







来源:Deepseek R1 论文解读-chance10010
链接🔗:https://www.bilibili.com/opus/1030715086492139523?spm_id_from=333.1387.0.0&unique_id=10e7841f-b314-45fa-ab72-0cf629421321&code=061eQNll2XANZe4Zm1pl24Ts2O0eQNll&state=
DeepSeek-R1:通过强化学习提升大型语言模型的推理能力
论文题目:《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
》
论文试图解决的问题
这篇论文介绍了一种新的第一代推理模型——DeepSeek-R1系列,旨在通过强化学习(Reinforcement Learning, RL)提升大型语言模型(Large Language Models, LLMs)的推理能力。具体来说,论文试图解决以下几个问题:
-
无监督数据的推理能力培养
- 传统LLMs依赖大量监督数据来提升推理能力。
- 论文提出了一种不依赖监督微调(Supervised Fine-Tuning, SFT)的方法,通过纯强化学习过程来培养模型的推理能力。
-
推理时的性能扩展
- 研究如何有效地在测试时扩展推理能力,例如增加推理链(Chain-of-Thought, CoT)的长度。
-
模型的自进化能力
- 论文探索LLMs在没有监督数据的情况下,通过自我进化发展推理能力的可能性,特别是纯RL过程。
-
提高模型的可读性和泛化能力
- 通过引入冷启动数据和多阶段训练流程,提升模型的可读性和语言混合问题。
-
小型模型的推理能力提升
- 通过知识蒸馏技术,将大型模型的推理能力迁移到小型模型,以提高效率。
相关研究
推理增强研究
