





 这篇文章是香港理工大学郑元庆副教授团队在2020年IEEE INFOCOM(IEEE International Conference on Computer Communications)会议上的文章,且获得了该会议的最佳论文奖(Best Paper Award in IEEE INFOCOM 2020),主要内容是利用声学信号进行手势识别,所提出的RobuCIR解决了UltraGesture存在的频率选择性衰落以及训练数据较少的问题。
这篇文章是香港理工大学郑元庆副教授团队在2020年IEEE INFOCOM(IEEE International Conference on Computer Communications)会议上的文章,且获得了该会议的最佳论文奖(Best Paper Award in IEEE INFOCOM 2020),主要内容是利用声学信号进行手势识别,所提出的RobuCIR解决了UltraGesture存在的频率选择性衰落以及训练数据较少的问题。
在此记录一下本人对此文章的阅读与浅薄的理解,水平有限,能力一般,仅代表个人观点,文章具体内容请参考原文。
PDF: https://www4.comp.polyu.edu.hk/~csywwang/papers/infocom2020.pdf
Presentation Video: http://www4.comp.polyu.edu.hk/~csyqzheng/video/RobuCIR.mp4
Citation: Wang Y, Shen J, Zheng Y. Push the limit of acoustic gesture recognition[J]. IEEE Transactions on Mobile Computing, 2020.
文章目录
Abstract
随着智能设备及其应用的日益普及,利用手势进行控制的设备越来越受到人们的关注。最近的一些研究工作利用声音信号来跟踪手的运动和识别手势。然而,由于频率选择性衰落(frequency selective fading)、干扰(interference)和训练数据不足(insufficient training dataa),它们的鲁棒性较差。本文提出了RobuCIR,可以在不同的使用场景下工作,具有较高的准确性和鲁棒性。RobuCIR采用跳频机制( frequency-hopping mechanism)来缓解频率选择性衰落,避免信号干扰。为了进一步提高系统的健壮性,我们研究了一系列基于少量收集数据的数据增强技术,以模拟不同的使用场景。增强数据用于有效地训练神经网络模型,并处理各种影响因素(例如,手势速度、到收发器的距离等)。实验结果表明,RobuCIR能够识别15个手势,并且在准确性和鲁棒性方面优于SoTA。
I. INTRODUCTION
Motivation
无接触手势识别技术促进了人机交互(human-computer interaction, HCI)方法,使用户能够在无任何身体接触的情况下控制数字设备。想象一下,我们可能只是在家里的智能音响附近做一个手势,就能切换音乐,在车内聊天时控制扬声器音量,在不触碰设备的情况下拒绝会议来电,或者在VR/AR应用程序中实现无接触人机交互。这些无接触系统提供身临其境的用户体验,并支持游戏、智能家居和教育领域的各种新应用。除了准确的识别之外,这些应用程序在各种使用场景下都需要高鲁棒性。本文旨在设计一个鲁棒的无接触手势识别系统,实现准确、鲁棒的手势识别。
Prior works and limitation
现有的基于射频(RF-based)的人机交互技术探索了使用无线信号控制设备的潜力。此类技术需要专门的硬件(如USRP,FMCW雷达),这会增加成本,并且在某些地区禁止部署。最近的声传感系统利用嵌入智能设备中的扬声器和麦克风,实现无接触运动跟踪。FingerIO能够通过发送OFDM调制的声学信号并分析由运动对象引起的信号变化,准确跟踪运动对象(例如,挥动的手)。LLAP能够通过测量接收信号的相位变化来跟踪手指的运动。Strata通过估计反射信号的信道脉冲响应(Channel Impulse Response, CIR),在跟踪一个移动对象时实现了更高的精度。
这些工作将整个手指/手建模为单个反射点,忽略了弱多径信号。这样的单反射模型可以有效地提高其跟踪一个移动对象的性能。然而,由于手指运动相对复杂,将手建模为单个反射点无法为手势识别提供足够的分辨率。例如,为了识别伸展或挤压手势(如图1所示),我们需要同时区分和跟踪五个手指。由于很难精确模拟复杂的信号反射,最近的工作试图利用神经网络从接收信号中自动提取有效特征。例如,UltraGesture使用深度神经网络从测量的CIR幅度中提取特征,以识别不同的手势。然而,由于训练数据不足,训练后的模型在实践中无法处理各种实际使用场景。
Challenges
