







前言
AingDesk 是一款由国内团队开发的开源 AI 客户端工具,致力于零门槛实现本地化 AI 部署与管理。
通过可视化界面,用户可一键将 DeepSeek、Llama 等上百款主流 AI 模型部署至个人电脑,同时集成个人知识库管理和深度联网搜索功能,实现“本地算力+云端智能”的混合架构。
开源地址:https://github.com/aingdesk/AingDesk
国内镜像地址:https://kkgithub.com/aingdesk/AingDesk
官方下载地址:https://www.aingdesk.com/zh/download.html核心功能
- 一键部署DeepSeek或其他AI模型
- 操作简单
- 内置聊天界面
- 可在线分享给朋友使用
技术亮点
- 可视化一键部署
模型管理:AI 的百宝箱
① 智能推荐:根据电脑配置(CPU/GPU/内存)自动推荐可流畅运行的模型版本,如 1.5B 轻量级模型适配低配设备,70B 参数模型支持高性能硬件。
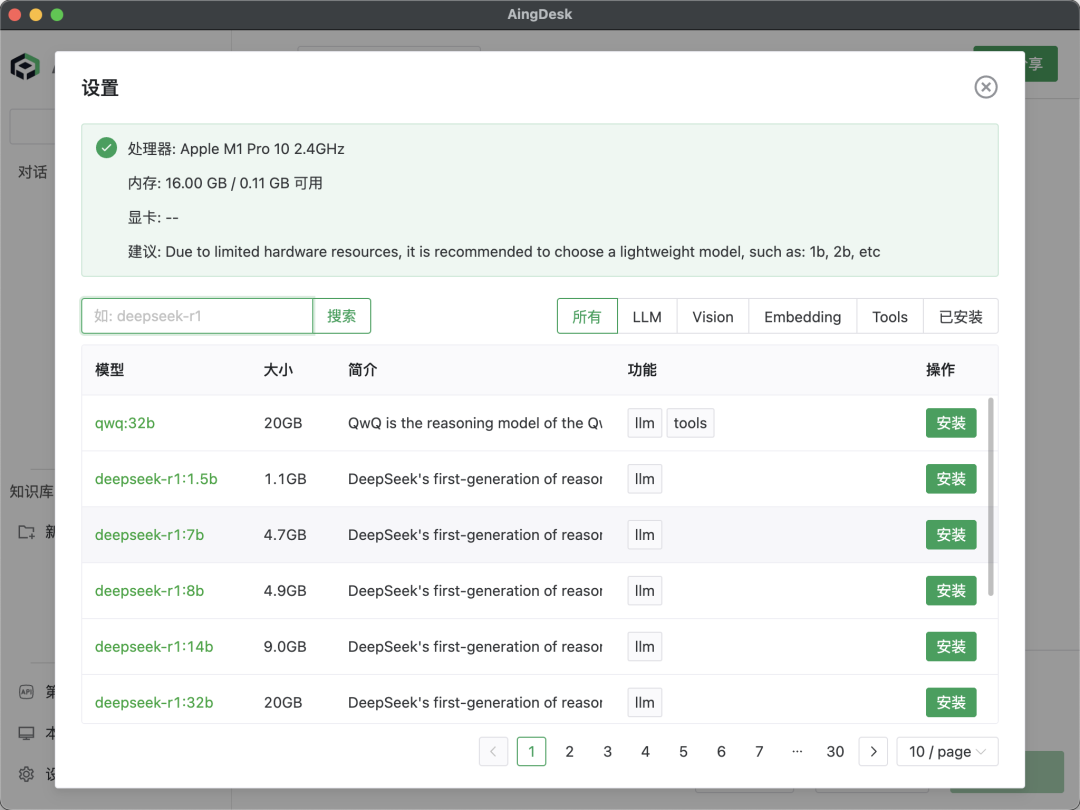
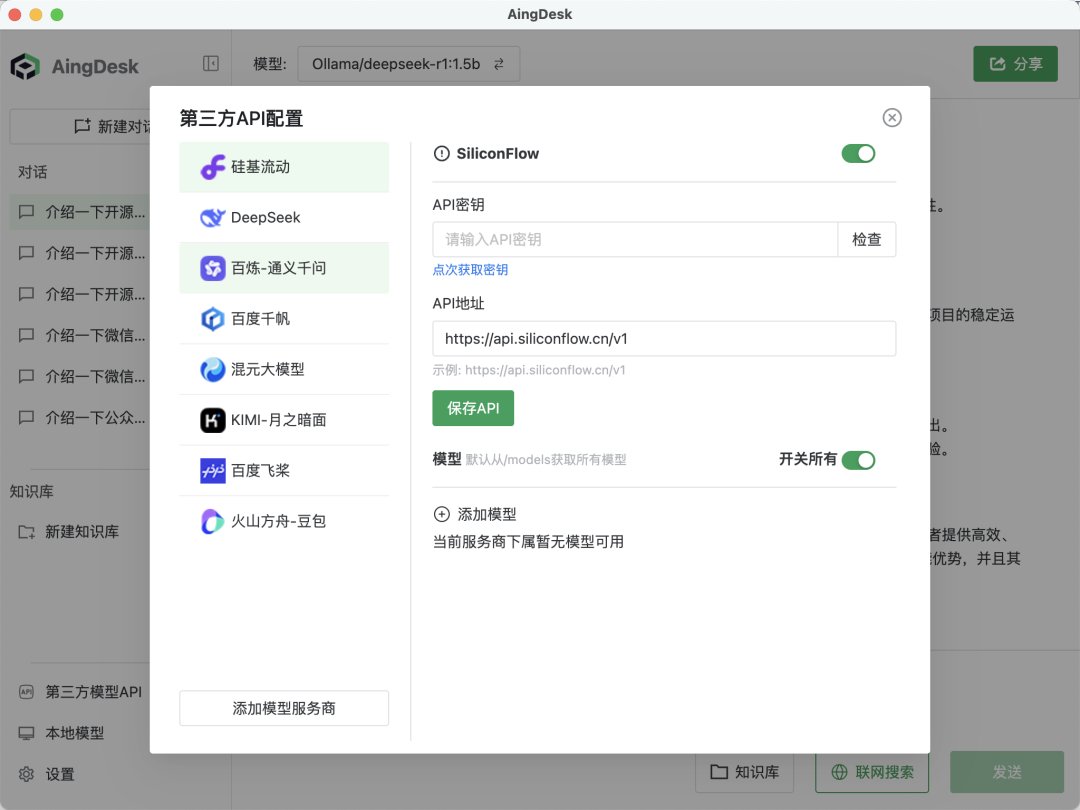
② 多模型支持:支持 DeepSeek 全系列、Qwen、Llama 等上百款模型,同时支持第三方 API 配置,满足学术研究、代码生成等场景需求。
③ 一键部署:无需命令行操作,点击即完成模型下载、环境配置和启动,例如部署 DeepSeek-R1 仅需3分钟。
个人知识库
① 智能归档:支持本地文档(PDF/TXT/Markdown等)一键导入,通过向量模型自动分类、打标,构建结构化知识体系。

② 秒级检索:结合语义搜索技术,快速定位文档片段,可联动分析多个文档中的相关数据。
③ 本地隐私保护:数据全程离线处理,避免敏感信息外泄,适合企业内网或科研场景。
深度联网:打破信息茧房
