




文章目录

引言:为什么你的 AI Agent 活不过 Demo 阶段?
在今天,构建一个让人眼前一亮的 LLM Demo 变得前所未有的简单。借助 LangChain 或 LlamaIndex,短短几十行代码,我们就能让模型起草一封完美的邮件,通过自然语言查询 SQL 数据库,甚至规划一次复杂的旅行。
然而,当我们将这个 Demo 部署到生产环境,面对真实世界的混乱数据时,光环往往瞬间破碎。
- 当用户不再按照预设的脚本提问,而是基于昨天的 Slack 碎片化讨论进行追问时;
- 当所有的内部文档、事故报告和过时的 API 文档一股脑塞进模型时;
- 当对话轮次超过 10 轮,模型开始遗忘之前的约束条件时。
模型开始“犯糊涂”了。 它并非变笨了,而是迷失了。
Demo 和生产系统之间最大的鸿沟,不在于你是否使用了 GPT-4 还是 Claude 3.5 Sonnet,而在于信息如何在任务的每一步被选择、结构化和传递给模型。
这不是 Prompt Engineering(提示工程)能解决的问题,这是 Context Engineering(上下文工程) 的战场。
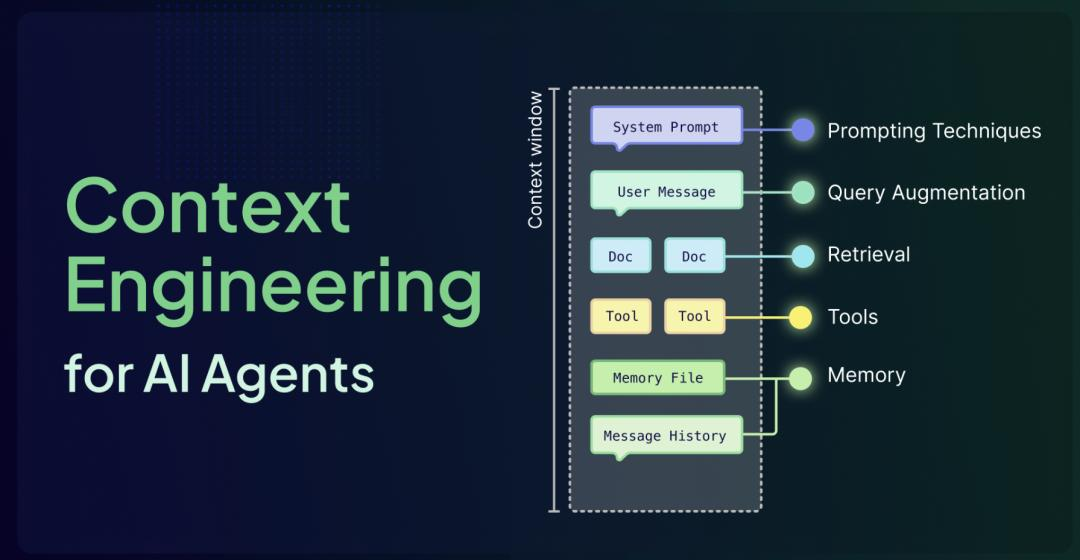
本文将深入剖析上下文工程的核心逻辑,揭示构建生产级 AI Agent 的六大支柱,并探讨行业最新的标准化趋势。
第一部分:理解核心约束——上下文窗口的本质
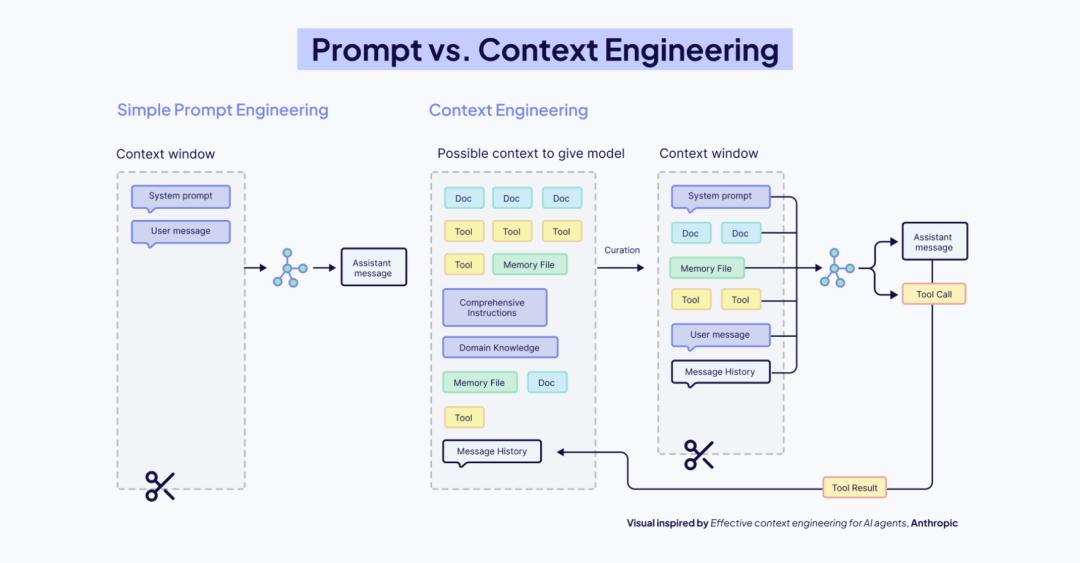
要解决问题,首先要理解物理约束。对于 LLM 而言,上下文窗口(Context Window) 不仅仅是内存(RAM),它是模型的“认知带宽”。
1.1 上下文即“白板”
想象一下,模型面前有一块白板。这块白板的大小是有限的(例如 128k token)。
- 用户的每一句话、模型的每一次思考、从向量库检索到的每一段文档、工具调用的每一个 JSON 返回值,都必须写在这块白板上。
- 一旦白板写满,为了写入新信息,必须擦除旧信息。
- 最致命的是:模型在推理时,必须“同时看到”白板上的内容才能建立联系。如果关键信息被擦除,或者被淹没在无关的涂鸦中,推理链就会断裂。
1.2 为什么“超大上下文”不是银弹?