由于手势运动的复杂性,实现一个鲁棒的声学手势识别系统是一项非常困难的任务。基于声学的手势识别的一个挑战性问题是频率选择性衰落( frequency selective fading, FSF),这是由于声学信号的多径传输以及扬声器和麦克风在高频下的失真(例如≥ 18KHz)。以前的工作只发送固定频率的声音信号,在特定环境中,可能会经历信号幅度的急剧衰减。可以同时在多个频率上传输声学信号,以减轻FSF的影响和高频下的信号失真。然而,处理多频率信号所涉及的计算成本很高,难以满足轻量级智能设备(例如智能手表)的实时处理要求。另一个实际挑战来自训练数据不足。为了确保手势识别的鲁棒性,神经网络需要足够的训练数据来覆盖不同实际场景下手势的不同变化。实际上,难以从用户那里收集足够的培训数据且不切实际。
Our solution
我们提出了RobuCIR,这是一种基于智能手机传输的声音信号的鲁棒手势识别系统,在各种使用场景下都能达到较高的识别精度。RobuCIR可以识别15个标准化手势,如图1所示。RobuCIR可以检测到距离智能手机约50厘米的手势。
采用跳频(frequency hopping )来缓解频率选择性衰落,并仔细设计低通滤波器以避免子帧间干扰(如III-B所述)。特别是,我们调制已知的基带信号,上变频到不同的频率,并在每个频率周期性地发射。我们将这种周期性信号视为信道测量帧,它由不同频率的多个子帧组成。为了进一步提高RabuCIR的鲁棒性,不同于仅利用幅度分量的先前工作,我们综合考虑幅度和相位分量来捕获更多的多径信息。我们注意到相位分量通常对干扰和噪声更具鲁棒性,有望实现高精度定位和跟踪。
为了解决缺乏训练数据的问题,我们没有手动收集所有训练数据,而是收集少量原始数据,并应用一系列选择性数据增强技术来增强数据。这种数据增强方式来自我们的实验观察,即不同使用场景(例如,不同的手势速度、到收发器的距离、NLOS、噪声)下的CIR测量变化会产生不同的模式,这些模式是可模拟的,并与手势变化相关。因此,RobuCIR可以处理各种使用场景,这些场景可能不是由原始数据完全捕获的,而是由增强数据捕获的。据我们所知,我们是第一个将CIR测量的变化与不同的使用场景相关联的人。如图1所示,不同的手势生成具有不同模式的不同CIR图像,这些图像通过最小二乘信道估计技术进行估计。为了识别手势,我们通过监督学习使用神经网络训练分类器。分类器由CNN和LSTM网络组成,用于从增强数据中自动提取复杂特征并进行手势识别。

Our contributions
整体设计使我们能够实现更高的信道测量分辨率和足够的训练数据,同时减轻FSF和ISI (帧间干扰,inter-subframe interference),而不会对轻量级智能设备造成额外的计算开销。RobuCIR在各种使用场景下对15个手势的识别准确率达到98.4%。
Contributions如下:
- 通过周期性地传输不同频率的声学信号来解决多径效应引起的频率选择性衰落的问题。
- 利用CIR测量和手势变化的相关性来克服训练数据不足的问题。扩充数据自动生成,无需用户参与。
- 实验结果表明,在各种使用场景下,RobuCIR在准确性和鲁棒性方面优于最新的工作。
II. BACKGROUND
现有的基于声学信号的手势识别系统通过测量反射信号帧的CIR来检测手指/手的运动。发射机调制已知信号,上变频为高频fc,并连续发送该音频信号帧。然后,信号帧从移动的手指/手反射并被接收器接收。接收到的帧被下变频以生成基带信号的虚部和实部。声音传播信道可以建模为线性时不变系统,可以有效地对声音沿多条传播路径的传播延迟和信号衰减进行建模。接收到的信号可以在数学上表示为
r
[
n
]
=
s
[
n
]
∗
h
[
n
]
r[n]=s[n] ∗ h[n]
r[n]=s[n]∗h[n],其中
h
[
n
]
h[n]
h[n]表示声音传播信道的信道冲激响应(CIR),
r
[
n
]
r[n]
r[n]和
s
[
n
]
s[n]
s[n]分别表示接收信号和发射信号。
实际上,可以通过发送已知信号帧作为探针来估计CIR。对于接收到的帧,最小二乘信道估计方法可以估计CIR。最小二乘信道估计测量信道
h
=
arg min
h
∣
∣
r
−
M
h
∣
∣
2
h=\argmin_{h}||r-Mh||^2
h=hargmin∣∣r−Mh∣∣2,其中M是由发送的循环正交码(例如,训练序列码(TSC),巴克码)组成的训练矩阵。CIR的测量用一组复数表示,其中每个复数测量一定传播延迟范围内的信道信息,可以得到相应的CIR幅度和相位。
III. SYSTEM DESIGN
A. Overview
图2是RobuCIR的整体结构。

RobuCIR由三个主要部件组成,即收发器(Transceiver)、信道估计器(Channel Estimator)和手势识别器(Gesture Identifier)。在Transceiver中,扬声器播放用于信道测量的不可听见的帧,麦克风记录接收到的帧。在每个帧内,载波频率在多个频率之间跳跃以减轻频率选择性衰落(FSF)。然后,Channel Estimator使用最小二乘信道估计来估计信道冲激响应(CIR)。最后,Gesture Identifier将在一定时间内测量的CIR相位和幅度分别视为CIR相位图像和CIR幅度图像。为了提高系统的鲁棒性,我们对每个CIR图像执行数据增强,以便扩充的数据能够覆盖各种实际使用场景。因此,使用增强数据训练的最终模型可以处理各种环境(例如,手势速度、距离、噪声等)。增强数据用于训练CNN自动提取特征,以及训练LSTM网络执行手势识别。