① 多引擎聚合:集成百度、搜狗、360等搜索引擎,实时获取最新信息。例如询问“宝塔面板最新功能”,AI会综合多个网页内容生成时效性回答。
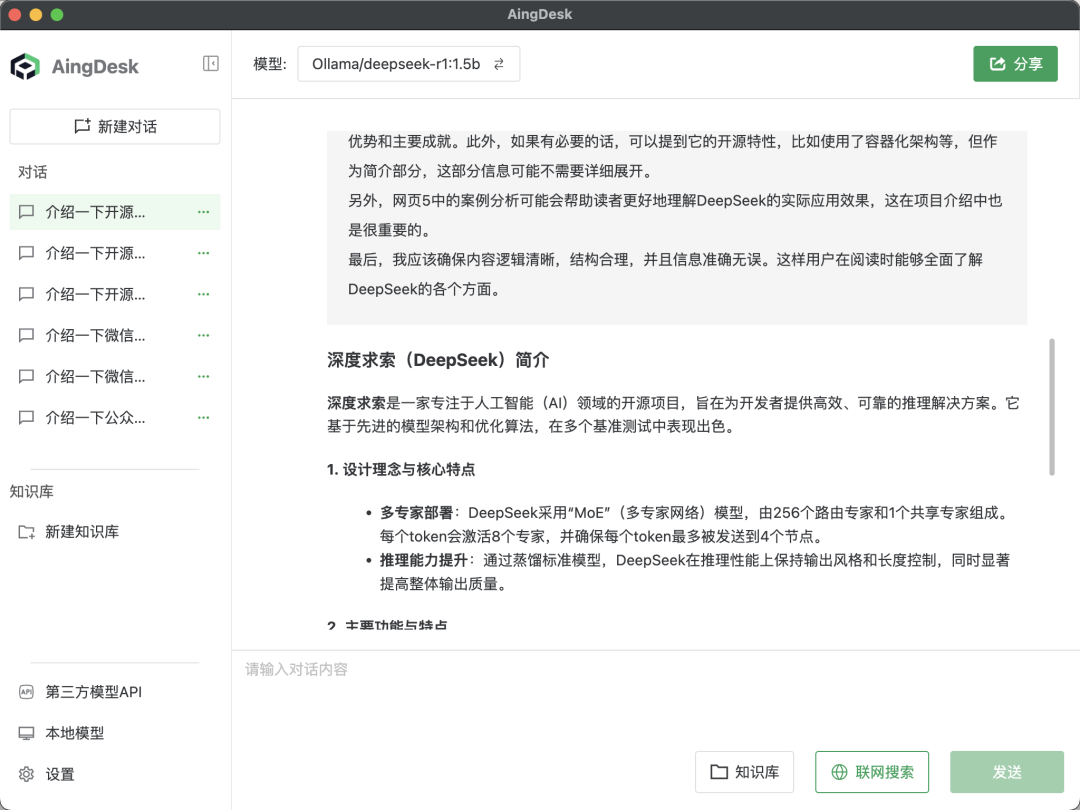
② 动态数据增强:弥补本地模型参数限制,通过联网检索提升答案准确性。测试显示,联网后 DeepSeek-1.5B 模型回答质量提升40%。
模型共享
① 链接分享:生成专属 URL,通过微信/QQ等工具共享本地模型使用权,支持权限控制(如限时/限次访问)。
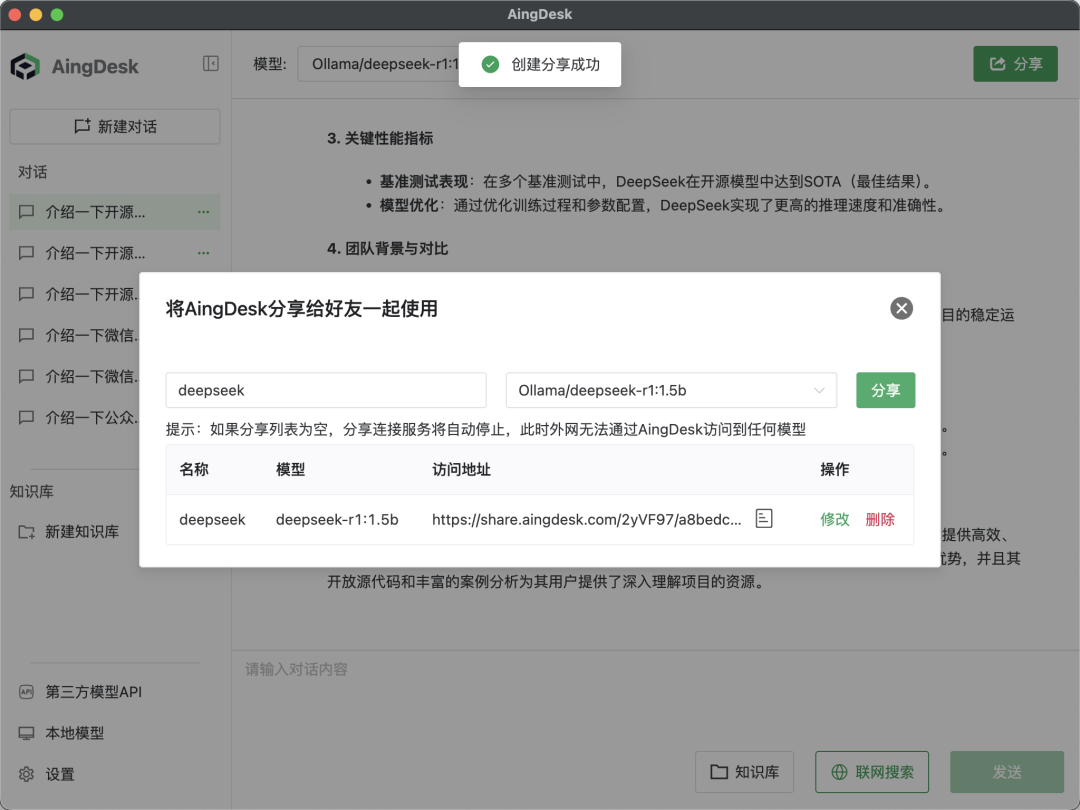
② 多端互通:办公室部署的模型可被宿舍电脑直接调用,实现算力资源共享,降低团队 AI 使用成本。
③ 推荐配置:


















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









