






相信很多小伙伴们,基本对 HuggingFace Hub 早已耳熟能详。
简单来说,HuggingFace Hub 是一个集成平台,汇集了海量的预训练模型和数据集。
通过这个平台,用户可以轻松浏览、下载和分享模型和数据集,大大加速了机器学习的研究和应用,因此,HuggingFace Hub 逐渐成为一个机器学习领域不可或缺的开源资源中心。
经常使用 Github 的程序员小伙伴们,可能将其类比成 Github。
但其实对于 HuggingFace 生态来说,远不止 Hub 这么简单。除了 HuggingFace Hub 以外,HuggingFace 还提供了大量的开源库,其中就包括闻名的 Transformers、Datasets、Tokenizers等等,
可以帮助用户快速的执行各种模型任务、训练和微调。而且这些库的底层是支持 PyTorch 和 TensorFlow 的,在此基础上提供了更高级别封装的 API。
因此,对于想要入门 AI 领域的程序员小伙伴们,学习和实战 HuggingFace 工具库,我觉得是个不错的入门方式:
- \1. 由于 AI 领域随着 Chatgpt 的爆火,市面上涌入了各种 AI 的学习书籍和视频,除了一些应用方面的、明显蹭热度的、割韭菜的物料还比较容易排除和分辨之外,剩余的物料依然存在 —— 时效性差、工具不够通用、泛泛而谈、纯纯的 AI 平台打广告、为了追热度把功能吹的惊世骇俗等等问题。(我最近几个月就踩了不少这样的坑)
- \2. 从学习的角度来说,首先从宏观上了解问题和知识域,会比直接进入细节和微观更有利于快速的学习。HuggingFace libs 比 PyTorch/TensorFlow 有着更高级的封装和功能展现,通过它掌握了宏观的概念和知识之后,想要了解更细节的知识,可以再去学习底层的内容。HuggingFace libs 的使用普及率也很高,不用担心学到小众的工具而浪费时间。
- \3. HuggingFace docs 官方基本会保持实时更新,时效性比起市面上的文档、书籍、视频要高上不少。
这篇文章,就用来介绍和演示一下如何使用 HuggingFace Transformers库来完成一个NLP模型的简单微调。微调不是目的,学习和熟悉使用库来学习微调的概念和步骤,才是目的。
下面将要在一个很小的 NLP 预训练模型上进行微调,以实现对外卖评价的文本分类 —— 好评和差评两类。
1. 环境安装
- • 安装好 python,版本>=3.8
- • 安装好 环境/包管理工具,conda 或者 pip。(如果同本人一样比较钟爱 pipenv,可以在安装好 pip 后,执行
pip install pipenv,然后使用pipenv来替代pip使用即可。) - • 用管理工具安装依赖库:
pipenv/pip install transformers datasets evaluate accelerate torch scikit-learn pandas jupyterlab。
前4个就是 HuggingFace libs,剩下的针对不同的运行环境可以酌情安装,比如使用了Google colab,就不需要安装 jupyterlab。 - 详细代码已经上传到 github https://github.com/ellendan000/hugging-face-demo/tree/main/00-transformers。
2. 确认模型任务的原有行为
2.1 想要调用模型,使用 HuggingFace Pipeline 来做非常简单

