









YOLOv5屏蔽区域检测以及选择区域检测
🐶🐶方法1-标注软件外部生成mask
前期准备
思路就是通过一个mask掩膜,对我们想要屏蔽或者选择的区域进行遮挡处理,在推理的时候,将有mask掩膜的图像输入,将最后的结果显示在原始图像上,即完成了屏蔽区域检测。
labelme选择mask区域

标注好我们想检测的区域之后,我这里将标注区域命名成了mask,然后我们点击保存导出json文件:
然后我们再打开终端,cd到json所在的文件夹路径下,输入如下命令:
labelme_json_to_dataset xxx.json
这里有的兄弟会遇到一些报错,主要原因还是环境的版本问题,可以在网上查到,替换一下对应版本的库就行了。
我们就会在这个路径下获得一个文件夹:
打开文件夹之后会看到里面有这么五个文件,我们需要的就是label.png,其他的不用管:
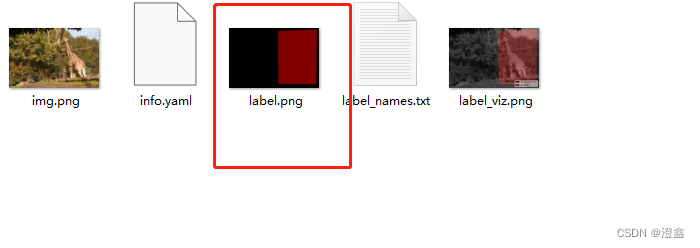
到这里,我们的前期准备工作就完成了。
代码改动
打开yolov5的项目,进入utils/datasets.py中,在代码的开头加上读取我们导出的label.png的代码:
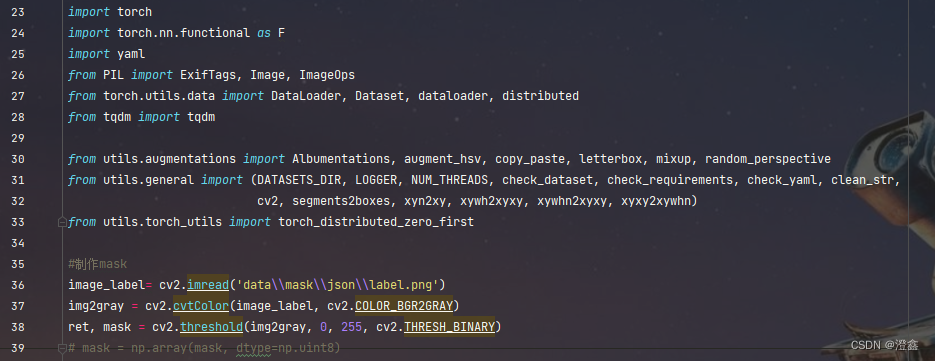
读入我们导出的mask图片文件,然后将其转成灰度图,然后使用opencv的阈值函数,将大于0的像素值全部变成255,其余的都为0,得到一张mask的二值图。
然后我们再看到yolov5自带的推理代码中,即detect.py文件。看到代码中的数据加载部分:
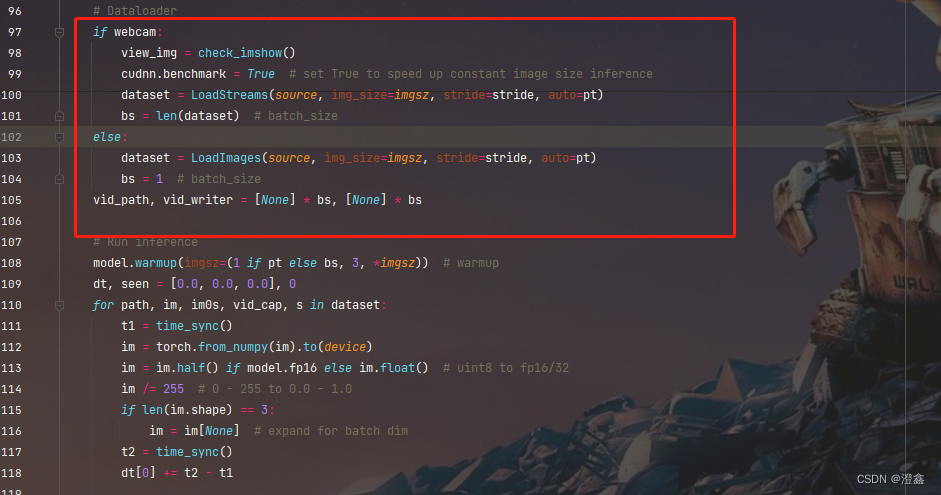
我们这里是对图像进行推理,因此我们加载的是图像,不进入webcam中,因此我们加载推理数据的方法是LoadImages这个类,cltr+左键进入这个类中,在这个位置下加入以下代码:
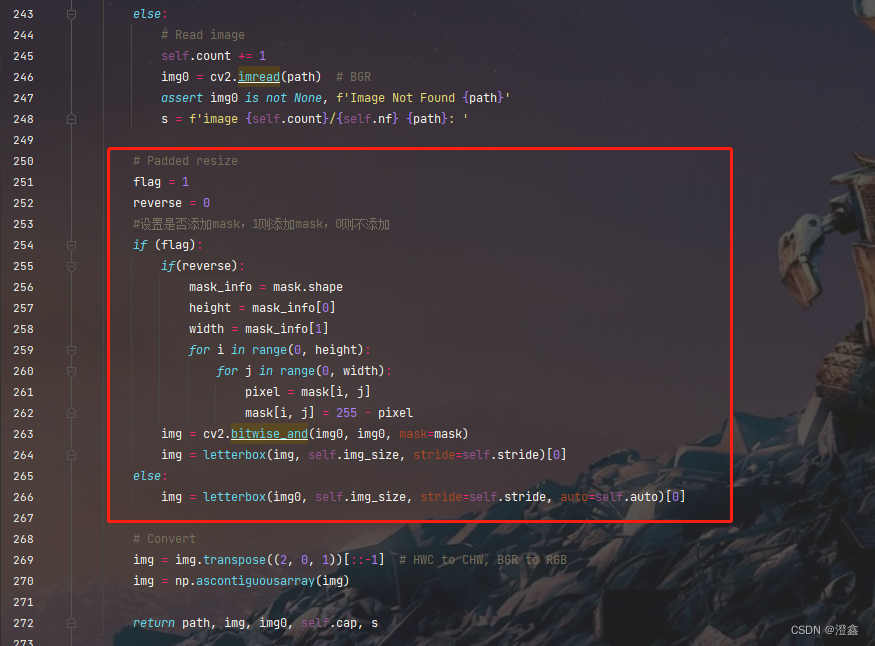
这段代码主要实现了两个功能,其中flag参数决定了我们是否使用mask掩膜对目标进行遮挡检测,reverse参数决定了我们是进行选择区域检测还是屏蔽区域检测(其实这两者是一个取反的操作)。
这里我的参数是flag=1,reverse=0,因此此时如果我运行程序的话,我们会看到的结果是只对我们刚才框定的mask区域的目标进行检测,而对其他地方并不会检测:

可以看到,和我们预想的一样。
我们再将参数改成flag=1, reverse=1,看看结果:
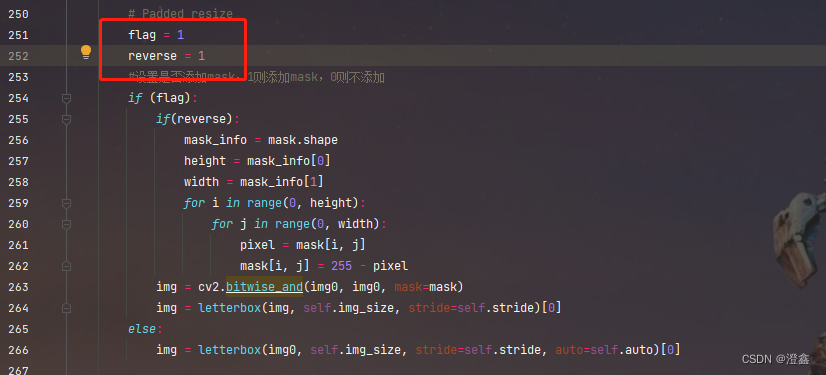

此时我们检测的区域是除了mask区域的以外区域,没问题。
那么最后我们将两个参数都设置为0:
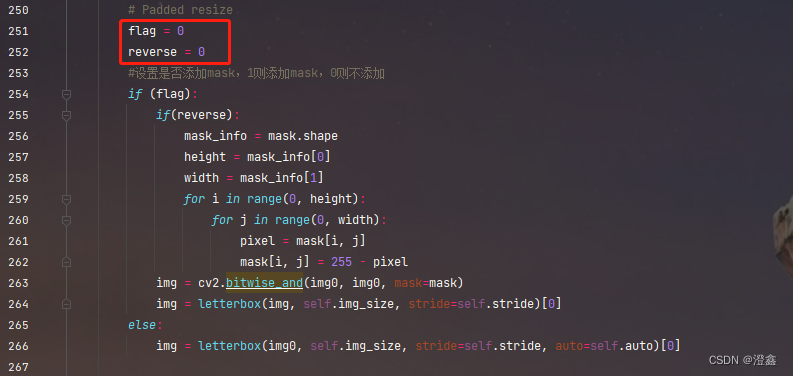

没有任何问题!
后面我也会使用openvino和tensorRT在c++进行推理部署,实现选择区域或屏蔽区域检测的功能,欢迎大家关注。
🐱🐱方法2-计算比例内部生成mask
代码改动
在detect.py脚本中,找到Dataloader部分,加入我们想要屏蔽的区域或者想要选择的区域的比例,然后通过生成mask来进行屏蔽:
这里还有个关键的地方需要我们注意!那就是在屏蔽区域经行检测时,推理图片和推理视频流时有小小的不同,图片的格式时chw,然而视频流时的图片格式为1,c,h,w多了一个维度,因此需要加入判断语句,贴出代码:
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
for path, im, im0s, vid_cap, s in dataset:
#我的增加
#比例
# 1,2,3,4 分别对应左上,右上,右下,左下四个点
hl1 = 28 / 446 # 监测区域高度距离图片顶部比例
wl1 = 269 / 640 # 监测区域高度距离图片左部比例
hl2 = 32 / 446 # 监测区域高度距离图片顶部比例
wl2 = 586 / 640 # 监测区域高度距离图片左部比例
hl3 = 414 / 446 # 监测区域高度距离图片顶部比例
wl3 = 589 / 640 # 监测区域高度距离图片左部比例
hl4 = 412 / 446 # 监测区域高度距离图片顶部比例
wl4 = 271 / 640 # 监测区域高度距离图片左部比例
if webcam:
mask = np.zeros([im.shape[2], im.shape[3]], dtype=np.uint8)
else:
mask = np.zeros([im.shape[1], im.shape[2]], dtype=np.uint8)
# im = im.transpose((1,2,0))
if webcam:
pts = np.array([[int(im.shape[3] * wl1), int(im.shape[2] * hl1)], # pts1
[int(im.shape[3] * wl2), int(im.shape[2] * hl2)], # pts2
[int(im.shape[3] * wl3), int(im.shape[2] * hl3)], # pts3
[int(im.shape[3] * wl4), int(im.shape[2] * hl4)]], np.int32)
else:
pts = np.array([[int(im.shape[2] * wl1), int(im.shape[1] * hl1)], # pts1
[int(im.shape[2] * wl2), int(im.shape[1] * hl2)], # pts2
[int(im.shape[2] * wl3), int(im.shape[1] * hl3)], # pts3
[int(im.shape[2] * wl4), int(im.shape[1] * hl4)]], np.int32)
mask = cv2.fillPoly(mask, [pts], (255,255,255))
if webcam:#视频流加载的数据有第四个维度,因此这里我们先将第四个维度取消,mask完之后 再加上第四个维度
im = np.squeeze(im)
im = im.transpose((1,2,0))
else:
im = im.transpose((1,2,0))
im = cv2.add(im, np.zeros(np.shape(im), dtype=np.uint8), mask=mask)
# cv2.namedWindow("test", cv2.WINDOW_NORMAL)
# cv2.imshow("test", im)
# cv2.waitKey(0)
im = im.transpose((2,0,1))
if webcam:#加上第四个维度
im = im[np.newaxis,:,:,:]
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
核心部分为:
















 1467
1467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