- OpenAI的o1系列模型: 通过增加CoT推理过程长度,提升数学、编程、科学推理等任务的性能。
过程和结果的奖励模型(Process-Based Reward Models)
- Lightman et al. (2023): 提出基于过程的奖励模型,引导模型更好地进行推理。
- Uesato et al. (2022): 提供过程和结果的反馈。
- Wang et al. (2023): 研究奖励模型如何引导模型更好推理。
强化学习(Reinforcement Learning)
- Kumar et al. (2024): 探索如何使用强化学习训练语言模型进行自我修正。
- Shao et al. (2024) & Wang et al. (2023): 研究强化学习在推理任务中的有效性。
搜索算法
- Feng et al. (2024), Trinh et al. (2024), Xin et al. (2024): 探索蒙特卡洛树搜索(Monte Carlo Tree Search)和束搜索(Beam Search)在推理任务中的应用。
模型蒸馏(Model Distillation)
- Qwen (2024b) & Llama (Dubey et al., 2024): 论文利用这些基础模型进行知识蒸馏,以提升小型模型推理能力。
人类偏好对齐(Aligning with Human Preferences)
- Hendrycks et al. (2020), Gema et al. (2024), Wang et al. (2024): 研究多任务语言理解的基准测试,帮助模型对齐人类偏好。
代码和数学基准测试
- Jain et al. (2024) & MAA (2024): 评估代码和数学任务的基准测试。
论文如何解决这些问题?