B. Design of Transceiver
图3为Transceiver的设计。
Transceiver由一个扬声器(用作发射器)和一个麦克风(用作接收器)组成,它们在单个设备中并置并同步。发射机发送预定义的信号帧,接收机通过分析接收到的信号帧来测量CIR。具体而言,发射机发送26位训练序列码(TSC),该码具有良好的自相关特性,有助于信道测量。然后对TSC进行上采样,并在传输之前将其上变频为载波频率fc。为了确保传输的帧是听不见的,载波频率被设置为高于18KHz。为了避免子帧间干扰(ISI),以前的工作在帧之间添加了保护间隔(guard intervals, GI),在帧之间添加零采样(zero samples ),以便当前帧的反射不会在后续帧中混合。
1) 减少频率选择性衰落(Mitigate Frequency Selective Fading)
现有工作将预定义的TSC符号调制并上转换为单一频率。基于单一频率的方法可能会受到FSF的影响,因为从多个对象反射的音频信号可能会相互叠加,从而大大降低系统性能。为了更好地理解FSF如何影响信道测量,我们进行了实验,并测量了在多个频率下传输时的CIR幅度和相位。在实验中,我们在收发机前做了5次推拉(push and pull)手势。我们以三种频率发送BPSK调制的TSC。
图4显示了实验期间测得的CIR幅值。
在图中,X轴表示时间,而Y轴表示CIR的tap position(不知道该如何翻译)。亮度表示CIR的大小。每个tap对应一定的延迟范围,具有相似传播延迟的反射信号汇总在同一tap中。在图4中,当在
f
c
1
f_{c1}
fc1(上)传输时,由于拉和推活动,CIR幅度发生了变化。当在
f
c
2
f_{c2}
fc2(中)处传输时,由于频率选择性衰落,CIR幅度显著降低,并呈现不太清晰的图案。与对CIR幅度的影响类似,频率选择性衰落也会影响不同频率下的相位测量。实验结果表明,如果处理不当,频率选择性衰落会严重影响信道测量结果,导致手势识别的精度和鲁棒性下降。
在多个频率(例如OFMD)下传输可以增强对FSF的鲁棒性,因为不同的频率分量不太可能同时以破坏性方式叠加。然而,由于FFT和IFFT运算,现有的基于多频率的方法会产生较高的计算开销。相反,我们采用跳频来在不同的载波频率(即
f
c
1
f_{c1}
fc1、···、
f
c
N
f_{cN}
fcN)下周期性地发射信号以减轻FSF。特别地,我们以特定载波频率(例如,
f
c
i
f_{ci}
fci)发射,并跳到相邻频率(例如,
f
c
j
f_{cj}
fcj)。因此,整个信道测量帧由以N个不同频率发送的N个子帧组成。
在发射机发射第一个样本后,接收机立即开始记录反射帧。要检测接收帧中第一个样本的位置,计算发送和接收音频样本的皮尔逊相关系数(PCC),并定位相关峰值。一旦检测到帧的第一个样本,由于子帧的固定长度,当前帧和后续帧中的子帧的边界可以容易地定位并完全同步。注意,在每个接收帧内,频率周期性地从
f
c
1
f_{c1}
fc1跳到
f
c
N
f_{cN}
fcN。接收机通过将每个子帧与其对应的
c
o
s
(
2
π
f
c
i
t
)
cos(2{\pi}f_{ci}t)
cos(2πfcit)和
−
s
i
n
(
2
π
f
c
i
t
)
-sin(2{\pi}f_{ci}t)
−sin(2πfcit)相乘来下变频该帧。然后,下变频帧通过低通滤波器过滤出高频分量。最后,使用相同频率的复向量
r
(
t
)
r(t)
r(t)提取CIR幅度和CIR相位。
2) 消除帧间干扰(Remove Inter-Subframe Interference)
这种下变频技术可以自然地消除ISI。为了了解这种下变频技术如何避免子帧间干扰,我们假设当前子帧的频率为
f
c
j
f_{cj}
fcj,这可能会受到前N个子帧的干扰。因此,当前接收到的子帧可以表示为
y
(
t
)
=
∑
i
=
1
N
+
1
A
i
c
o
s
(
2
π
f
c
i
t
+
θ
i
)
y(t)=\sum_{i=1}^{N+1}A_icos(2{\pi}f_{ci}t+\theta_i)
y(t)=∑i=1N+1Aicos(2πfcit+θi),其中
A
i
A_i
Ai是子帧的振幅,
θ
i
\theta_i
θi是多径效应引起的相位偏移,
i
∈
[
1
,
N
]
i\in[1,N]
i∈[1,N]。通过使用
c
o
s
(
2
π
f
c
j
t
)
cos(2{\pi}f_{cj}t)
cos(2πfcjt)下变频,我们得到:
∑
i
=
1
N
+
1
A
i
c
o
s
(
2
π
f
c