很多开发者认为:“我只要用支持 1M Token 上下文的模型不就好了吗?”
大错特错。 随着上下文长度的增加,模型的**注意力机制(Attention Mechanism)**会被稀释。这会导致著名的 “Lost-in-the-Middle”(中段迷失) 现象:模型能很好地捕捉开头和结尾的信息,但往往会忽略中间的大段内容。
单纯增加窗口大小,而不进行工程化治理,只会带来更高的延迟、更昂贵的 Token 成本,以及更不可控的幻觉。
第二部分:提示工程 vs. 上下文工程
这是两个常被混淆,但维度完全不同的概念。
2.1 提示工程(Prompt Engineering):战术层面的微操
提示工程关注的是 “怎么问(How)”。
- CoT (Chain of Thought):让模型一步步思考。
- Few-Shot:给几个示例。
- Role Playing:你是一个资深工程师。
它的局限性在于:如果模型根本没有获取到正确的信息,再精妙的提示词也无法产生正确的结果。巧妇难为无米之炊。
2.2 上下文工程(Context Engineering):战略层面的架构
上下文工程关注的是 “给什么(What & When)”。
它是设计架构的学科,旨在正确的时间向 LLM 提供正确的信息。它关乎构建连接断连模型与外部世界的桥梁——检索外部数据、使用工具、赋予记忆,使其响应基于事实而非仅依赖训练数据。
核心定义:提示工程是你如何提问,而上下文工程是确保模型在开始考试之前,手边已经摆好了正确的教科书、计算器,以及之前复习的笔记。
第三部分:上下文的四大崩塌模式
在生产环境中,如果我们缺乏良好的上下文管理,通常会遇到以下四种典型的失败模式:
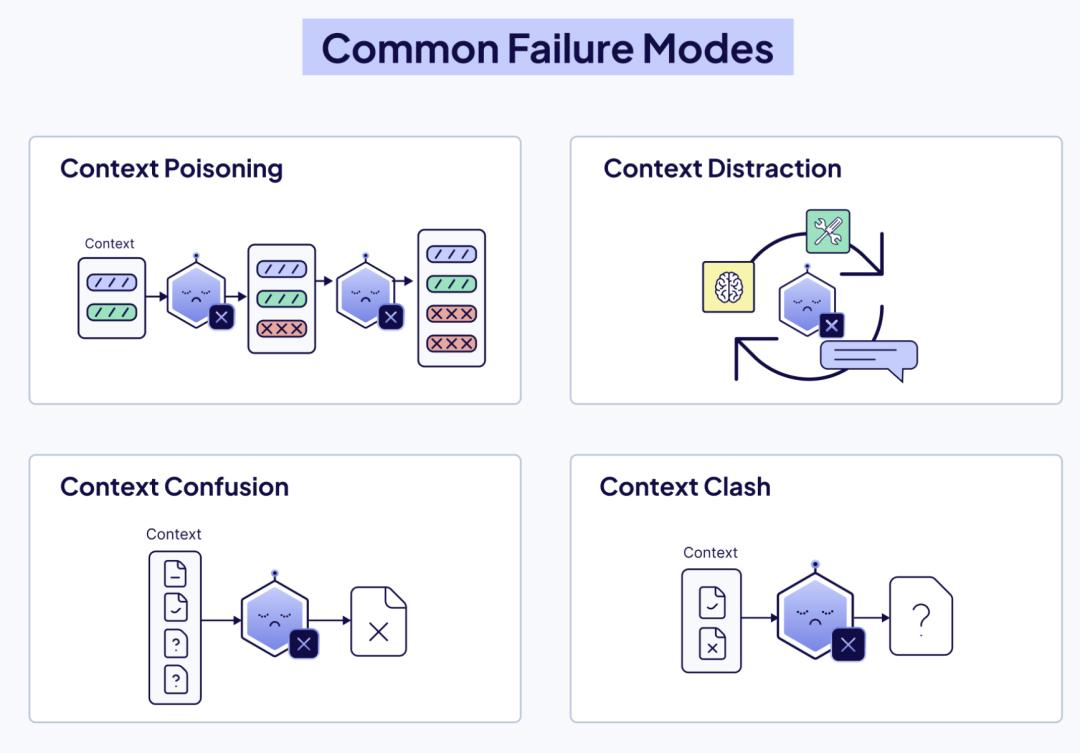
3.1 上下文污染 (Context Poisoning)
现象:检索系统召回了错误的、过时的或带有偏见的文档。
后果:由于 LLM 倾向于信任上下文中的信息(In-Context Preference),它会基于这些错误信息构建看似逻辑严密但事实错误的回答。这种错误会在多轮对话中累积,导致 Agent 彻底偏离轨道。
