







做了一些实验来查看不同 GPU 上转录的时间成本。结果可能有助于您选择购买或租用哪种类型的 GPU。
- 环境:Pytorch 1.13 CUDA 11.6 Ubuntu 18.04
- 数据集:LJSpeech 从 LJ001-0001.wav 到 LJ001-0150.wav 总长度为 971.26 秒
| 图形处理器 | 中等 FP16 | 中等 FP32 | 大型 FP16 | 大型 FP32 | 实际时间成本 |
|---|---|---|---|---|---|
| 2080Ti | 148.18秒 | 219.39秒 | 255.30秒 | 448.24 秒 | 3.7x |
| 3080Ti | 109.24秒 | 107.81秒 | 172.35秒 | 186.32 秒 | 1.6倍 |
| 3090 | 145.53秒 | 122.58秒 | 214.87秒 | 186.12秒 | 1.6倍 |
| 4090 | 99.60秒 | 79.99秒 | 149.03秒 | 120.05秒 | 1x |
| V100 | 203.25秒 | 174.18秒 | 284.62 秒 | 253.42秒 | 2.1x |
| A4000 | 135.99秒 | 128.12秒 | 205.21 秒 | 214.69秒 | 1.8x |
| A5000 | 143.97秒 | 124.50秒 | 205.43秒 | 198.11秒 | 1.7倍 |
| A6000 | 139.25秒 | 115.63秒 | 194.95秒 | 175.97秒 | 1.5倍 |
| A100 PCIE 40G | 133.01 秒 | 113.94秒 | 196.19秒 | 175.62秒 | 1.5倍 |
| A100 SXM4 40G | 123.66秒 | 105.85秒 | 172.36秒 | 162.67秒 | 1.4x |
代码
import torch
import time
import whisper
import os
device = torch.device('cuda')
model_list = ['medium', 'large-v2']
fp16_bool = [True, False]
path = './benchmark/'
file_list = os.listdir(path)
for i in model_list:
for k in fp16_bool:
model = whisper.load_model(name=i, device=device)
duration_sum = 0
for idx, j in enumerate(file_list):
audio = whisper.load_audio(path + j, sr=16000)
start = time.time()
result = model.transcribe(audio, language='en', task='transcribe', fp16=k)
end = time.time()
duration_sum = duration_sum + end - start
print("{} model with fp16 {} costs {:.2f}s".format(i, k, duration_sum))
del model其他测试结果
问:
我也想买 4070,但担心 12GB 是否适合 Large-v3 型号。
答:
我认为 10GB 卡对于 large-v3 型号来说已经足够了。我购买了 3080 10G 卡,它运行 large-v3 型号就很好了。
答 2
购买 4 块 RTX 4070 后,我们进行了一些基准测试,您确实对此非常满意。不同 GPU 之间在 Whisper 转录方面的性能差异似乎与您在光栅化性能方面看到的差异非常相似。我们将 T4 与 RTX 4070 和 RTX 4060 Ti 进行了测试,并得出结论:RTX 4070 具有最佳的性价比。
Macbook Pro 14 M2 Max
