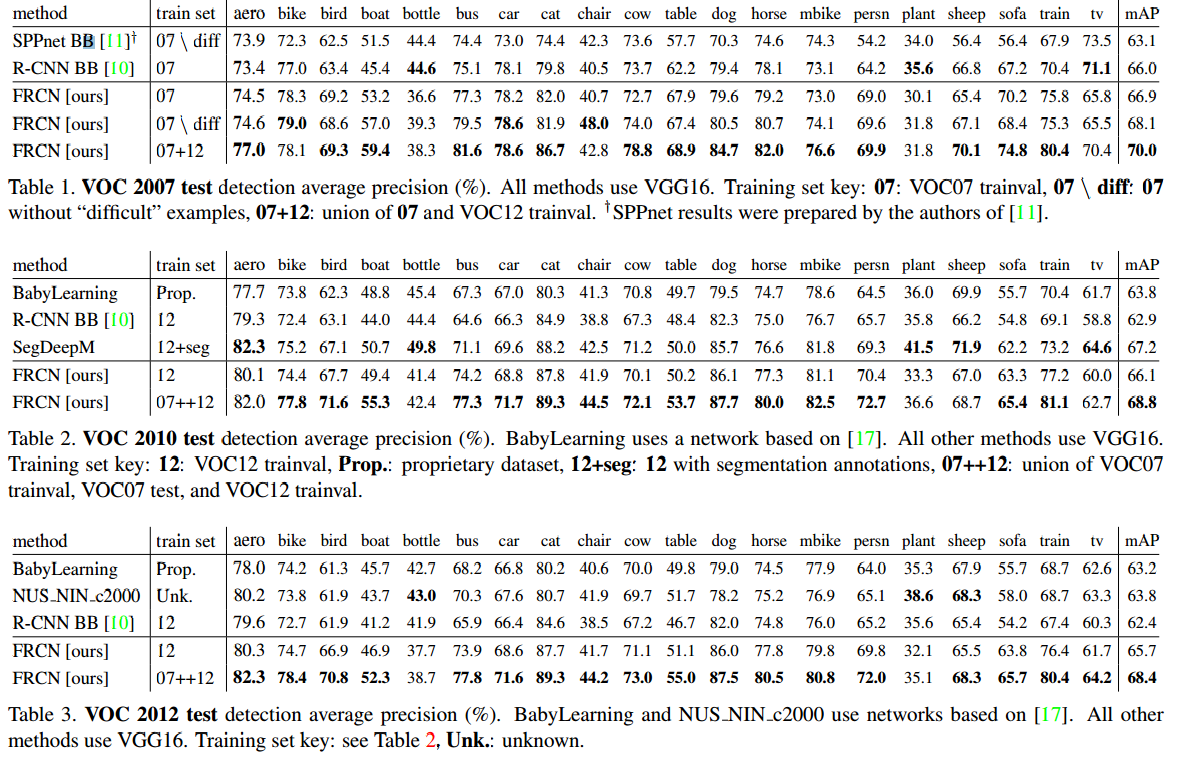
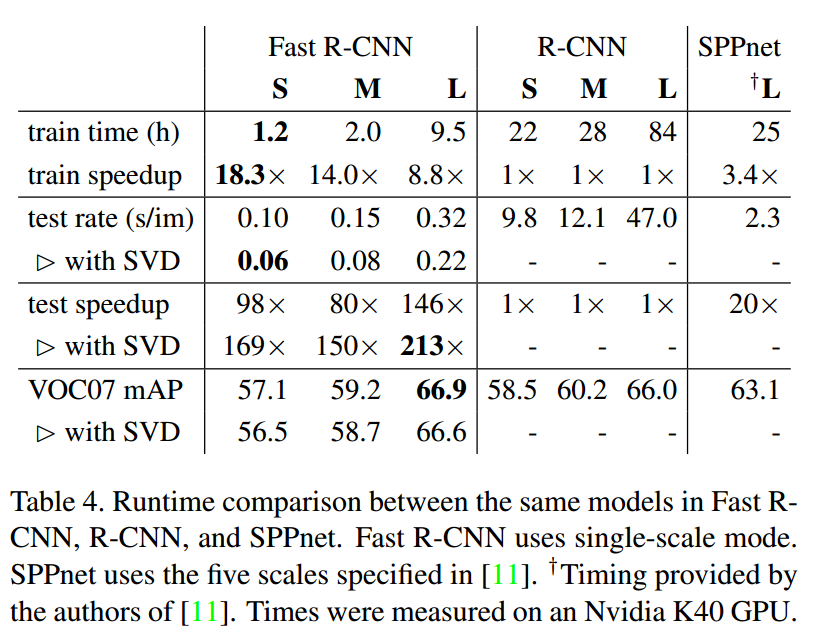
作者又对比了几种方法的用时,速度有极大提升:
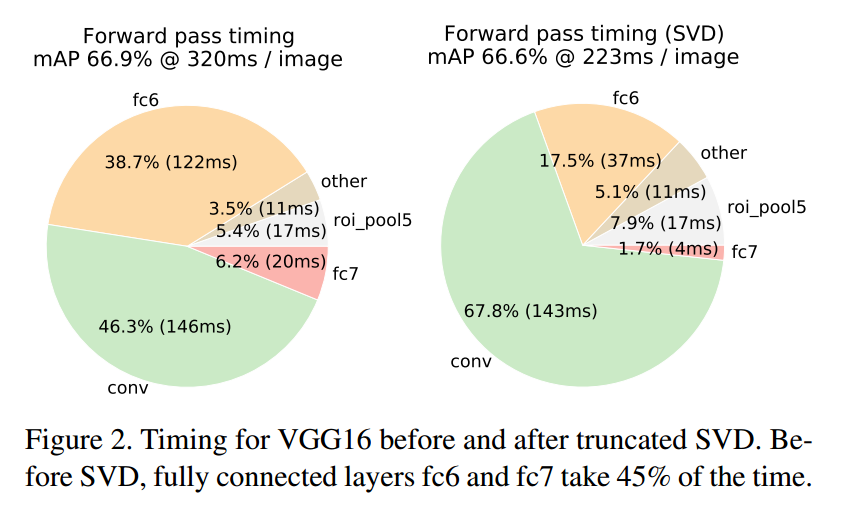
还有使用截断 SVD 之后对 mAP 和速度的影响,mAP下降0.3%但速度提升30%:
接下来作者又通过实验论证了几个问题:
Loss function 是否合理
不使用bounding box regression 和先后执行 softmax/bounding box regression 对结果均有不好影响,还是同时使用两者好。
尺度不变性
两种选择:
- 第一种认为神经网络自己就有学习 scale-invariance 的能力,不用 resize 输入图片
- 第二种认为还是得在输入上做处理,比如金字塔模型
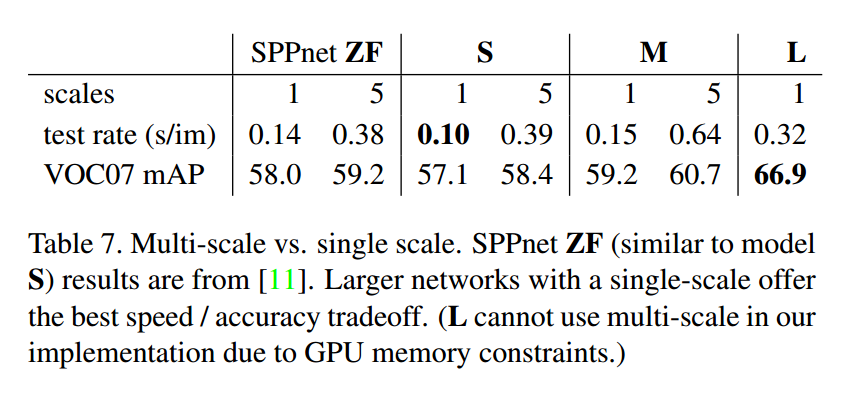
可以看到使用金字塔模型的 mAP 比 single scale高1%,但是用时是 3 - 4 倍。考虑到用时还是使用的 single scale。
训练数据是越多越好么?
是的
Softmax 层比 SVM 分类好么?
好的不多,mAP 大 0.1% 左右,但是结构更加简单了。
越多 proposal 越好么?
不是,应该是越准确越好。

图片来源5















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