3.2 上下文分散 (Context Distraction)
现象:为了“保险起见”,我们将所有历史记录、冗长的 API 完整定义、无关的寒暄都塞进 Prompt。
后果:信噪比(Signal-to-Noise Ratio)急剧下降。模型被无关信息干扰,开始重复过去的行为模式,而不是针对当前的新问题进行独立推理。
3.3 上下文混淆 (Context Confusion)
现象:同时提供了多个功能相似的工具,或者多个结构相似但内容冲突的文档。
后果:模型注意力分散,不知道该信哪个,或者在工具选择时出现犹豫和错误调用。
3.4 上下文冲突 (Context Clash)
现象:用户的指令(System Prompt)要求“简短回答”,但检索到的 Few-Shot 示例全是长篇大论。或者检索到的两份文档对同一事实描述矛盾。
后果:模型陷入逻辑死循环,或者产生精神分裂式的回答(既承认A又承认B)。
第四部分:上下文工程的六大支柱(核心实战)
要构建一个鲁棒的 Agent 系统,我们需要围绕以下六个支柱进行工程化设计。这不仅仅是代码模块,更是控制信息流动的阀门。
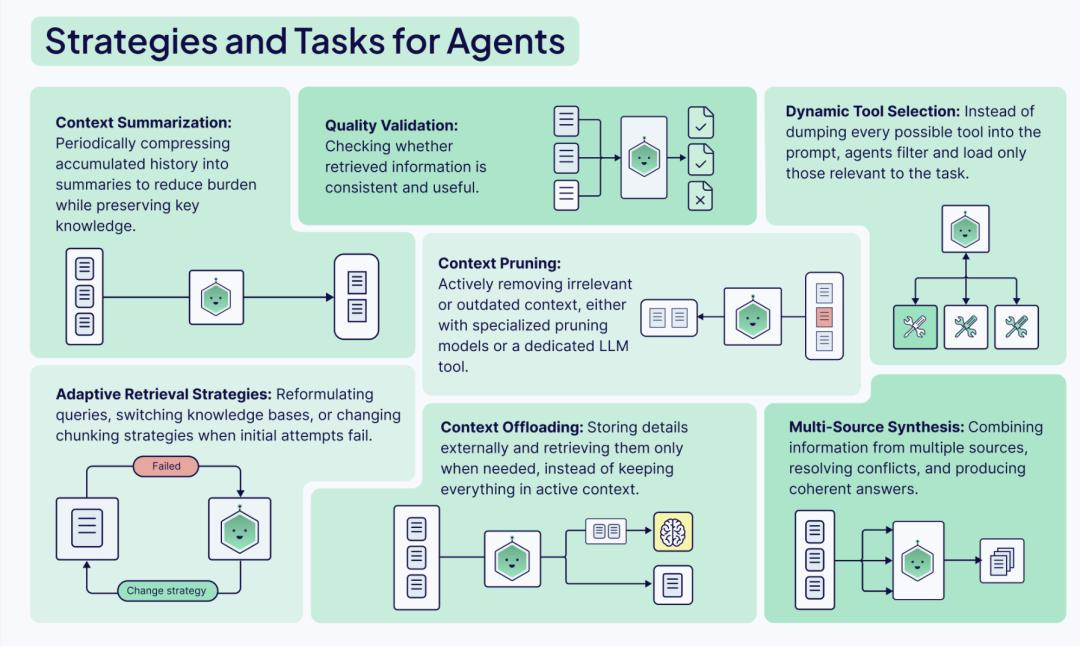
Pillar 1: Agent(编排中枢)
Agent 是上下文的架构师。
- 单 Agent 模式:适用于线性任务。Agent 自己决定何时读取记忆、何时调用工具。
- 多 Agent 模式(Swarm/Hierarchical):
- Router Agent:负责分发任务,它不需要知道具体细节,只需要极简的上下文。
- Worker Agent:负责具体执行(如写代码),它需要详细的技术文档上下文,但不需要知道用户的原始情绪发泄。
- 架构启示:通过拆分 Agent,我们可以将巨大的上下文拆解为多个小的、高浓度的上下文窗口,每个 Agent 只处理它需要的信息。
Pillar 2: 查询增强 (Query Augmentation)
用户的原始输入通常是糟糕的:“那个报错怎么修?”
