







 本文探讨了Seq2Seq模型在翻译任务中的应用,重点介绍了GreedySearch算法及其局限性。通过实例比较了不同翻译结果的优劣,指出贪心算法可能无法获得最佳翻译。
本文探讨了Seq2Seq模型在翻译任务中的应用,重点介绍了GreedySearch算法及其局限性。通过实例比较了不同翻译结果的优劣,指出贪心算法可能无法获得最佳翻译。
1. 引入
用Seq2Seq模型开发翻译系统时,假设输入一句法语,输出英文。在Decoder输出部分,选择不同的单词,输出(翻译)的结果也会不同。
这里用下图来举例说明:

一个法语句子,被Seq2Seq模型翻译为不同的4句英文,我们该选择哪个结果作为最终结果呢?
上图中,给了一个公式,式中的x表示法语句子,y表示各个单词组成的最终的英文句子,不同的y的组合表示不同的翻译,即y1~yn表示单词序列。
解决这个问题的关键,就在于找到合适的y值,使得图中的公式值最大化。
但是具体怎么做呢?下面我们介绍一种方法:Greedy Search。
2. 贪心算法:Greedy Search
第一种选择方法,是最简单的贪心搜索,这是一种贪心算法,它最简单:每次选择输出概率值最大的那个单词组成单词序列,如下图所示:
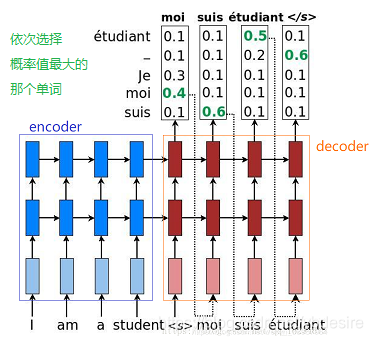
首先,挑选第一个概率值最高的单词作为输出,并将其输入decoder,然后,再选择概率值最高的第二个,第三个,。。。
很显然,这不是一种非常好的方法。因为,贪心算法找到的并不是最优解。比如翻译出来的两句英文为:
- A. Jane is visiting Africa in September.
- B. Jane is going to be visiting Africa in September.
这两句翻译,从内容上A和B都正确,但A显的更简洁,是更好的翻译。但如果使用贪心算法,输入"Jane is"后,可能会得到"going",因为"going"更常用,所以算法最终选择的是B。
最理想的做法,是穷举每种类型的输出,然后看上一节的公式值是否为最大,这才能找到最优解,但这要穷举太多的次数,复杂度是没法接受的。
参考
- [1]. https://blog.csdn.net/weixin_38937984/article/details/102492050
- [2]. Andrew Ng Sequence Models video

















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









