







目录
目的
任务分配的目的:为编队中的每艘USV分配一个任务列表,并根据任务列表为每艘USV规划航行路径,保证编队任务执行效率的最大化。
自主避碰的目的:根据USV在其探测范围内遇到的船舶的运动特性,重新规划USV的航行路径,确保无人驾驶船舶的航行安全。
贡献
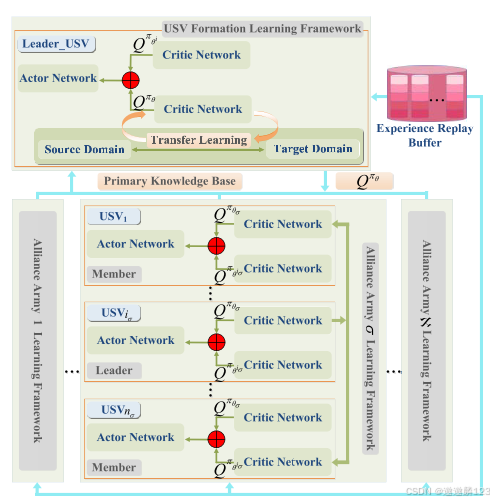
1) 利用VDN的思想,将任务规划问题分解为两个子问题:a)任务分配和B)自主避碰。为每个子问题定制不同的状态空间、动作空间和奖励函数。然后,利用深度神经网络将每个子问题的状态空间映射到每个USV的动作空间。深度神经网络生成的策略通过相应的奖励函数进行评估。这就成功地将任务分配和路径规划集成到一个全面的任务规划框架中。
2) 设计一个联盟军队学习框架。
首先,改进PPO。
然后,采用VDN将价值函数分解为两部分:一部分用于评价任务分配方案和协同运动轨迹的优劣,记为Qπθσ;另一部分用于评价避碰策略的有效性,记为Qπθiσ。
Qπθiσ函数的更新只需要考虑单个USV的观测信息和动作信息,因此,采用改进的时域差分误差法训练用于逼近Qπθiσ函数的深度神经网络。
Qπθσ函数的更新需要考虑所有USV的观测信息和动作信息的问题,采用后继特征组合和改进的时域差分误差法训练用于逼近Qπθσ函数的深度神经网络。
3) 设计了一个无人艇编队学习框架。
以盟军学习框架为基础,融合了层级机制、区域分工机制和迁移学习方法。这使得盟军中的多USV所获得的知识能够传递到整个编队,从而使得多USV能够快速而准确地学习。
其他方法缺点
集中式任务分配:很大程度上依赖于决策agent,难以解决大规模,多目标和复杂的任务分配问题,而且在决策代理故障或攻击的情况下,编队的任务分配方案可能会受到严重影响。
分布式任务分配:由于智能体之间观测精度的差异以及观测噪声等不确定性的影响,智能体之间的任务分配结果往往会出现冲突,从而导致不必要的资源消耗,大大降低编队内任务执行的整体效率。
经典的数学优化模型:在简化复杂的任务分配模型时,可能会阻碍在复杂的任务分配过程中的多个影响因素之间的潜在关系的充分表达,特别是在涉及实时决策,动态环境和大规模多智能体系统的情况下。此外,也没有考虑动态环境中的agent的路径规划。
挑战
1) 在多USV系统中,个体USV的行为决策会受到其他USV的影响,导致环境的非平稳性。由于MARL算法迭代优化主要依赖于从与环境的交互中获得的数据。环境的非平稳性会影响样本数据的分布,从而导致训练过程中算法的不稳定性。
2) 随着编队内USV的增加,多USV系统的联合观测空间和联合行动空间将呈指数级扩展,面临着探测空间大、训练时间长、收敛困难等挑战。
3) 针对任务规划问题,在复杂的环境和复杂的任务中,设计合适的奖励函数是一个非常具有挑战性的问题。
系统模型
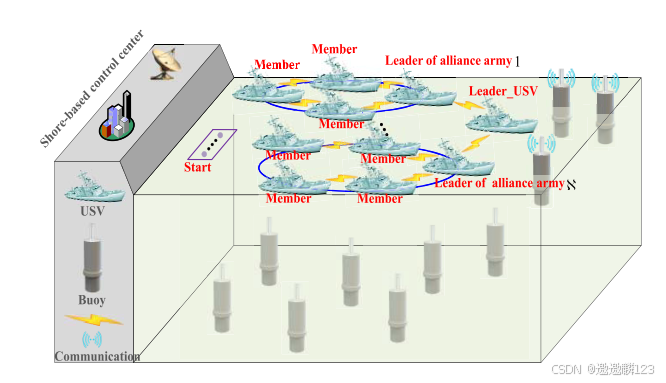
假设多个USV采用动态联盟机制的编队结构,协同采集目标海域智能浮标的水下数据,则假设编队由1个Leader_USV和n个Follower_USV组成。
以距离为原则划分联盟。
在每个盟军内部,成员之间以信息密度为竞争基础,信息密度最高的成员成为相应联盟军的首领。
每个联盟军队的领导者可以直接与Leader_USV通信,而联盟成员通过与各自联盟军队的领导者通信来间接与Leader_USV通信。
对于任务分配问题,要考虑的约束包括环境因素,任务要求,目标状态,以及编队中每个USV的任务执行能力。
任务分配目标是最大限度地提高编队任务的执行效率。通过任务分配方案和协同运动轨迹的性能,评估编队任务执行的效率。
为保证任务分配方案和协同运动轨迹的可行性,任务执行的agent需要在构建过程中充分考虑约束。
约束条件
1. 无冲突任务分配方案的约束: 无冲突任务分配方案是指每个任务最多只能由一个执行者完成。
2. 满足安全(避障)和节能的约束。
3. USV和智能浮标之间的通信距离约束。
4. 对USV任务执行能力的约束: 如果USVi在执行任务期间耗尽其机载燃料,它将失去执行剩余任务的能力,从而导致重大损失。
此外,由于USV具有欠驱动、大惯性和强时滞的特点,规划的路径必须符合USV最小转弯半径的约束。
5. 多USV协作约束: 规划的协作运动轨迹应确保编队中的所有USV同时到达其在装配区域内的对应位置。
自主避障
USVi通过改变速度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