如果我们直接拿这句话去检索向量库,结果将是灾难性的。我们需要翻译层:
- 指代消解:将“那个报错”还原为“OrderService 中的 NullPointerException”。
- 查询扩展:生成多个视角的查询。例如针对技术问题,同时生成“错误日志分析”和“代码修复建议”两个查询向量。
- HyDE (Hypothetical Document Embeddings):让 LLM 先生成一个假设性的完美答案,然后用这个假设答案去检索相似文档。这通常比直接用问题检索效果好得多。
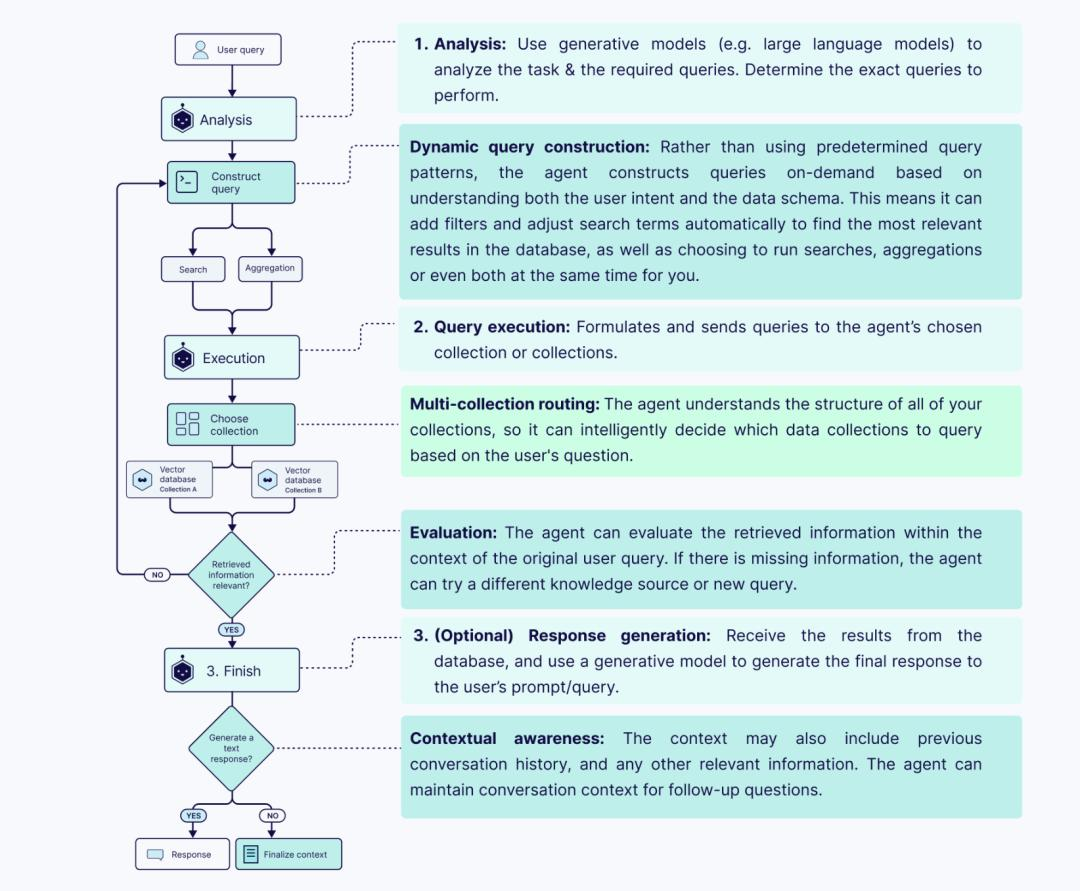
Pillar 3: 检索 (Retrieval) —— RAG 的灵魂
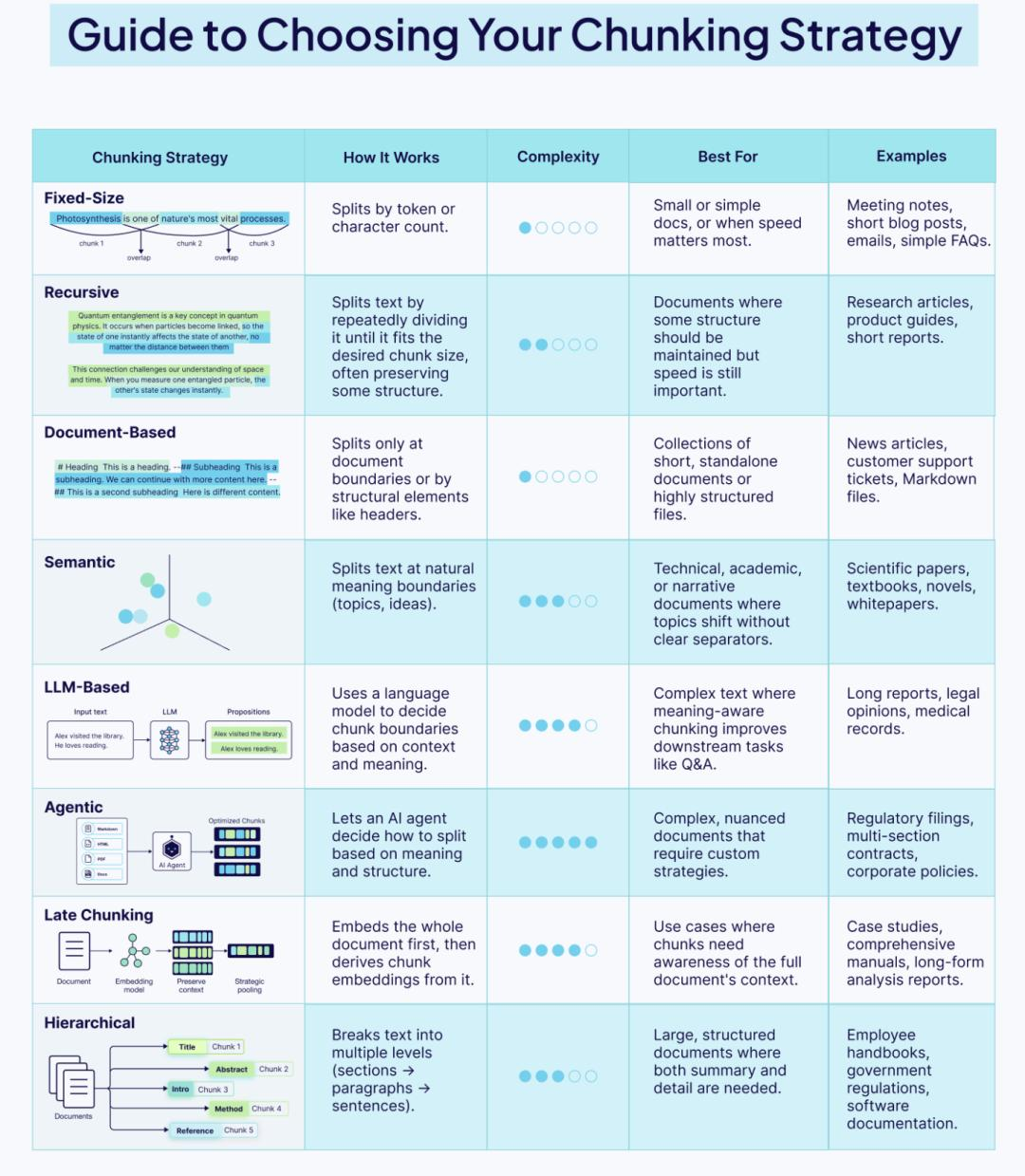
检索质量决定了 Agent 的智商上限。这里的核心是分块策略(Chunking Strategy)。
- 小分块 (Small Chunks):
- 优势:检索精准,向量相似度高。
- 劣势:缺乏语义环境,模型看了不知道前因后果。
- 大分块 (Large Chunks):
- 优势:上下文丰富。
- 劣势:包含大量噪音,向量稀释。
生产级解决方案:父文档检索 (Parent Document Retrieval)
我们对文档进行“小切分”来做索引(用于精准匹配),但在检索命中后,返回其所属的“大父块”甚至全文给 LLM。这样既保证了检索的精准度,又保证了提供给模型的上下文完整性。