- •
text-classification是任务名,即完成文本分类任务。 - •
hfl/rbt3是预训练好的模型名。pipeline 会从远程 huggingFace Hub 上下载开源的预训练模型到本地缓存。(记得开VPN,或者设置国内镜像库)
也可以事先将模型库clone或者download到本地,然后将这里的hfl/rbt3改为./your-path-to-model - •
pipe(sen)直接传参调用,即执行任务。
output:
[{‘label’: ‘LABEL_1’, ‘score’: 0.7034752368927002}]
- • 这里的 label 与我们的业务可能毫无关系 —— 不是外卖评价的好评和差评。
2.2 明确模型的原有行为和状态
使用如上方式,想要让模型进行二分类,并映射成”好评“和”差评“。
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3", num_labels=2)
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")
model.config.id2label = {0: "差评!", 1: "好评!"}
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer)
sen = "饭菜有些咸!"
pipe(sen)
- •
model分别加载模型,并且传入分类的数量num_labels - •
tokenizer加载分词器,由于 pipeline 要求在传入 model 对象时,必须同时传入 tokenizer,因此这里也另外单独加载了分词器。好在模型训练好的同时,对照的 tokenizer 基本都是确定的,直接从相同的 Hub 路径上加载即可。tokenizer虽然会被翻译为分词器,但是其功能不仅仅是进行分词,它还包含了词典、序列映射、数据截断填充等一系列数据预处理功能。
output:
[{‘label’: ‘好评!’, ‘score’: 0.5472492575645447}]
明显这个结果差强人意。那么,下面就进入微调环节。
3. 模型微调
3.1 准备环境,导入相关包
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
- • 事先已经安装好依赖库的话,这里只要导入相关包即可。
3.2 准备数据
随着模型训练和微调的库越来越多,代码其实都已经模式化,甚至已经出现直接使用 WebUI 界面进行模型训练和微调(比如 LLaMA-Factory), 因此对于追求训练和微调为目的来说,最重要的其实就是两块 —— 数据集和显卡。
这里我们使用 github 上的一个中文外卖评价数据集,直接把它下载下来,保存到项目本地。
加载数据集
dataset = load_dataset("csv", data_files="./waimai_10k.csv", split="train")
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset
output:
Dataset({ features: [‘label’, ‘review’], num_rows: 11987 })
- • 这个csv文件,包含了正向 4000 条,负向 约 8000 条。正向好评 label 为 1,负向差评 label 为 0。features 包括 label 和 review。
- •
split="train"由于只有一个csv文件,没有进行 train 和 test 数据集的拆分,load_dataset 会默认将所有数据都算入 train 数据集。为了有利于后面手动进行数据集拆分,这里强调加载默认的 train 数据集。 - •
dataset.filter将无文本的 review 记录过滤掉。
使用 tokenizer 进行数据预处理
import torch
tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3")
def process_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
tokenized_examples["labels"] = examples["label"] return
tokenized_examples
tokenized_dataset = dataset.map(process_function, batched=True, remove_columns=dataset.column_names)
tokenized_dataset
output:
Dataset({ features: [‘input_ids’, ‘token_type_ids’, ‘attention_mask’, ‘labels’], num_rows: 11987 })
- •
dataset.map将原数据集的每条数据进行处理,小批量地执行 map functionprocess_function,并且remove_columns返回的结果集删除掉未加工的原始数据列。 - •
tokenizer将每条数据超出最大长度128的数据进行截断。
分割数据集
tokenized_datasets = tokenized_dataset.train_test_split(test_size=0.1)
tokenized_datasets
output:
DatasetDict({ train: Dataset({ features: [‘input_ids’, ‘token_type_ids’, ‘attention_mask’, ‘labels’], num_rows: 10788 }) test: Dataset({ features: [‘input_ids’, ‘token_type_ids’, ‘attention_mask’, ‘labels’], num_rows: 1199 }) })
- • 将数据集中的 10% 作为测试数据集,即 90% 为训练数据集。返回结果为 DatasetDict 包含 train 和 test。
3.3 加载预训练模型

