







 本文是Geoffrey Hinton关于神经网络机器学习系列的第三部分,探讨了训练感知机与隐含层的不同,解释了为什么不能直接解析求解神经网络,以及在线学习与批学习的区别。文章还讨论了学习过程缓慢的原因,并介绍了反向传播的思想和优化策略,如weight decay、dropout等。
本文是Geoffrey Hinton关于神经网络机器学习系列的第三部分,探讨了训练感知机与隐含层的不同,解释了为什么不能直接解析求解神经网络,以及在线学习与批学习的区别。文章还讨论了学习过程缓慢的原因,并介绍了反向传播的思想和优化策略,如weight decay、dropout等。
Neural Networks for Machine Learning by Geoffrey Hinton (3)
训练感知机的方法并不能用以训练隐含层
- 训练感知机的方式是每次直接修正权重,最终得到满足所有凸锥里的权重。可行解的平均一定还是可行解。
- 对多层神经网络而言,2个可行解的平均并不一定是可行解。
They should never have been called multi-layer perceptrons.
为何不解析求解神经网络?
- 我们希望了解神经网络具体工作方式。
- 我们需要能够扩展到深层神经网络的方法。
online delta-rule 与 感知机 learning rule 的区别与联系
感知机 learning rule 中,我们通过输入向量直接改变权重向量。
然而我们只能在出现错误时才能够调整权重。
online delta-rule 中,权重的修正量还带有残差和学习率作为系数。
Δwi=−ε∂E∂wi=∑nεxni(tn−yn)
错误面(Error Surface)
对于线性神经元、平方误差时,错误面是一个抛物面。
- 错误面的纵切面是抛物线。
- 错误面的横切面是椭圆。
在线(Online)学习与批(Batch)学习
- 在线学习权重在走之字形路线,如图1。
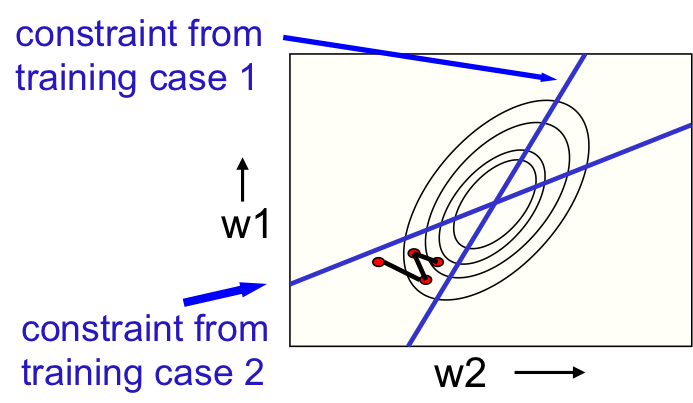
- 批学习权重路线要平缓得多,如图2。
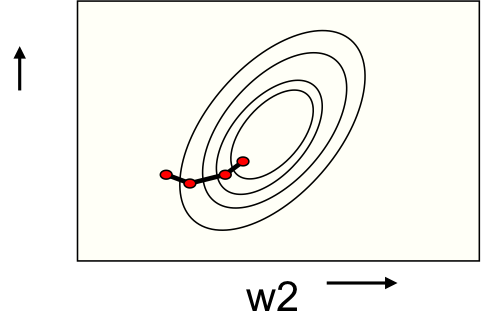
为何学习过程会这么慢?
在权重空间某2个维度具有一定的相关性时,错误面会被拉长,其横剖面就变成了一个长椭圆,如图3。

与我们希望刚好相反,如图的红色向量在短轴方向有巨大分量,而在长轴方向分量却很小。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6718
6718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