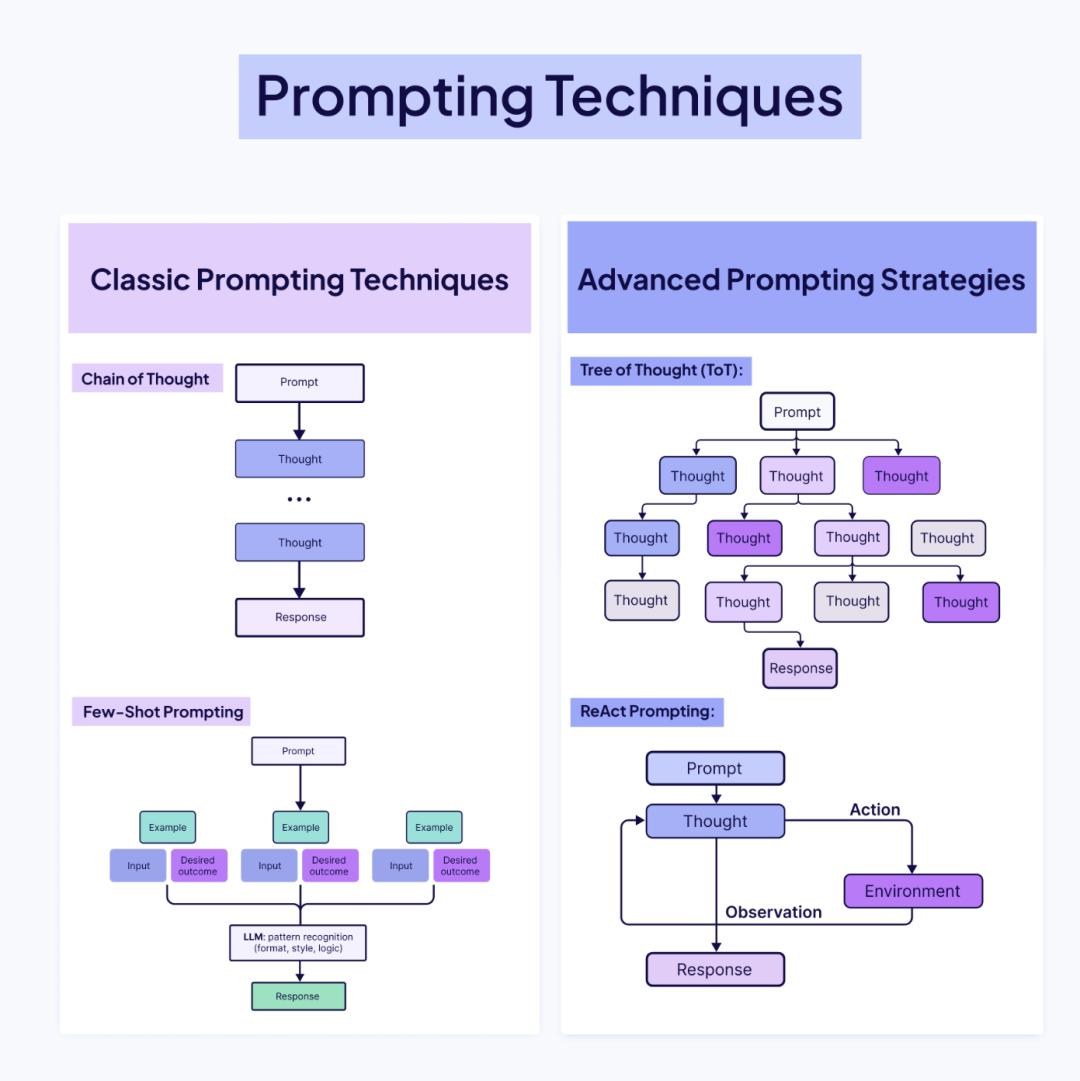
Pillar 4: 提示技术 (Prompting) —— 引导推理
在上下文工程中,Prompt 的作用是元指令(Meta-Instructions)。
我们需要明确告诉模型如何处理检索到的信息:
- 引用溯源:“请仅基于
<context>标签内的内容回答,并在句尾标注引用 ID。” - 冲突解决:“如果来源 A 和来源 B 冲突,请以日期较新的来源 B 为准。”
- 思维链引导:“在回答前,先列出你需要用到的信息关键点。”
Pillar 5: 记忆 (Memory) —— 从无状态到有状态
这是 Agent 区别于 Chatbot 的关键。记忆不仅仅是保存聊天记录。
记忆的三层架构:
- 短期记忆 (Short-term Memory):
- 即当前的上下文窗口。包含最近 K 轮对话、最新的工具输出。
- 策略:滑动窗口(Sliding Window)或 Token 缓冲池。
- 工作记忆 (Working Memory):
- 用于多步骤复杂任务的“草稿纸”。
- 例如:Agent 正在写代码,它需要记住“当前修改的是 User 类”,这个信息在任务结束前必须一直置顶,不能被滑动窗口挤出去。
- 长期记忆 (Long-term Memory):
- 存储在外部(向量数据库/图数据库)。