i
t
+
θ
i
)
×
c
o
s
(
2
π
f
c
j
t
)
=
∑
i
=
1
N
+
1
A
i
2
[
(
c
o
s
(
2
π
(
f
c
i
+
f
c
j
)
t
+
θ
i
)
⏟
h
i
g
h
t
−
f
r
e
q
u
e
n
c
y
c
o
m
p
o
n
e
n
t
+
c
o
s
(
2
π
(
f
c
i
−
f
c
j
)
t
+
θ
i
)
⏟
l
o
w
−
f
r
e
q
u
e
n
c
y
c
o
m
p
o
n
e
n
t
)
]
\sum_{i=1}^{N+1}A_icos(2{\pi}f_{ci}t+\theta_i)\times{cos(2{\pi}f_{cj}t)}= \sum_{i=1}^{N+1}\frac{A_i}{2}[(\underbrace{cos(2{\pi}(f_{ci}+f_{cj})t+\theta_i)}_{\bf{hight-frequency \,component}}+\underbrace{cos(2{\pi}(f_{ci}-f_{cj})t+\theta_i)}_{\bf{low-frequency \,component}})]
∑i=1N+1Aicos(2πfcit+θi)×cos(2πfcjt)=∑i=1N+12Ai[(hight−frequencycomponent
cos(2π(fci+fcj)t+θi)+low−frequencycomponent
cos(2π(fci−fcj)t+θi))]
对于上式中的低频分量,有:
∑
i
=
1
N
+
1
A
i
2
[
(
c
o
s
(
2
π
(
f
c
i
−
f
c
j
)
t
+
θ
i
)
=
A
i
2
c
o
s
(
θ
j
)
+
∑
i
=
1
N
A
i
2
[
(
c
o
s
(
2
π
(
f
c
i
−
f
c
j
)
t
+
θ
i
)
\sum_{i=1}^{N+1}\frac{A_i}{2}[(cos(2{\pi}(f_{ci}-f_{cj})t+\theta_i)=\frac{A_i}{2}cos(\theta_j)+\sum_{i=1}^{N}\frac{A_i}{2}[(cos(2{\pi}(f_{ci}-f_{cj})t+\theta_i)
∑i=1N+12Ai[(cos(2π(fci−fcj)t+θi)=2Aicos(θj)+∑i=1N2Ai[(cos(2π(fci−fcj)t+θi)
式1中的高频分量和式2中的第二项能够通过设置一个截止频率为不同载波频率之差(例如:
m
i
n
(
∣
f
c
i
−
f
c
j
∣
)
,
i
≠
j
min(|f_{ci}-f_{cj}|),i\neq{j}
min(∣fci−fcj∣),i=j)的低通滤波器同时去掉。此外,截止频率应超过子帧的频率,以便能够准确地恢复子帧。经过低通滤波器过后,我们得到了
A
i
2
c
o
s
(
θ
j
)
\frac{A_i}{2}cos(\theta_j)
2Aicos(θj),其中
θ
j
=
c
o
s
(
2
π
f
c
j
τ
j
)
\theta_j=cos(2{\pi}f_{cj}\tau_j)
θj=cos(2πfcjτj),
τ
j
\tau_j
τj是传播延迟,由于声速以知,可以通过
τ
j
\tau_j
τj来计算接收器与反射位置之间的距离。
为了评估我们设计的有效性,我们在图5中进行了一个实验,比较了使用/不使用我们的滤波方法时的ISI。
我们在
f
c
1
f_{c1}
fc1发送第一个子帧,然后在
f
c
2
f_{c2}
fc2发送第二个子帧,并且载波频率在第320个采样点附近跳变。在实验中,为了更好地可视化ISI,第一个子帧传输TSC比特,而第二个子帧包含零样本,仅用于测量第一个子帧是否会影响第二个子帧。图5(a)展示了使用两个子帧的相同载波频率
f
c
1
f_{c1}
fc1下变频的接收帧。我们看到,发射的信号确实在跳频后出现反射,这可能使在同一
f
c
1
f_{c1}
fc1上发射的第二个子帧失真。图5(b)展示了当第一个子帧使用频率
f
c
1
f_{c1}
fc1下变频,而具有零采样的第二个子帧使用相邻频率
f
c
2
f_{c2}
fc2下变频时的接收信号。我们看到在
f
c
1
f_{c1}
fc1传输的第一个子帧被正确地下变频,并且,在第二个子帧中没有干扰或失真。实验结果表明,该滤波方法能有效地消除码间干扰。
提示:这一段理解得不是很到位,建议看原文。
3) 提取有效CIR相位和幅值(Extract Effective CIR Phase and Magnitude)
所测量的信道既包括环境中的静态对象(例如,从扬声器到麦克风、墙壁、桌子等的直接路径),也包括动态对象(例如,路过的人等)。因此,CIR测量值是传感范围内静态和动态物体反射的所有信号的组合。为了避免静态物体以及与手势无关的运动物体的影响,我们需要从靠近收发器的手和手指中提取反射信号。
