







【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
一、Occupancy 要点速览
(下文以Occ代替Occupancy)
- 什么是Occ:3D占用,即用体素网格表示三维场景。(像素:长×宽;体素:长×宽×高)
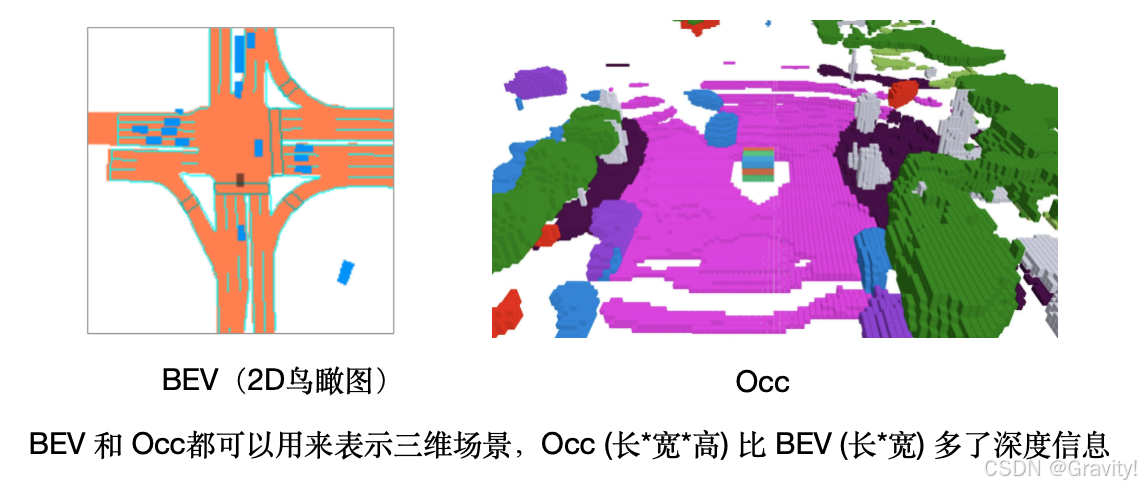
- Occ 包含什么信息:1. 占用情况(是否有物体) 2. 语义信息(哪类物体)
- 为什么要 Occ:
- 能密集表示3D场景(对比稀疏的点云)
- 有深度信息(对比BEV)
- 解耦语义和几何(可以分开预测是否有物体和物体类别,有时候只需要知道是否有物体)
- Occ是怎么来的:
- 真值 (ground truth) 怎么来的(以Occ3D为例):
- 关建帧:多帧激光雷达点云【来源】 → 聚合多帧点云(单帧太稀疏,多帧能补充更多的物体信息) → 推理遮挡的部分 → 用图像修正Occ
- 非关建帧: 由关键帧通过KNN分配标签 - 通过图片预测(算法要做的任务,也是下面方法的目标)
- 真值 (ground truth) 怎么来的(以Occ3D为例):
二、重要论文解析
2.1: MonoScene: Monocular 3D Semantic Scene Completion [CVPR 2022]
- 任务:单目3D语义场景补全【单张2D前视图 → 3D场景的重建】(类似于Occ预测任务)