- 情景记忆:用户过去的偏好、历史交互摘要。
- 语义记忆:领域知识库。
- 程序记忆:成功的 SOP(标准作业程序)或代码片段。
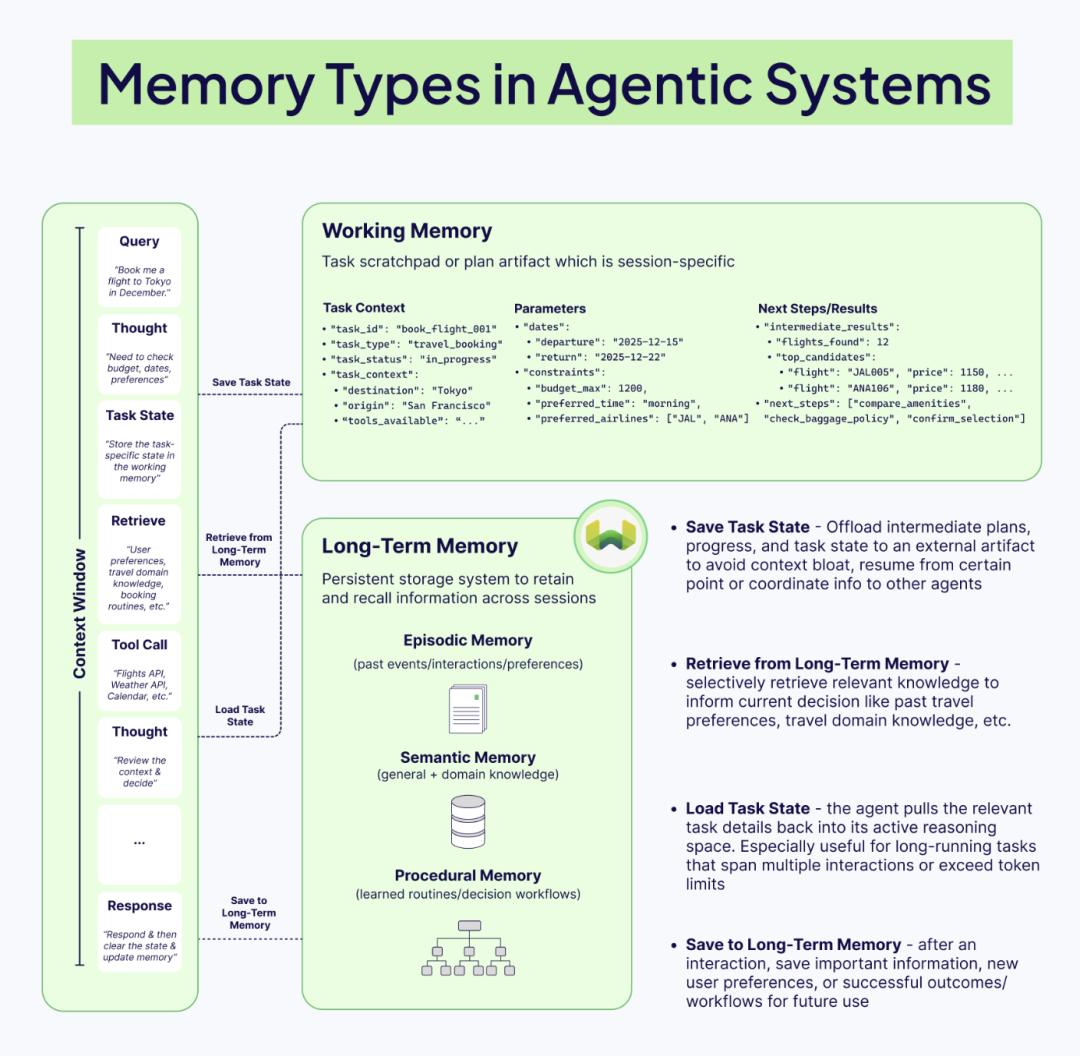
关键技术:记忆修剪 (Memory Pruning)
不要忠实地记录一切。Agent 需要一个后台进程(Summary Agent),定期将短期对话总结为摘要存入长期记忆,并从当前窗口中删除原始对话。
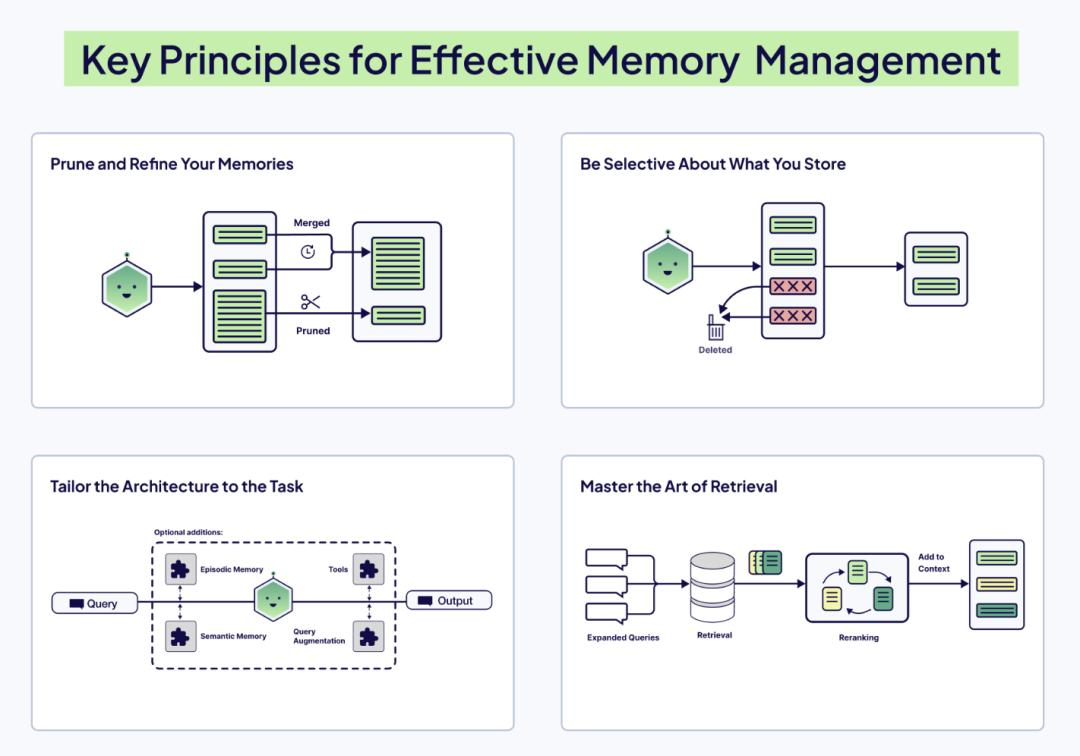
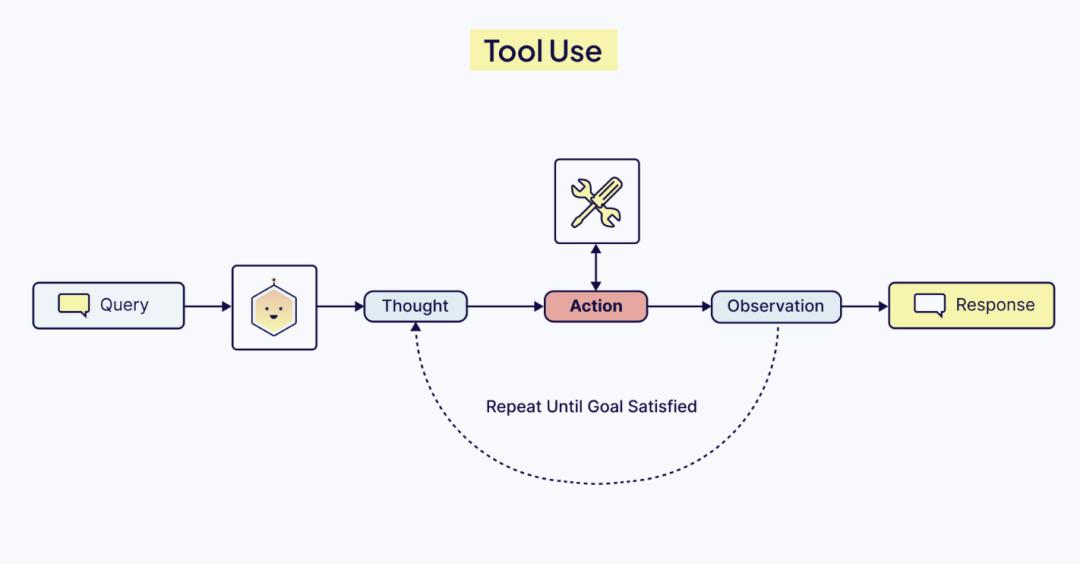
Pillar 6: 工具 (Tools) —— 感知与行动
工具是 Agent 的手脚。但在上下文工程中,工具定义的Schema至关重要。
- 工具描述:如果你的工具描述模糊(例如“搜索数据”),模型会滥用它。必须精确(例如“通过用户 ID 搜索最近 30 天的订单 SQL”)。
- 参数构造:模型往往不擅长猜测参数。我们需要在上下文中提供参数的 Schema 定义(如 Pydantic 模型)和 Few-Shot 示例,教模型如何正确填参。
- 错误处理:当工具报错时,错误信息本身也是宝贵的上下文。不要只返回 “Error”,而要返回 “Error: Connection Timeout, please retry”,这能触发 Agent 的自我修正机制。