Focus on nearby objects. 为了减轻远处移动物体的影响,我们需要过滤掉远处物体的反射信号,并且只将手和手指的反射信号保持在靠近收发器的位置。在信道测量中,CIR的每个tap对应于特定的延迟范围,具有相似传播延迟的反射信号被分组到一个tap中。因此,tap index(图4中的Y轴)表示反射物体和收发器之间的距离:指数越小,越接近收发器。 因此,可以根据tap L的数量设置检测范围
D
r
D_r
Dr,因为有
D
r
=
L
×
v
2
f
s
D_r=L\times{\frac{v}{2f_s}}
Dr=L×2fsv,其中
v
v
v是声速,
f
s
f_s
fs是采样频率。通过调整检测范围,只保留几个有效的taps,我们可以滤除一定范围外的物体造成的影响,以提高系统的鲁棒性。该方法确保在探测范围内进行稳健的CIR测量,即使有人在探测范围外的附近行走。
Focus on moving objects. CIR的相位和幅度的变化如图6(a)所示:
O
C
→
\overrightarrow{OC}
OC表示具有恒定幅值和相位的静态分量,
C
A
→
\overrightarrow{CA}
CA和
C
B
→
\overrightarrow{CB}
CB是具有不同相位和幅值的动态分量。从扬声器到麦克风的直接传输和来自环境的静态背景反射共同构成静态分量。由于动态分量,
O
A
→
\overrightarrow{OA}
OA和
O
B
→
\overrightarrow{OB}
OB的组合分量也相应地改变。注意,CIR测量仅测量组合分量,而静态和动态分量无法直接测量。为了消除静态分量并从测量的CIR中提取动态分量,我们计算了t时刻和t-1时刻两个连续复杂样本之间的CIR差。注意发射机和接收机的硬件在整个实验中引入恒定的相位偏移,也可以通过计算两个相邻测量值之间的相位差来消除。通过这样做,可以提取动态分量,并且可以消除周围静态对象造成的影响。
图6(b)和图6(c)显示了从第III-B1节第二次实验中提取的相同载频下相同tap的CIR幅值和相位。
由于从扬声器到麦克风的直接传输,原始CIR幅度和相位的模式不清晰(图6(b)和图6(c)中的上图)。然而,我们观察到,提取的相位变化明显呈现线性增加的模式。此外,我们观察到CIR相位和幅度的变化不同,因为幅度捕获信号衰减,而相位捕获传播距离。因此,我们可以使用这两种测量方法获得更可靠的信息。
C. Gesture Identifier
手势识别器的主要目标是对CIR测量值进行分类并识别不同的手势。我们注意到,在多个taps上经过一定时间的CIR幅度和相位可以分别视为CIR幅度图像和CIR相位图像。从不同频率提取的CIR图像可视为RBG通道。将CIR测量值作为张量输入到神经网络中以便进行分类。
然而,神经网络需要大量有效的训练数据才能达到较高的精度和鲁棒性。理想情况下,训练数据应涵盖各种实际场景。然而,要在实践中收集足够数量的高质量数据需要花费很长时间和大量精力。为了减轻数据收集的痛苦,我们进行了数据增强,以丰富我们的训练数据,从而使扩充的数据能够反映CIR测量的不同变化,而无需在所有可能的场景中手动收集数据。
1) 数据增强(Data Augmentation)
数据增强技术依赖于我们的关键观察,即CIR测量值随手势变化而变化(例如,手势速度、角度、位置等)。根据我们最初的测量结果,我们主要考虑了在实际使用场景中可能影响CIR数据的五个因素,包括手势速度、到麦克风的距离、到达角、视线路径阻塞和背景噪声。然后,我们对原始CIR数据(例如,平移和缩放)应用图像处理中广泛使用的数据增强技术,以便增强的CIR数据能够覆盖潜在场景,并且经过训练的模型能够处理上述影响因素。
到接收器的不同距离。 在商用智能手机中,扬声器和麦克风通常并置并内置在单个设备中。为了测量手和收发机之间距离的影响,我们在手和收发机之间的距离从0厘米到20厘米之间,然后到20厘米到40厘米之间分别执行推拉(push and pull)操作。图7(a)和图7(b)分别显示了CIR幅度和相位。
比较图7(a)和图7(b)(上),我们观察到CIR幅度测量中tap指数的垂直漂移。这是因为手势在与收发器的不同距离处执行。更大的tap index表示到收发器的距离更远。同样,我们在CIR相位测量中发现相应的位移。如图7(a)和图7(b)(下)所示,我们在CIR相位测量中观察到类似的线性增加模式。因此,在不同距离处执行的手势可以通过tap中的垂直漂移来模拟。
不同的速度。 为了说明手势的不同移动速度的影响,我们在20厘米内以相对较慢的速度在收发器前面执行推拉操作。图8显示了所有taps的CIR幅度和一个特定tap的CIR相位。
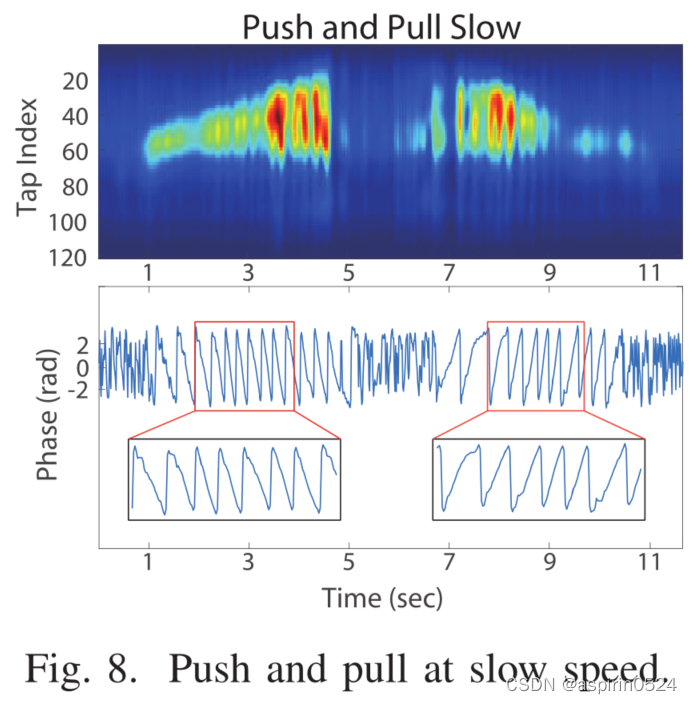
CIR相位旋转表示由移动的手引起的路径长度变化。关键的是,与图7(a)相比,由于速度较慢,与手势相对应的CIR测量值在时间上扩展了CIR幅度和相位。为了补偿不同的手势速度,我们通过水平扩展或收缩原始CIR测量值来模拟不同的速度,从而执行数据增强。