配备 32GB 内存的 Macbook Pro 14 M2 Max 得到以下结果:
配备 fp32 的中型模型耗时 546.83 秒,
配备 fp32 的大型 v2 模型耗时 904.46 秒,耗时
7.537 倍
我使用免费层硬件对 Huggingface 空间进行了基准测试:
Hugging Face Space Free Tier 2 vCPUs 16GBs ram
tiny.en model with fp16 False costs 430.07s
base.en model with fp16 False costs 563.06s
small.en model with fp16 False costs 1822.23s
medium model with fp16 False costs 4142.89s
large-v2 model with fp16 False costs 7335.92s以及 I9 13900K:
NVIDIA GeForce RTX 3090
Python 3.11.4 (main, Jul 5 2023, 13:45:01) [GCC 11.2.0]
Torch 2.1.0+cu121
Whisper 20230918
tiny.en model with fp16 True costs 10.22s
tiny.en model with fp16 False costs 5.65s
base.en model with fp16 True costs 9.75s
base.en model with fp16 False costs 8.06s
medium.en model with fp16 True costs 44.88s
medium.en model with fp16 False costs 43.01s
large-v2 model with fp16 True costs 75.89s
large-v2 model with fp16 False costs 66.34s以及同款 RTX 3090 的低调版本,以供比较:
NVIDIA GeForce RTX 3090
Python 3.11.4 (main, Jul 5 2023, 13:45:01) [GCC 11.2.0]
Torch 2.1.0+cu121
Whisper 20230918
tiny.en model with fp16 True costs 10.22s
tiny.en model with fp16 False costs 5.65s
base.en model with fp16 True costs 9.75s
base.en model with fp16 False costs 8.06s
medium.en model with fp16 True costs 44.88s
medium.en model with fp16 False costs 43.01s
large-v2 model with fp16 True costs 75.89s
large-v2 model with fp16 False costs 66.34s测试代码
import gradio as gr
import torch
import time
import whisper
import os, sys
def bench(device_name):
if device_name=="":
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
else:
device = torch.device(device_name)
string = torch.cuda.get_device_name(0)
string += "\nPython " + sys.version
string += "\nTorch " + torch.__version__
string += "\nWhisper " + whisper.__version__ + "\n"
print(string)