- Pipeline:
- 单帧前视图输入 → 2D UNet【提取图像特征】 → FLoSP【2D到3D特征转化】 → 3D Unet【学习空间关系】 → 任务头输出结果
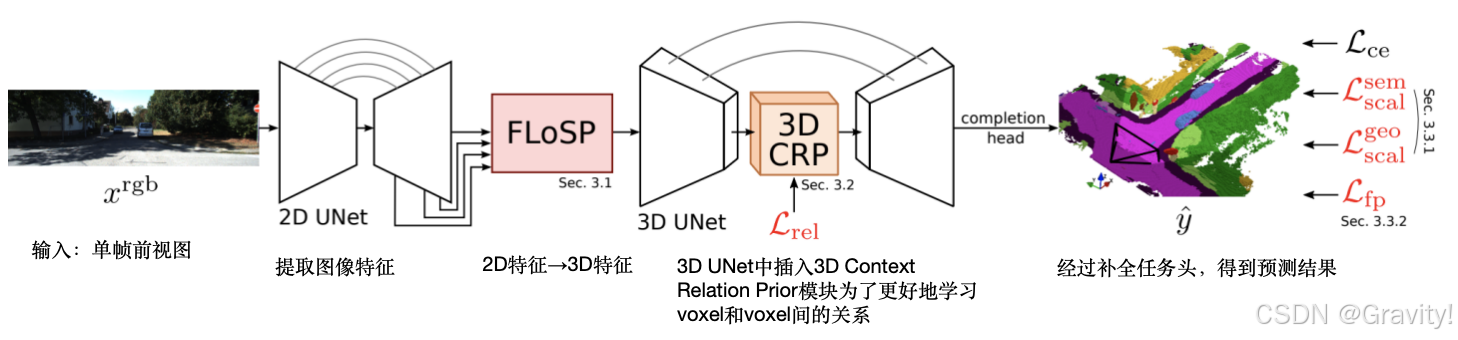
- 核心:Features Line of Sight Projection (FLoSP) 模块
- 实现 2D特征 → 3D特征转换

- 损失函数:
- Scene-Class Affinity Loss: 分类结果的loss,优化每个类的(P)recision, (R)ecall【衡量每个类别能否分正确】和 (S)pecificity【能否区别不同类】
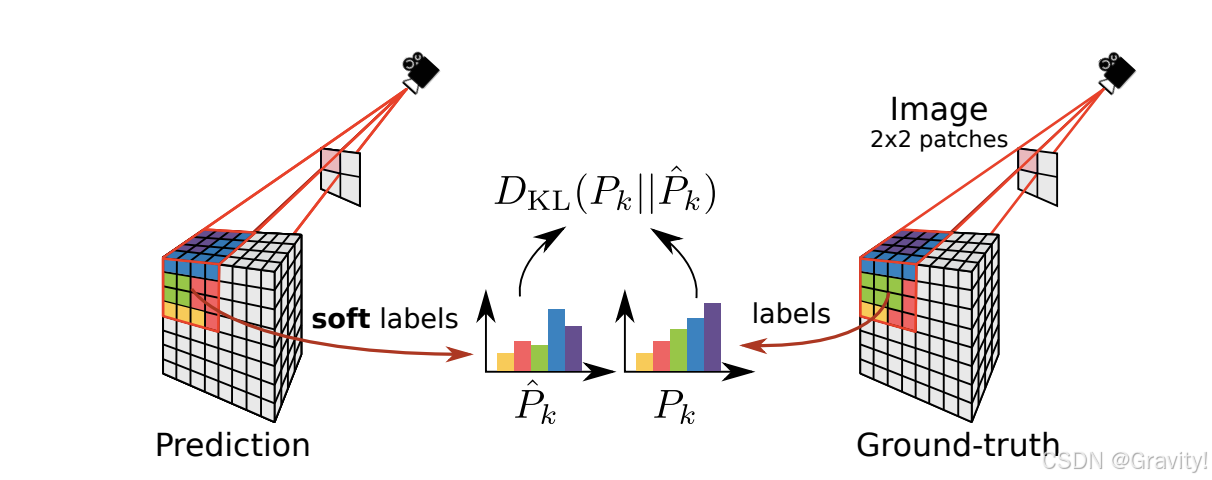
- Frustum Proportion Loss:按相机视角划分锥体,计算每个锥体的预测结果和GT的KL散度【提升被遮挡物体预测结果的正确率(个人理解:锥体前小后大,后面是被遮挡的voxel,所以被遮挡voxel被计算的次数会比较多)】
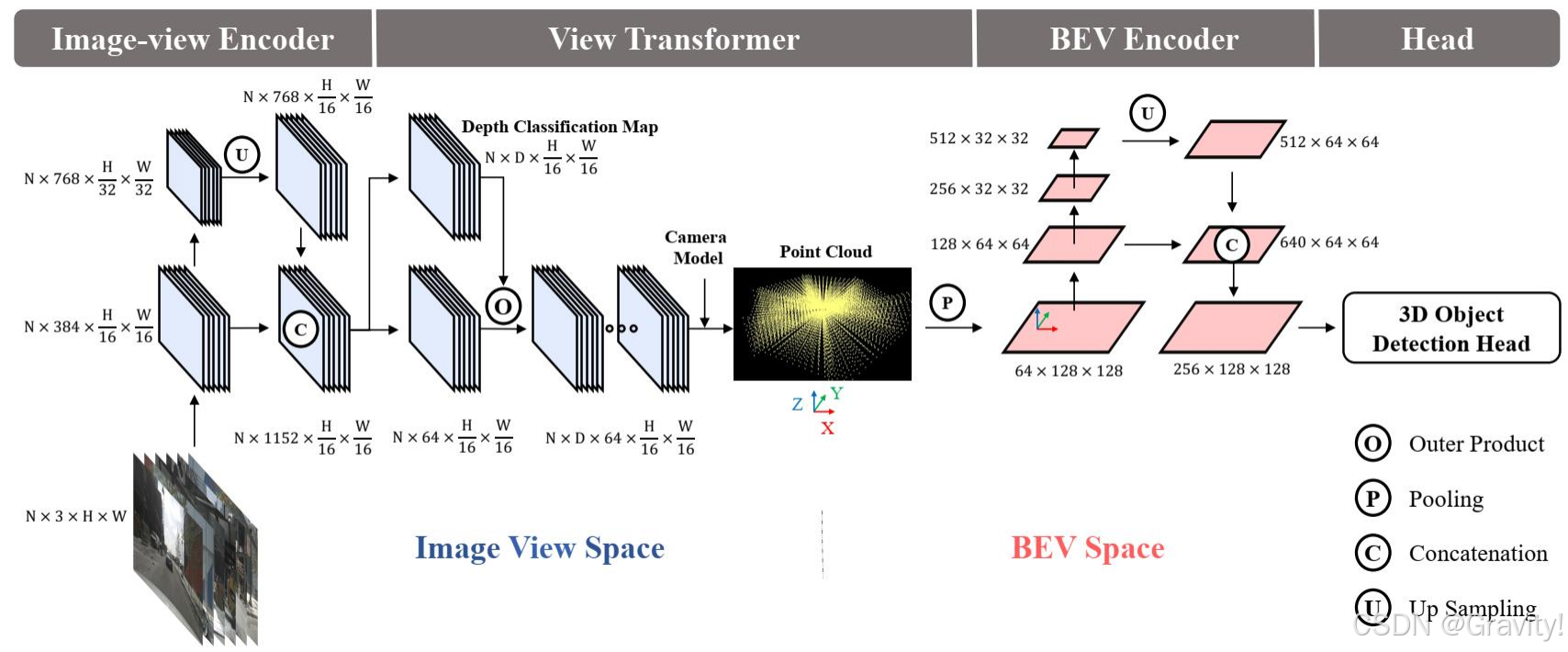
2.2 BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
- BEVDet 做的是主要是做BEV检测,接上Occ任务头也可以做Occ预测(这里简略介绍该方法,之后可能会单独写一个BEV笔记)
- Pipeline:
- 多视图输入(环视图) → 2D Encoder & FPN【提取图像特征,多尺度特征融合】 → 视角转换【2D到3D 特征映射】→ BEV Encoder【得到BEV特征】 → Occ Head【得到Occ输出】
2.3 BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers [CVPR 2022]
- BEVFormer也是做BEV检测的工作,可接上Occ任务头做Occ预测 (这里不详细展开BEV部分)
- Pipeline:
- 环视图输入 → 2D Encoder & FPN【提取图像特征,多尺度特征融合】
→ Transformer【BEV特征编码】:
1. 时序自注意力【用历史帧BEV特征增强当前帧BEV特征】
2. 空间交叉注意力【采样图像特征,获取图像信息】
→ Occ任务头【得到Occ输出】 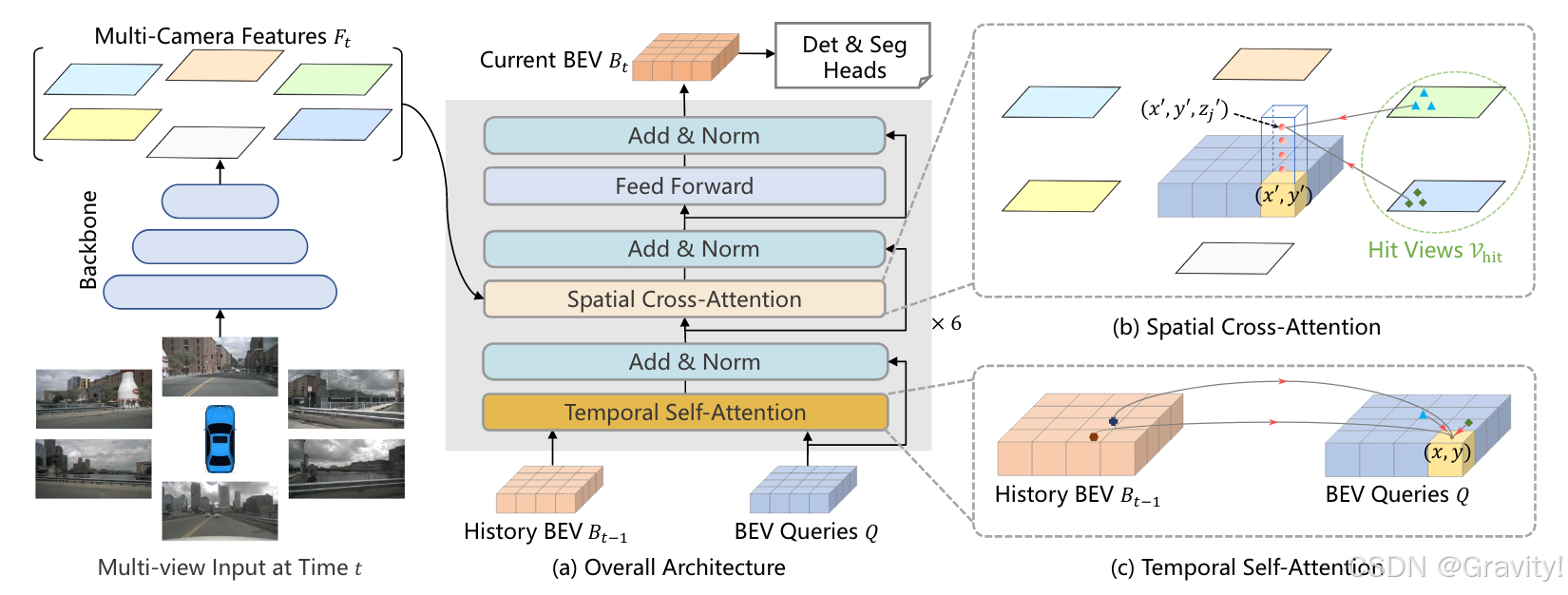
- 环视图输入 → 2D Encoder & FPN【提取图像特征,多尺度特征融合】
2.4 TPVFormer:Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction [CVPR 2023]
- 任务:Occ 语义占用预测
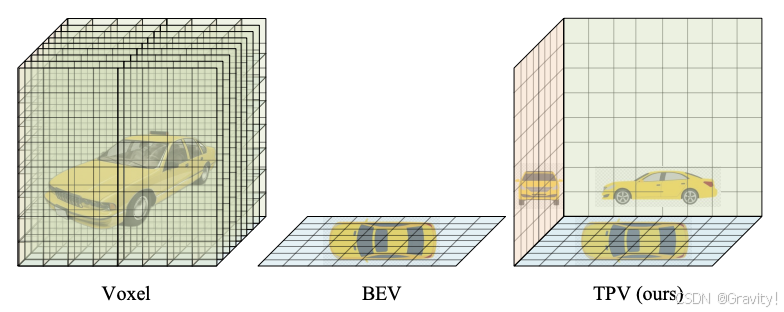
- 优化点:更高效的3D空间表征