收发器间阻塞。 在没有视线情况下,人们可能会试图控制他们的智能设备。为了模拟这个场景,我们将智能手机放在一个棉袋中,以捕捉移动的手。在图9的上图中,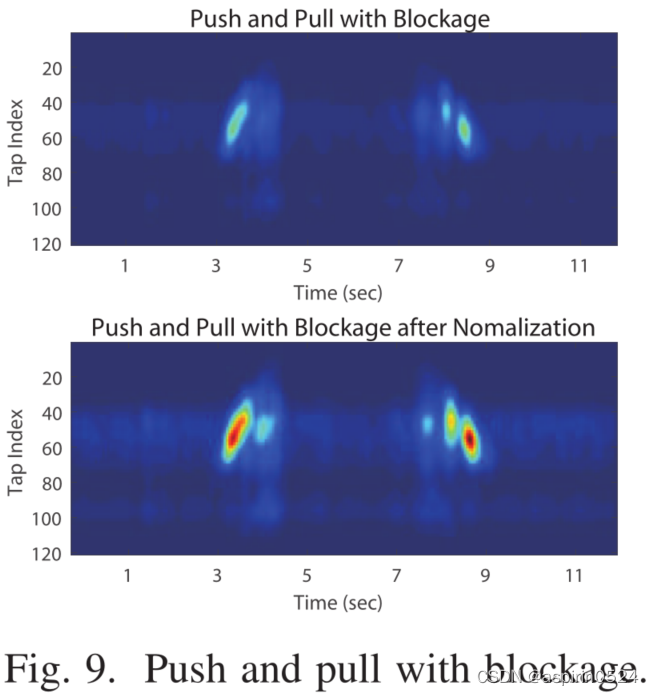
如果我们直接使用原始CIR数据,我们观察到的明亮图案较少。实际上,非视距可能会导致信号衰减,从而导致CIR幅值非常小。为了解决这个问题,我们使用最小-最大归一化(Min-Max Normalization)方法来缩放和归一化CIR幅度测量值。标准化后,所有幅值都将缩放到相同的级别(即0~1) 这样可以减轻信号衰减的影响。图9中的下图显示了上图中原始CIR数据的归一化CIR测量。标准化后,我们观察到与图7(a)中没有任何阻塞的情况相比的类似模式。当我们在收发机和手之间放一张厚纸时,我们观察到一致的图案。相反,由于手的相对移动距离相似,CIR相位测量不会受到很大影响。在所有实验中,我们在数据扩充之前对所有原始CIR数据进行归一化。
嘈杂的环境。 为了评估背景噪声的影响,在CIR测量期间,我们使用智能手机在距离接收器5厘米的地方播放音乐。在这种情况下,接收信号是TSC信号和背景音乐信号的混合信号。然而,我们注意到,音乐所处的频带远低于传输的信号。因此,接收机可以在频域中将发射的不可听见信号与环境中的背景噪声(例如,音乐)分离。
实际上,许多其他背景噪音(例如人声、风扇、空调、交通噪音等)位于低频段,可通过我们的下变频和解调方法进行类似的过滤。因此,在下变频之前不需要添加高通滤波器。换句话说,下变频和解调方法对背景噪声具有固有的鲁棒性。
不同角度。 为了评估到达角对收发机的影响,我们在收发机20厘米范围内以不同角度在收发机周围执行手势。我们将收发器前面的0到180°区域分为三个60° 扇区,并在每个扇区执行多次推拉操作。实验结果表明,当我们从不同角度执行相同的手势时,CIR测量结果显示出与图7(a)中相似的模式。 这是因为扬声器和麦克风都是全向的。事实上,全向扬声器和麦克风广泛应用于商品智能设备中,以实现全方位的声音传播。此外,扬声器和麦克风配置在一个距离较短的设备中。因此,到达角对CIR测量的影响是有限的。因此,我们不单独对不同到达角的数据进行增加。
总的来说,我们发现最后三个因素(即堵塞、噪声和到达角)不需要任何特定的数据增强,而不同的速度和到接收器的距离确实会影响CIR测量,需要仔细处理。不同的用户手尺寸可能会影响CIR测量。然而,通过multiple taps,我们的方法可以减少手部尺寸的影响。我们假设这些手势是在用户站着或坐着时执行的,躯干静止,只移动手。在实践中,人们经常在距离收发器10~50cm的地方,以此可以得出tap index范围为30到150cm。我们保证在此检测范围内能够成功传输和接收音频信号。因此,我们根据目标tap index范围垂直移动原始CIR数据。如果手和收发机之间的距离增加,则可以根据不同的使用场景通过适当调整扬声器音量来自由调整tap index范围。另一方面,我们发现同一手势的速度之间的最大差异通常不超过5×(例如0.4s到2s)。因此,水平调整的倍数从2到5不等。尽管我们的数据集中的最大速度差异高达5×,但数据增强技术不限于此范围,并且可以扩展到更大的范围,以模拟实践中的更多差异(例如,图8中的4s)。我们随机组合上述各种手势速度和距离的设置,并为每个收集的手势增加100倍,以模拟在各种实际场景下执行的手势。
2) 手势识别(Gesture Recognition)
我们将增强后的CIR训练数据输入分类器以识别不同的手势。CNN在图像识别方面取得了重大进展,而LSTM能够处理时间序列数据。因此,我们的分类器由用于提取CIR图像重要特征的CNN和用于手势识别的LSTM网络组成。
具体而言,我们分别处理CIR幅度和相位,并使用两个独立但但结构相同的CNN自动提取特征。我们应用了一个具有三个卷积层的CNN。第一卷积层的每个输入是大小为[K×L×N]的CIR图像,其中L是taps的数目,K表示在某一时段内聚集的连续子帧的数目,N是频率的数目。注意,与真实图像类似,从不同频率提取的CIR图像可被视为不同的图像通道(例如,RGB通道)。我们使用32个大小为[5×5×N]的内核扫描输入图像,然后是一个最大池层,内核为[2×2],步长为2。其余2个卷积层的设计与第一层类似,内核大小为[5×5]和[3×3],内核数分别设置为32和64。激活功能为ReLU。我们设置一个大小为512的全连接层来输出特征向量。然后用两个单独的LSTM分别处理CIR幅值和相位的提取特征。
当执行不同的手势(例如,往上往下、往左往右)时,使用CNN提取的相同特征可能以不同的顺序出现,并且顺序关系到不同手势的区分。与其他传统分类器(即SVN、Random Forest等)不同,LSTM能够在顺序数据中存储上下文信息,可以捕获手势的时间信息。在我们的实现中,LSTM结构将CNN跨时间的多个输出作为一个向量作为输入数据。我们使用一个堆叠的LSTM层,由8个memory cells组成。在LSTM层之后使用softmax预测手势类型。LSTM的输出是一个概率向量,表示不同手势的可能性。注意,我们分别为CIR幅值和相位图像构建两个LSTM,并生成两个概率向量。然后,手势类型由两个概率向量的加权和确定。