1. 引入DeepSeek-R1-Zero模型
- 无监督强化学习(RL): 不依赖SFT,展示出色推理能力。
- 自进化: 训练过程中自然发展推理行为,如自我验证、反思、长CoT推理链。
2. 引入DeepSeek-R1模型
- 多阶段训练 & 冷启动数据: 解决DeepSeek-R1-Zero的可读性和语言混合问题。
- 冷启动数据收集: 通过少量提示和模型自生成答案,微调DeepSeek-V3-Base模型作为RL起点。
3. 强化学习算法
- Group Relative Policy Optimization (GRPO): 通过组分数估计基线,避免使用与策略模型同样大小的评论模型,降低RL训练成本。
4. 奖励建模
- 准确性奖励和格式奖励: 采用基于规则的奖励系统,训练模型生成特定格式的推理过程和最终答案。
5. 训练模板
- 推理过程和答案的模板: 训练模型首先生成推理过程,然后生成最终答案。
6. 知识蒸馏
- 大型模型向小型模型迁移推理能力: 使用Qwen2.5和Llama作为基础模型,从DeepSeek-R1进行蒸馏,提升小型模型推理能力。
7. 实验和评估
- 广泛基准测试: 数学、编程、知识问答等任务,验证模型性能。
论文实验
-
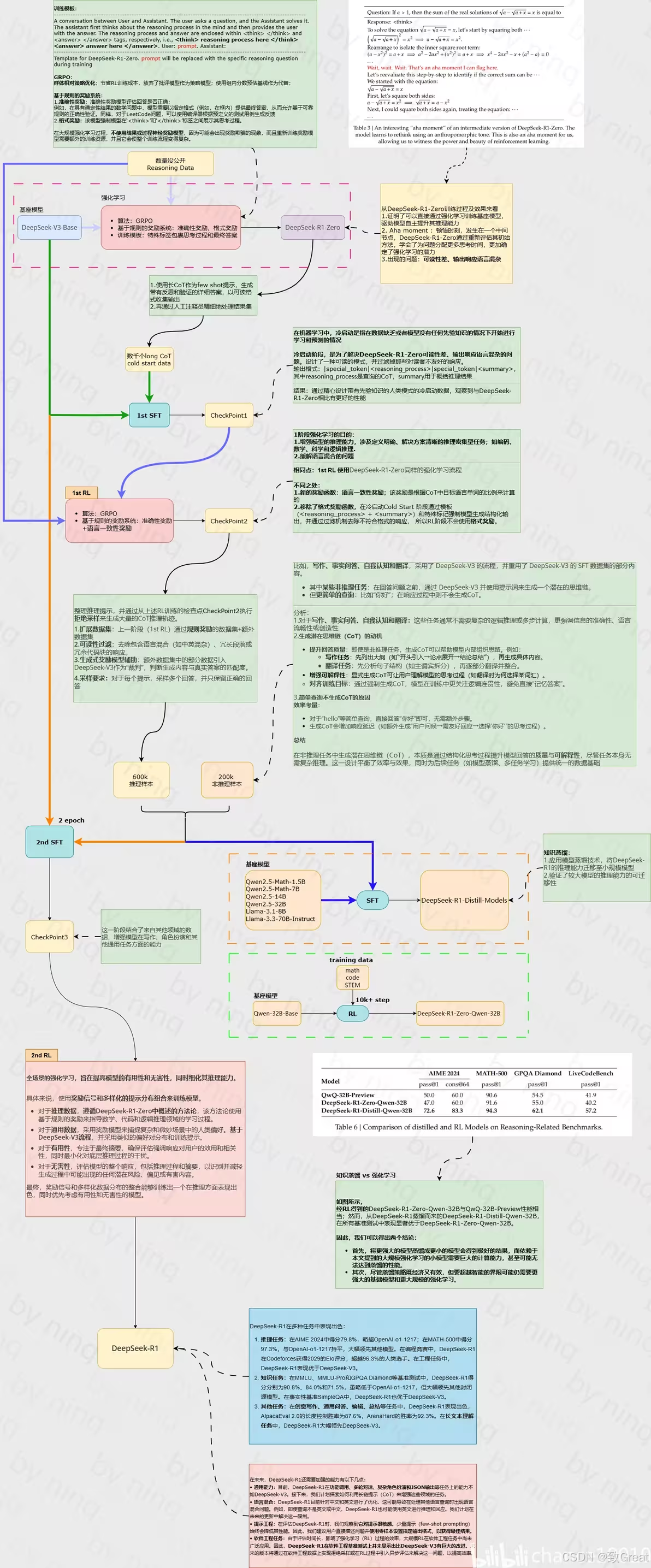
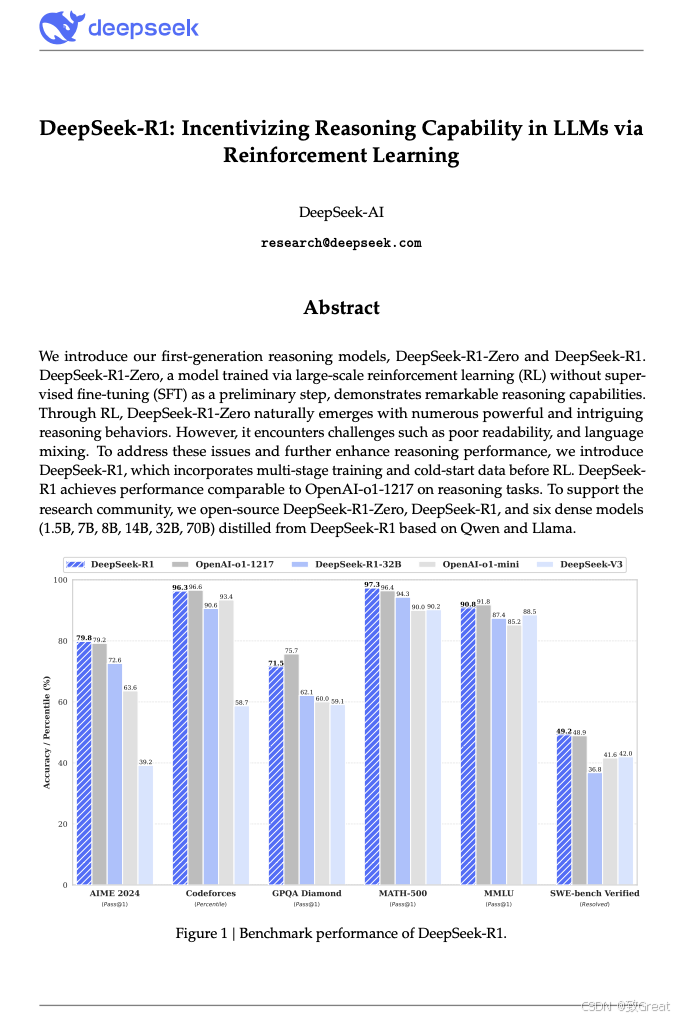
DeepSeek-R1 评估
- 基准测试: MMLU、C-Eval、SWE-Bench Verified、Codeforces等。
- 开放性任务: 采用AlpacaEval 2.0和Arena-Hard评估。
- 与其他模型比较: DeepSeek-V3, Claude-Sonnet-3.5, GPT-4o, OpenAI-o1-mini等。
-