第五部分:走向标准化——模型上下文协议 (MCP)
随着 Agent 生态的爆发,连接工具和数据源变得越来越痛苦。每个 Agent 框架(LangChain, AutoGen, Semantic Kernel)都有自己的工具定义标准。
M × N 的集成噩梦:M 个 AI 应用需要连接 N 个数据源(Slack, Google Drive, Postgres…),这意味着需要写 M×N 个适配器。
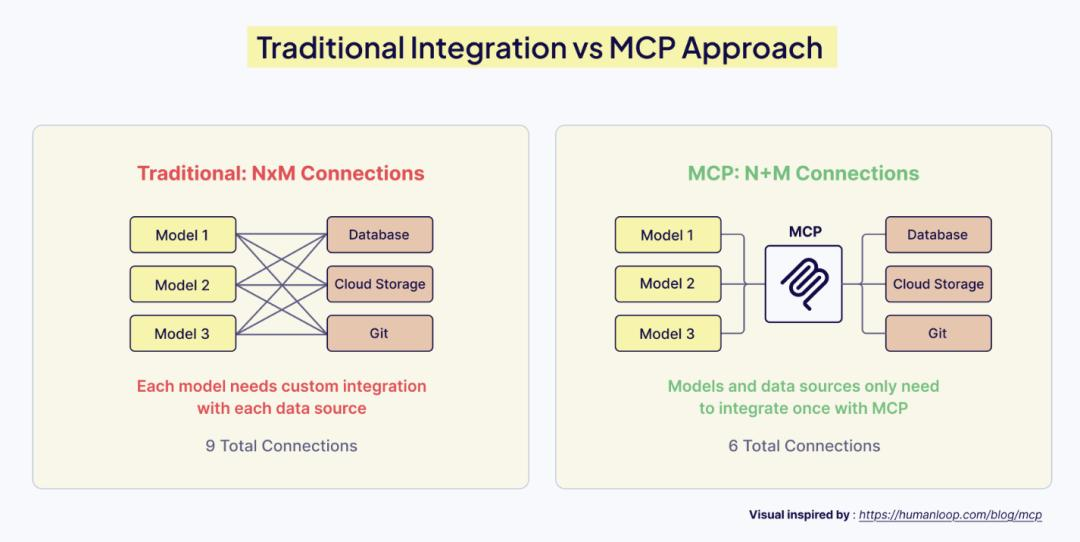
MCP (Model Context Protocol) 的出现
Anthropic 在 2024 年底提出的 MCP 试图解决这个问题。它被称为 AI 时代的 “USB-C”。
- 原理:MCP 定义了一个通用标准,任何数据源只要实现 MCP Server 接口,就可以被任何支持 MCP Client 的 AI 应用(如 Claude Desktop, IDEs)直接使用。
- 改变:集成问题变成了 M + N。你只需要为你的内部数据库写一次 MCP Server,团队里的所有 Agent 都可以立即获得访问权限,无需重新写 Python 代码来包装 Tool。
- 上下文的标准化:MCP 不仅标准化了工具调用,还标准化了资源的读取(Resources)和提示词模板(Prompts)。这意味着“上下文”本身变成了一种可移植的资产。
第六部分:实战建议——从 MVP 到 Production
如果你正在构建 AI Agent,请遵循以下路线图:
- V1 (Prompt Engineering): 仅使用系统提示词和硬编码的知识。验证核心逻辑。
- V2 (Basic RAG): 引入向量数据库,解决知识时效性问题。重点关注分块策略。
- V3 (Context Management): 引入滑动窗口记忆和摘要机制。解决多轮对话的遗忘问题。
- V4 (Tool Use & Action): 赋予 Agent 调用 API 的能力。重点关注工具定义的清晰度。
- V5 (Observability & Eval): 建立评估体系(如 Ragas)。监控“上下文污染”和“幻觉率”。使用 LangSmith 或类似工具回溯每一跳的上下文状态。
结语
AI Agent 的强大,不在于单个模型的参数量,而在于我们如何构建围绕模型的信息生态系统。
从 Demo 到生产的跨越,本质上是对有限注意力资源(Token)的极致管理。上下文工程就是这门管理的艺术——在正确的时间,以正确的格式,将最关键的信息呈现在模型的“视网膜”上,同时无情地剔除噪音。
当你的系统能够优雅地处理遗忘、精准地检索记忆、并自信地调用工具时,你就跨越了那道鸿沟。




















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