IV. EXPERIMENT AND EVALUATION
A. Experiment Setting
参数设置。 为了使用跳频发送信道测量帧,可以应用满足第III-B2节中条件的频率来减轻频率选择性衰落并消除子帧间干扰。在我们的实验中,RobuCIR分别以18KHz、20KHz和22KHz三种频率发出不可听见的信号。我们注意到,在最大音量下播放的声音信号可能仍然会被一些用户听到,特别是在安静的房间里。为了保证声音信号不会给用户带来不便,我们使用了一个滤波器来平滑两个频率之间的突变。用户可以在不影响系统性能的情况下,将音量调节到舒适的水平(例如,最大音量的75%)。在我们的设计中,我们选择了26位TSC,它具有良好的自相关和同步特性。上采样率设置为12。因此,单个TSC符号由12个音频样本表示,每个发送的子帧包含
N
T
S
C
×
12
=
312
N_TSC\times12=312
NTSC×12=312个音频样本,这在传输中需要6.5ms,采样率为48KHz。
数据采集。 我们在Samsung S9 Plus, Samsung S7 Edge 和 Google NEXUS5三个手机上实现了RobuCIR。实验结果表明,通过跳频、标准化和数据增强,智能手机的不同造成的影响(例如,高频信号失真)可以得到缓解。我们邀请8名志愿者(5名男性和3名女性)执行15种手势。在第III-C节所述的5种使用场景下,每个手势重复6次(每只手3次)。用户在距离设备0.5米到1米的位置站着或坐着不动,用相对静止的身体执行手势,并在最高0.5米的检测范围内移动手部。在我们的数据集中,最大的速度差为5×(例如,从0.4s到2s),手势与设备的角度范围为0∼180°。在嘈杂的环境中,我们使用另一部手机作为外部扬声器播放音乐,最大音量放在距离目标设备0.5米的地方。这些手势在不同的时间和不同的环境下执行,其中包含一些规模在10×8×3m³和4×4×3m³之间、布局不同办公室。这些办公室周围都是家具、电脑和小物件,会导致不同的信号衰减。当我们收集数据时,允许有人在靠近目标设备的地方移动。总共收集了3600个真实手势样本。
Benchmark. 我们将性能与最先进的UltraGesture进行比较,作为我们的基准。在幅度测量中,我们将相同数量的taps设置为L=140。我们选择
K
=
32
K=32
K=32和
N
l
s
t
m
=
5
N_{lstm}=5
Nlstm=5,使得LSTM具有
K
×
N
l
s
t
m
×
6.5
m
s
≈
1
s
e
c
K\times{N_{lstm}}\times{6.5ms}\approx1sec
K×Nlstm×6.5ms≈1sec的特征作为输入。
模型训练和手势识别。 我们使用10折交叉验证来评估系统的鲁棒性。每一轮交叉验证涉及使用从6个用户收集的样本训练新模型,并使用从其他2个用户收集的样本进行测试。我们确保训练数据和测试数据在每一轮中从不同的用户和不同的房间收集。
在每一组训练中,我们进行数据增强,比率为100倍。我们注意到,增加的样本与相应的真实场景是一致的。每次训练迭代大约需要65秒。当使用3层CNN和8单元1层LSTM时,模型的大小约为5.5M。我们使用相同规格的高端服务器模拟云/边缘服务器并进行性能评估。
B. Evaluation
系统整体性能。 图10显示了我们的RobuCIR系统在不同环境下(例如,有或没有多路径的房间)执行的所有15个手势的总体混淆矩阵。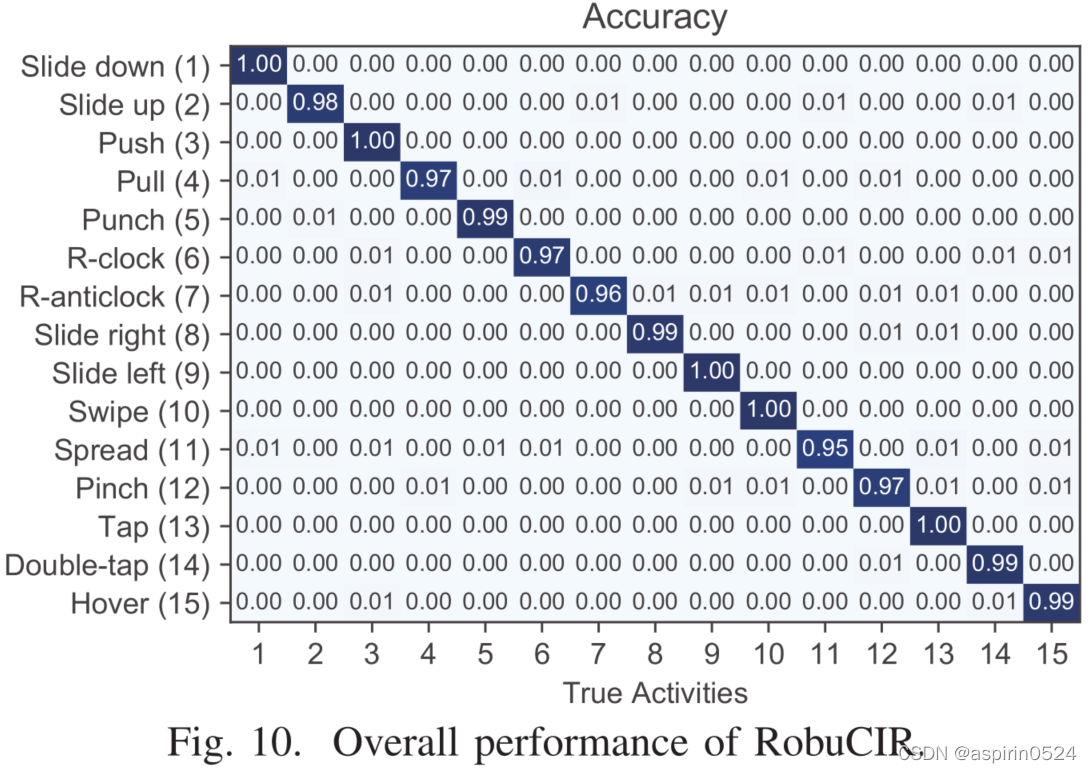
测试数据是在与收发器的不同距离处收集的,志愿者在办公室里以合适的速度进行手势动作。RobuCIR的平均识别准确率为98.4%,即使在不同的使用场景下,每个手势的准确率也超过95%。具有不同信号衰落的不同环境对系统性能的影响有限,因为可以使用CIR taps的数量来设置检测范围,以滤除检测范围外的干扰和多径反射(例如,人四处走动)。我们评估了不同使用场景下的识别精度,如图11所示。
所有手势的准确率都超过96%,这表明RobuCIR在各种场景下都具有很高的鲁棒性。以不同速度和与收发器的不同距离执行手势时的精度略低于其他三种情况,因为这两种情况可能会导致CIR测量的较大变化,而其他三种情况不会对CIR测量产生显著影响。
鲁棒性的提高。 为了评估RobuCIR与现有算法相比的系统鲁棒性,我们将其性能与使用相同数据集进行训练和评估的最新算法UltraGesture进行了比较。我们设置了与UltraGesture相同的参数,并在各种使用场景下评估了RobuCIR和UltraGesture。图12为比较结果。
如图12所示,RobuCIR大大优于UltraGesture,总体识别准确率比UltraGesture高13%。当以不同的速度和与收发器的不同距离执行手势时,RobuCIR精确度超过96%,而UltraGesture的性能显著降低至75%和77%,主要是由于FSF以及这两种情况下对CIR测量的重大影响。对于其他三种使用场景,UltraGesture的性能超过90%,而RobuCIR的准确率超过98%,增强的训练数据涵盖了实际场景下手势的不同变化。