加载预训练模型非常简单,HuggingFace 也不需要像 PyTorch 那样显性的将模型和参数传给GPU,底层已经帮助实现。因此,上面注释中的 torch 部分代码完全可以删掉。
但如果编写 PyTorch 代码的话,还是必须加上。
如果跟我一样,使用的是 MacOS 的话、并且是 M1 芯片之后的版本,在写 PyTorch 代码时,需要把模型和参数传给mps。
因为 PyTorch 在 M1 之后使用 mps 进行了加速,虽然比起 GPU 速度上还是有不小差距,但是比起直接使用 CPU 来说,还是快上不少。
如果是 M1 之前的 Mac 的话,就不要勉强了,直接去使用 Google colab 或者 白嫖下阿里云PAI平台的免费限额,不然速度会慢到落泪。
3.4 训练和评估
定义评估函数

evaluate 库已经提供了大量评估函数的实现。这里使用了最简单的准确率acc和F1分值。在二分类中,样本预测结果分为4类:
- • TP (True Positive):真*正例,即实际为正类,”正确“预测为正类的样本数。
- • TN (True Negative):真*负例,即实际为负类,”正确“预测为负类的样本数。
- • FP (False Positive):假*正例,即实际为负类,”错误“预测为正类的样本数。
- • FN (False Negative):假*负例,即实际为正类,”错误“预测为负类的样本数。
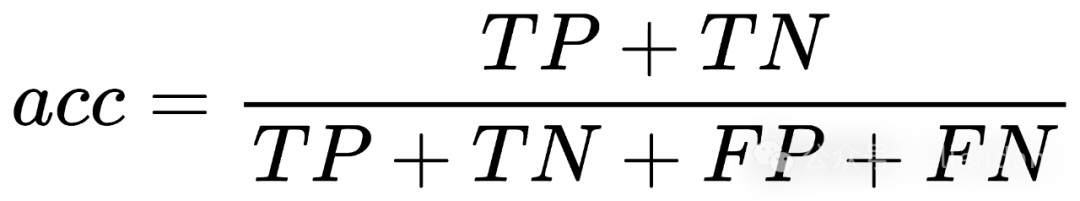 , acc被称为准确率。
, acc被称为准确率。
了解F1分值前需要了解 精确率 Precision(也叫查准率) 和 召回率 Recall(也叫查全率)。
- • Precision:在所有被预测为正类的样本中,实际的确是正类的比例。
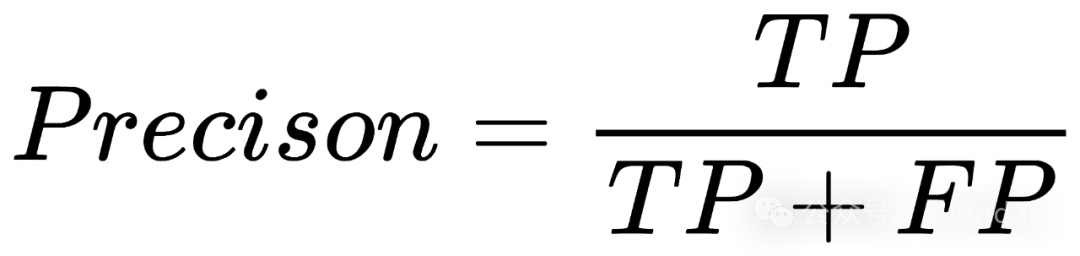
- •
Recall:在所有正类的数据集范围内,被成功预测正确的比例。 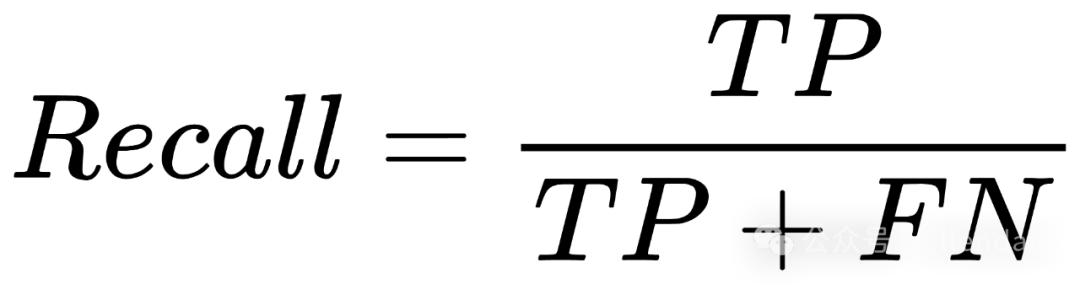
- •
F1:是 Presion 和 Recall 的调和平均值,旨在提供一个综合评价指标,特别是针对类别不平衡的数据集。F1分值在0到1之间,值越接近1表示模型的性能越好,既考虑了模型预测的准确性(Precision),也考虑了模型识别出所有正例的能力(Recall)。 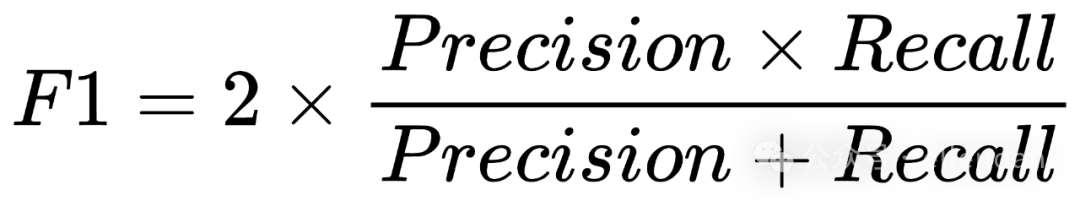
定义训练参数