model_list = ['tiny.en', 'base.en', 'medium.en', 'large-v2']
fp16_bool = [True, False]
path = 'benchmark/'
file_list = os.listdir(path)
for i in model_list:
for k in fp16_bool:
model = whisper.load_model(name=i, device=device)
duration_sum = 0
for idx, j in enumerate(file_list):
audio = whisper.load_audio(path + j, sr=16000)
start = time.time()
result = model.transcribe(audio, language='en', task='transcribe', fp16=k)
end = time.time()
duration_sum = duration_sum + end - start
print("{} model with fp16 {} costs {:.2f}s".format(i, k, duration_sum))
string += "{} model with fp16 {} costs {:.2f}s".format(i, k, duration_sum) + "\n"
del model
return string
iface = gr.Interface(fn=bench, inputs="text", outputs="text")
iface.launch()测试单位(PPM 每分钟处理音频/录音秒数)
| RTX 4070 Super 12GB | Debian 12.5 上的 Docker(裸机) | 17,60 | 27,91 | 19,11 | 两个文件,每个文件运行四次 |
| RTX 4070 Super 12GB | Windows WSL2 上的 Podman | 16,85 | 41,38 | 24,10 | 两个文件,每个文件运行七次 |
| RTX 4060ti 16GB | Windows WSL2 上的 Podman | 16,26 | 20,76 | 18,01 | 两个文件,每个文件运行五次 |
CPU 的情况
| CPU 型号 | 环境 | 最小 PpM | 最大 PpM | 平均每分钟流量 | 评论 |
| Ryzen 7 5700G @ 3.80 GHz,8 核 | Windows WSL2 上的 Podman | 157,89 | 214,29 | 176,47 | 两个文件,每个文件运行三次 |
| i7-6700K @ 4.00 GHz,4 核 | Windows WSL2 上的 Podman | 171,43 | 285,71 | 无 | 两个文件,每个文件运行两次 |
| i5-4460 @ 3.2 GHz,4 核(kein HT) | Debian 12.5 上的 Docker(裸机) | 142,86 | 240 | 无 | 两个文件,各运行一次 |
| Xeon Gold 5415+ @ 2,90 GHz,4 个 vCore | Hyper-V 主机上的 Debian VM 上的 Docker | 71,43 | 272,73 | 130,43 | ) |
| Xeon E5-2620 v3 @ 2.40 GHz,4 个 vCore | Hyper-V 主机上的 Debian VM 上的 Docker | 200 | 240 | 无 | 珠宝 |
另外的对比图
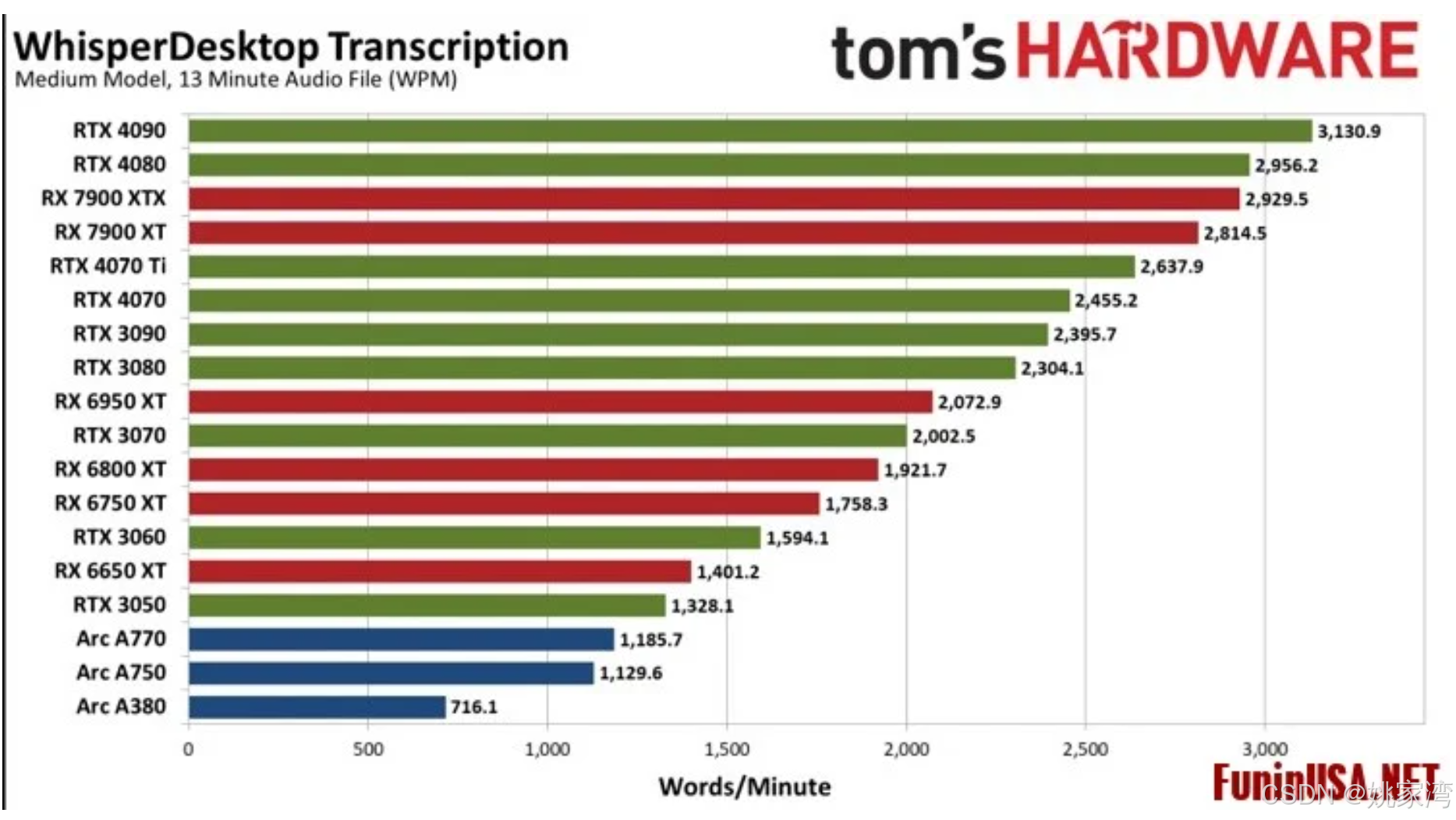
看来 RTX 4070 性价比比较好,待我买来了RTX4070 super 后再报告结果

















 9698
9698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