跳频的影响。 为了评估跳频方案,我们评估了不同单频信号的RobuCIR。在本实验中,我们根据不同的频率分别训练三个神经网络。为了关注跳频方案的影响,我们保持所有参数不变。图13说明了使用三个单频信号评估的不同使用场景下RobuCIR的识别精度。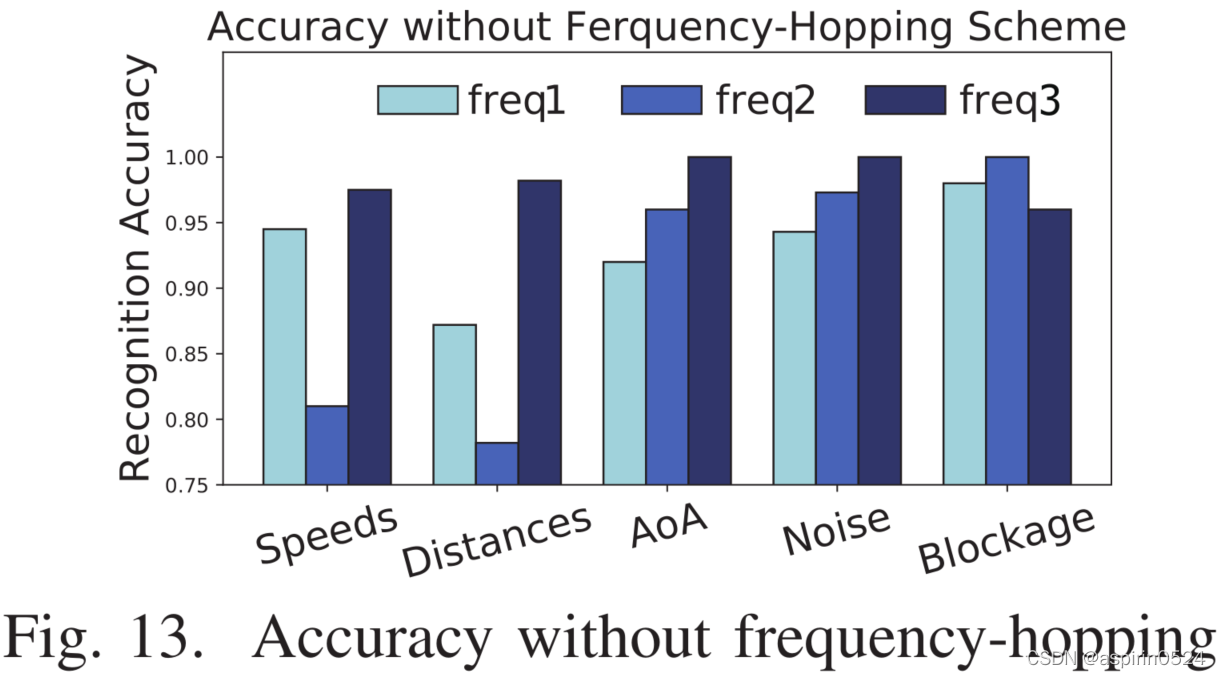
我们观察到,当传输不同的单频信号时,在相同的使用场景下,RobuCIR的性能有所不同。当仅发送频率为2的信号时,在不同速度和到收发器的距离的情况下,性能会显著降低到81%和78.2%,因为当手处于特定位置时,测量信号可能由于反射而相加。因此,提取的CIR测量值无法反映相应手势的模式。相反,当应用跳频方案时,我们可以同时获得来自其他频率的CIR测量值。因此,神经网络可以提取出更有效的特征,增强了系统的鲁棒性。
数据增强的影响。 我们改变数据增强率(即5~100×)并使用不同的增强数据训练分类器。在本实验中,我们使用三个载波频率的跳频方案传输TSC,并且其他参数保持不变。
结果表明,在各种情况下,随着增强率的增大,RobuCIR的识别精度都有所提高。特别是,在不同速度和距离下执行手势时的准确度比其他三种场景的提高更高,因为在这两种场景下应用数据增强,更大的增强率涵盖了手势的更多变化。随着放大率提高到100×,每个场景精确度超过96%。实验结果表明,数据增强技术确实为神经网络提供了更多的洞察力和高质量的数据,并有助于提高系统的鲁棒性。
执行时间。 我们运行20000次推断并测量平均执行时间。在整个CIR测量处理阶段中,每次需要执行手势和下转换步骤之前都会进行帧检测,这两个步骤分别大约需要1.3ms和2.2ms。我们经过训练的分类器可以在高端服务器上平均23毫秒内处理每个CIR测量。我们目前对RobuCIR的实现主要侧重于增强声学传感性能的鲁棒性。为了减少移动设备端的计算开销,我们将手势识别中涉及的计算密集型任务加载到高端服务器。我们计划在未来的工作中移动设备上运行深度神经网络模型。
V. RELATED WORK
音频信号手势识别:
SoundWave:根据手部反射的音频信号的多普勒频移,通过跟踪手部运动(例如速度、方向和幅度)来检测手势。
AudioGest:通过测量多普勒频移,可以高精度地识别六种手势。
EchoTrack:根据飞行时间(Time-of-Flight)信息识别手势。
FingerIO:测量连续接收的声学信号的互相关变化,以跟踪移动的手。
LLAP:通过提取信号相位信息来实现手指的轨迹跟踪。
Strata:通过测量反射音频信号的CIR来实现更高的精度。
这些工作将手指/手视为单个反射点,实现了高跟踪精度。但是,将整只手建模为单个点无法提供足够的分辨率。
UltraGesture:测量反射音频信号的CIR幅度并识别手势。然而存在频率选择性衰落问题,需要大量的训练数据才能有效地训练神经网络模型。(本文所解决的关键问题)
射频(RF)信号手势识别:
AllSee:使用能量收集传感器识别手势。
Rf-IDraw和RFIPad:可跟踪指纹移动的轨迹,并能够隔空手写。
WiGest:利用WiFi信号强度识别移动设备附近的手势。
WiSee:可以通过提取人体感应的WiFi信号的微小多普勒频移来跟踪不同的家用手势。
WiFinger:可以通过检测通道状态信息(Channel State Information,CSI)中的独特模式来识别手势。
WiDraw:通过处理传入WiFi信号的到达角(Angle-of-Arrival)值,实现隔空手写。
这类工作需要射频设备并支持不同的应用。
基于视觉的手势跟踪:
Microsoft HoloLens:使用专用摄像机提供无接触的人体手势跟踪。
Sony PlayStation VR:要求用户佩戴头盔和控制器,与无接触系统相比,比较麻烦。
DigitEyes:可以从普通灰度图像模拟手的运动。
然而,基于视觉的方法需要良好的光照条件,这限制了其应用。
VI. CONCLUSION
本文提出了一个基于声学的手势识别系统的整体设计和实现,该系统能够识别15种类型的手势,具有较高的鲁棒性和准确性。为了缓解频率选择性衰落,本文采用跳频技术,并仔细设计了:下变频(down-conversion)和解调(demodulation),以避免子帧间干扰。基于在初始实验中观察,本文对原始CIR数据进行数据增强,以合成新的增强数据,用于有效地训练神经网络模型。特别地,增强数据捕获实际场景中的不同变化,例如不同的手势速度、到收发器的距离和信号衰减。实验结果表明,在不同的使用场景下,RobuCIR的总体准确率达到98.4%,大大优于现有的工作。

















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