- • HuggingFace 库对训练的实现细节已经进行了封装,只需要传参即可控制过程。当然这些参数背后代表的过程控制,需要了解一部分模型训练的知识和细节。
- •
batch与step相关,比如这里训练数据集全量是1w多条,per_device_train_batch_size设置为64,step即 1w / 64 约为 156,也就是训练数据集跑一次全量需要 156 step - •
logging_steps=10每10个step打印一下进度 - •
eval_strategy="epoch"每个epoch(也就是跑一次全量)进行一次评估 - •
save_strategy="epoch"每个epoch进行一次磁盘保存 - •
learning_rate和weight_decay深度学习训练模型的超参数设置 - • 以
metric_for_best_model为标准,加载最优模型load_best_model_at_end
执行训练
trainer.train()
output:

- • 在训练的过程中,会按照之前的参数设置
logging_steps、eval_strategy来打印进度反馈。
评估
trainer.evaluate()
Output:
{‘eval_loss’: 0.23134386539459229, ‘eval_accuracy’: 0.9182652210175146, ‘eval_f1’: 0.8759493670886076, ‘eval_runtime’: 2.2119, ‘eval_samples_per_second’: 542.056, ‘eval_steps_per_second’: 4.521, ‘epoch’: 3.0}
- • 这里默认使用参数设置的
eval_dataset进行评估。 - • 想要重新针对训练集进行评估需要调用
trainer.evaluate(tokenized_datasets["train"])
3.5 模型预测

Output:
[{‘label’: ‘差评!’, ‘score’: 0.9463842511177063}]
- • 明显比微调之前的预训练模型要靠谱许多。
3.6 微调模型保存
保存到本地

Output:
(‘./my-awesome-model/tokenizer_config.json’, ‘./my-awesome-model/special_tokens_map.json’, ‘./my-awesome-model/vocab.txt’, ‘./my-awesome-model/added_tokens.json’, ‘./my-awesome-model/tokenizer.json’)
从本地加载模型和预测

附
本文仅使用了普通微调训练的方式,会对参数进行全量调整。
如果涉及到参数千万以上的大模型,这种方式并不适合 —— 需要使用 HuggingFace 的PEFT库,针对小部分参数进行微调的同时获得更好的模型预测效果。
即使这样,也并非普通的显卡就可进行训练,作者本人曾经试过在 Google Colab 上15G显存 仅加载 Llama3 模型 —— 根本加载不进去,直接 OutOfMemory。论数据集和显卡的重要性。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