- Voxel 的计算量太大,BEV缺高度信息,TPV用三个面来表示3D空间,计算量小且有高度信息
- Pipeline:
- 环视图输入 → 2D Encoder & FPN【提取图像特征,多尺度特征融合,得Feature Maps】→ TPVFormer【重建3D空间,得TPV表征】 → Occ任务头【得Occ预测结果】
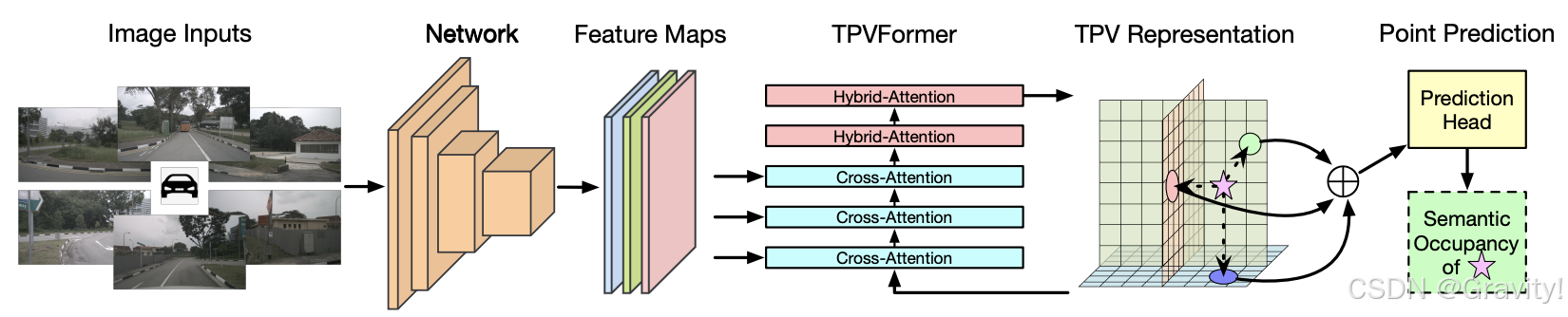
- 重点内容:
- 如何表示空间中任意一个点的特征:

- 为什么可以节省存储和计算:
- 按照上面的方法构建出体素空间 (H×W×D),复杂度为O(H*W + W*D + H*D)
- TPVFormer 中 Attention 的设计(类似BEVFomer):
- Image Cross-Attention【多视角2D图像特征 → 3D TPV特征】
- Query:三个平面上的点(初始化的可学习参数)
- Key:投影回平面上的参考点
- Value:图像特征

- Cross-View Hybrid-Attention 【实现三个平面之间信息交换】
- Image Cross-Attention【多视角2D图像特征 → 3D TPV特征】
- 如何表示空间中任意一个点的特征:

(未完待续 ……)

















 4437
4437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