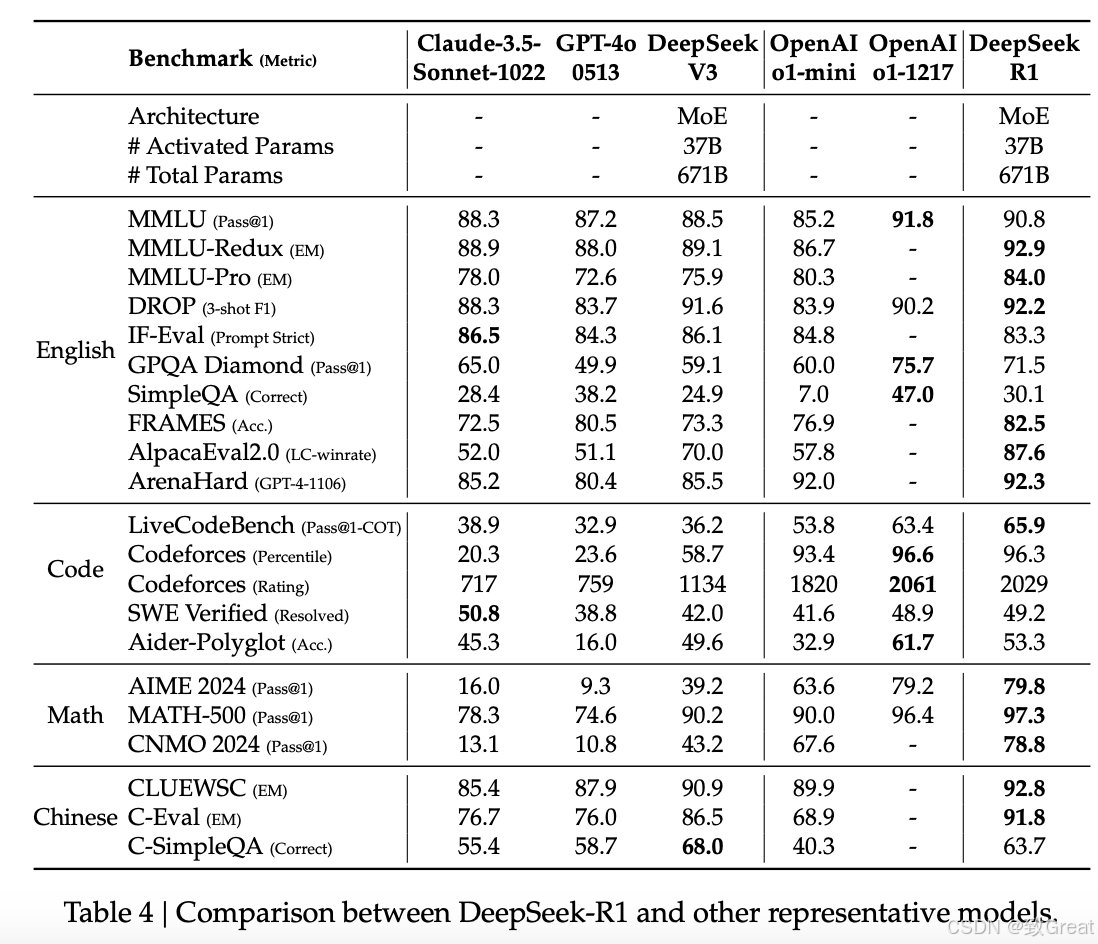
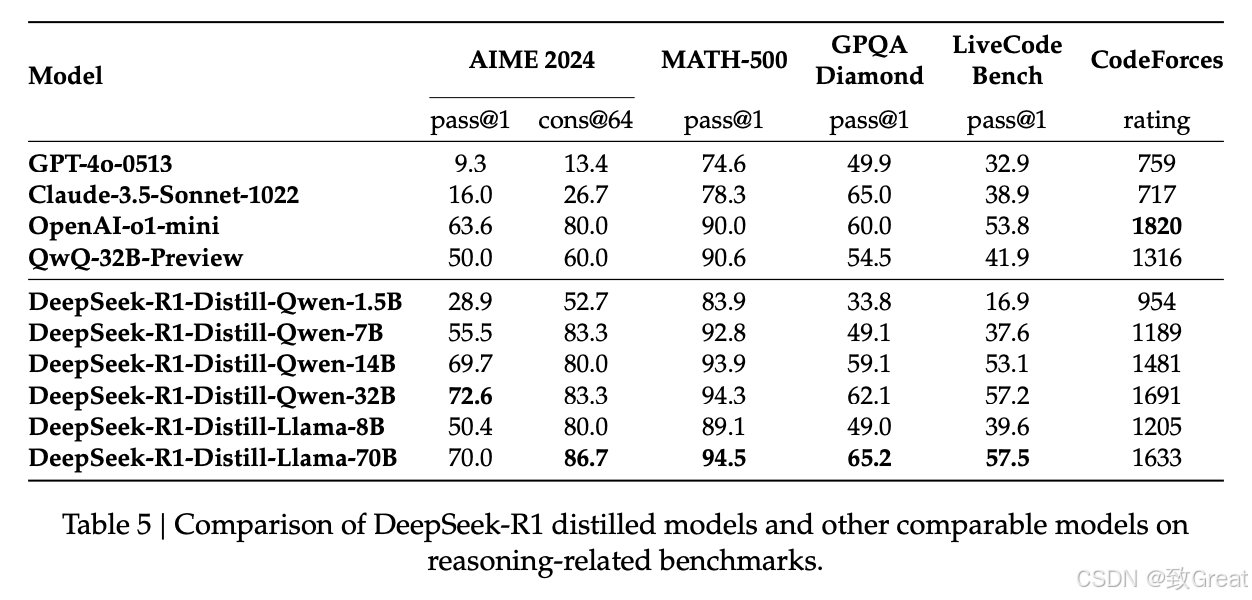
知识蒸馏模型评估
- 小型模型性能: AIME 2024, GPQA Diamond, Codeforces等任务。
- 与开源模型比较: 与QwQ-32B-Preview等进行对比。
-
实验设置
- 最大生成长度: 32,768个token。
- 评估方法: 使用pass@k评估,并报告pass@1结果。
- 共识结果: 对AIME 2024,报告使用64个样本的共识(多数投票)结果。
未来研究方向
- 长期推理链(Long CoT): 增强函数调用、多轮对话、复杂角色扮演、JSON输出等任务能力。
- 优化多语言处理能力: 解决DeepSeek-R1在非中文或英文查询时的语言混合问题。
- 减少对提示的敏感性: 优化零样本设置下的性能。
- 提升软件工程任务的效率: 采用拒绝采样或异步评估提高性能。
- 扩展模型规模和数据: 进一步提升推理能力。
- 优化GRPO算法: 提高训练效率和模型性能。
- 更复杂的奖励系统: 结合规则和神经网络方法优化奖励建模。
- 多模态输入的处理: 跨领域任务推理能力增强。
- 增强安全性和伦理性: 避免有害内容生成。
- 模型实际应用: 在教育、医疗咨询、客户服务等领域部署。
论文总结
论文提出DeepSeek-R1系列模型,利用强化学习提升LLMs推理能力。通过多阶段训练、奖励建模、知识蒸馏等手段,提升推理能力,并在多个基准测试中验证有效性。此外,论文开源模型和相关工具,支持研究社区进一步探索和改进。


















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









