








大纲

Recap and Preview
下图是到目前为止,我们所能了解到的机器学习的基本流程
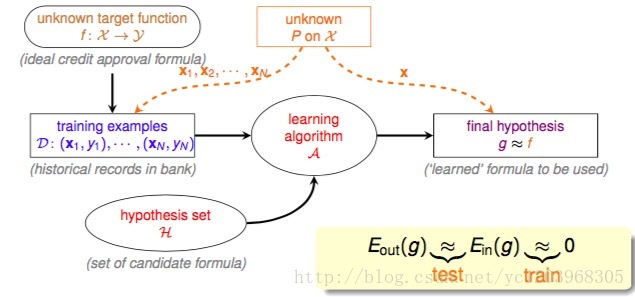
该流程图说明,用于训练的训练数据
D
和用于测试演算法所选择的最好的假设

回顾一下前面四节课所讲到的内容,其实都是层层铺垫的
第一节课,定义了机器学习的目的,即 g≈f ,也就说让 Eout(g)≈0
第二节课,我们通过演算法,使 Ein(g)≈0
第三节课,我们把重心放在批量监督分类问题上,这是机器学习的一个核心问题
第四节课,我们建立起 Eout(g)和Ein(g) 的联系,即,在一定的假设条件下, Eout(g)≈Ein(g)
其实我们可以把机器学习问题总结为两个问题
我们能否使 Ein(g) 足够接近 Eout(g)
我们能否使 Ein(g) 足够小
下面我们看看 M 在这两个问题中的Trade-off

- 当M比较小的时候,
Ein(g) 足够接近 Eout(g) ,但是我们面临更小的选择,可能找不到合适的 g ,使Ein(g)≈0 - 当M比较大的时候,我们可以使
Ein(g)≈0
,但是我们不能让
Ein(g)
足够接近
Eout(g)
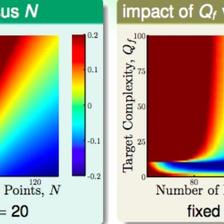
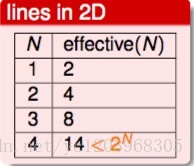
所以选择合适的M很重要,在PLA问题中,M的个数无限大,为什么PLA能很好的进行机器学习呢? Effective Number of Lines
首先我们回顾一下union bound形式的hoffeding不等式
当M无限大的时候,左边可能会大于1,为什么会发生这种情况?
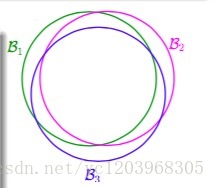
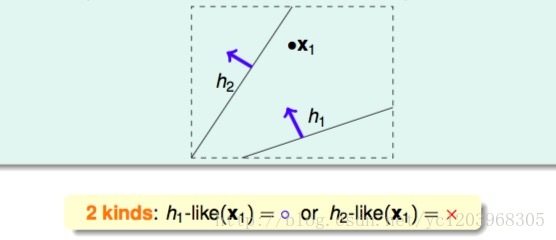
这是我们在计算Bad Sample概率的时候,把重叠的部分也算进去了,如下图所示
因为存在相似的假设, h1≈h2 ,为了解决这个问题,我们可以把相似的假设归为一类,来计算有效的M
如何将无限的假设归为有限的类,看下面的例子
- 一个点的情况
两个点情况
三个点的情况
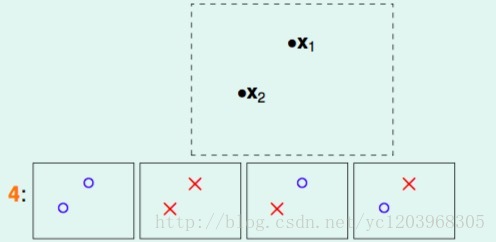
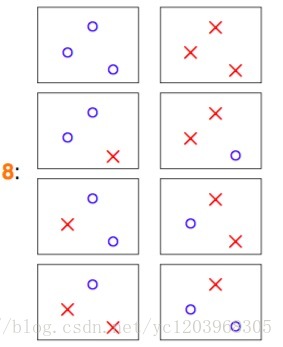
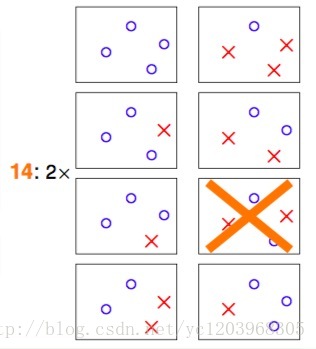
四个点的情况
总结一下
所以我们可以用effective(N)来代替M,因此就有
P[|Ein(g)−Eout(g)|>ϵ]≤2⋅effective(N)⋅exp(−2ϵ2N)
这里 effective(N)<<2N
当N很大的时候,右边接近0,所以学习问题是可行的。Effective Number of Hypothesis
一些概念
首先我们定义两个概念
Dichotomies:平面上能将点完全用直线分开的直线种类,它的上界是 2N ,用符号 |H(x1,x2,..xN)| 表示
我们尝试用 |H(x1,x2,..xN)| 替代MGrowth Function:因为 |H(x1,x2,..xN)| 依赖所给的数据 D ,所以我们为了移除这种依赖,定义
mH(N)=maxx1,x2...xn∈X|H(x1,x2,..xN)|
计算成长函数
我们考虑四种情况
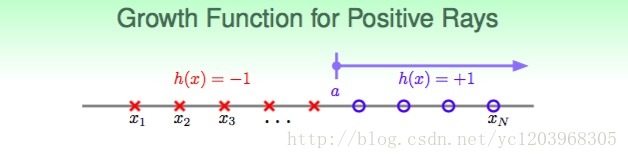
Positive Rays
这里 mH(N)=N+1 ,当N很大的时候, N<<2NPositive intervals
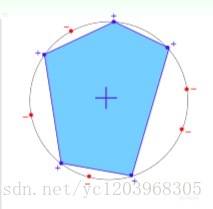
这里 mH(N)=C2N+1 ,当N很大的时候, N<<2Nconvex region
定义这样的 h ,当x在convex region上面时,h(x) =+1,反之为-1.
为了计算所有情况,我们可以按照以下方式定义x的分布
很容易算出 mH(N)=2N ,这种情况下,N个点所有可能的分类情况都能够被hypotheses set覆盖,我们把这种情形称为shattered。
做一个总结
其中,positive rays和positive intervals的成长函数都是polynomial的,如果用 mH 代替M的话,这两种情况是比较好的。而convex sets的成长函数是exponential的,即等于M,并不能保证机器学习的可行性。那么,对于2D perceptrons,它的成长函数究竟是polynomial的还是exponential的呢?
Break Point
定义
满足 mH(k)≠2k 的k的最小值就是break point
举例
通过观察,我们可以做出一些猜想
- 没有break point, mH(k)=2K ,这是确定的
- 如果存在break point。 mH(k)=O(Nk−1) (猜想),如果成立的话,这就可以保证机器学习的可行性。
- 当M比较大的时候,我们可以使
Ein(g)≈0
,但是我们不能让
Ein(g)
足够接近
Eout(g)
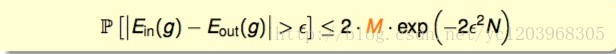




















 5182
5182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









