






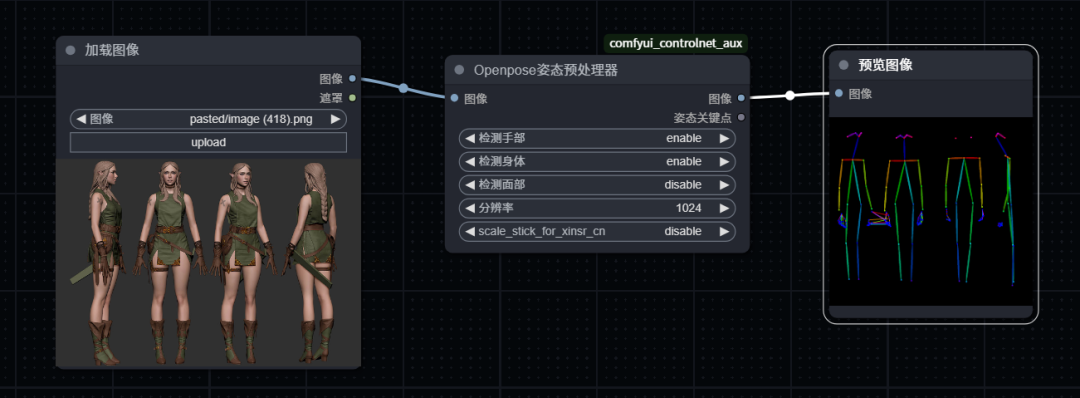
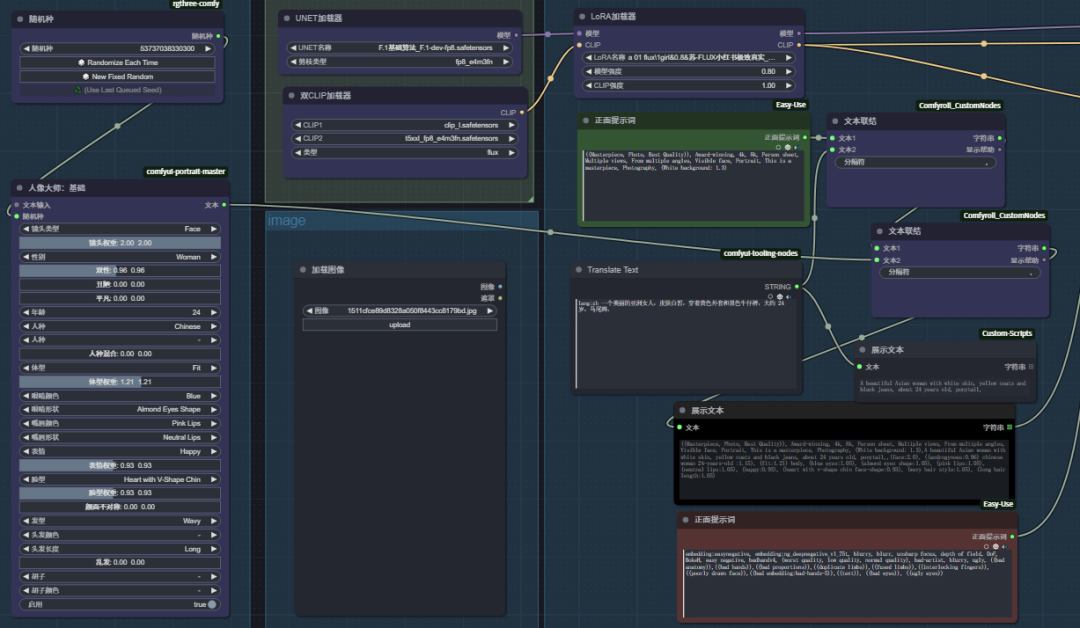
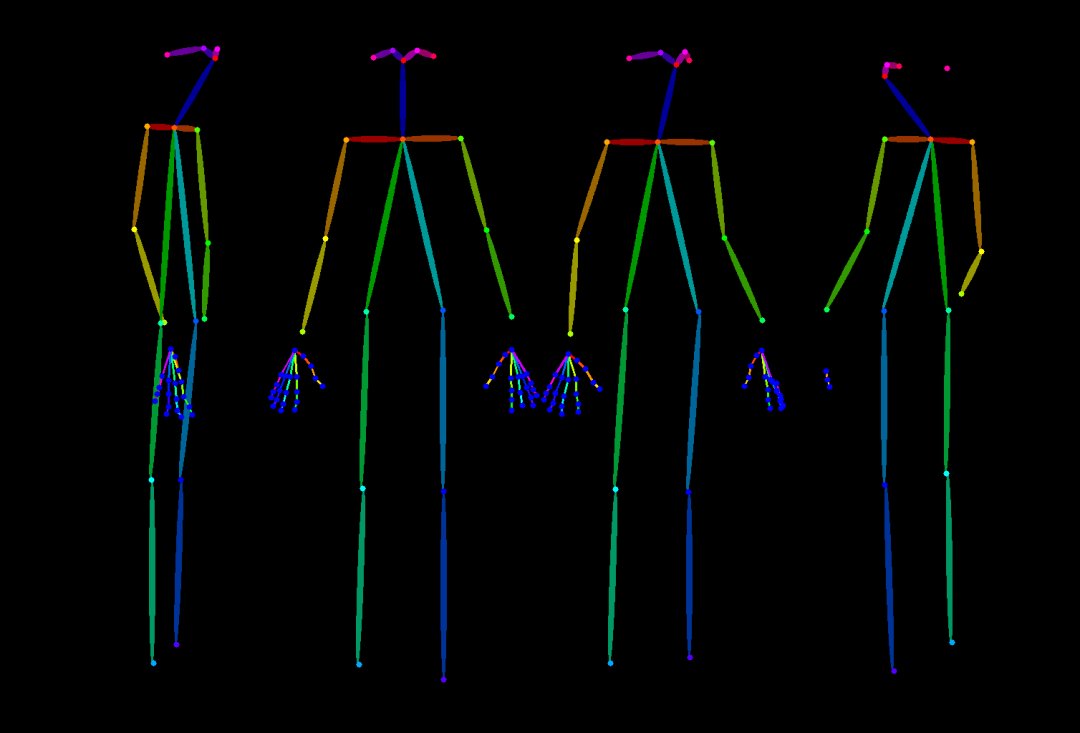
这是一个升级版人物多角度视图生成工作流,主要是去除了提示词反推,改为支持中文输入的自动翻译输入文本,主要是反推提示词对于生成人物不同视图往往过于复杂,耗费时间较长。然后是增加了骨架生成功能,可以上传图片,先生成Openopse骨架姿势图,再上传到controlnet 控制图层中,生成想要的人物姿态。
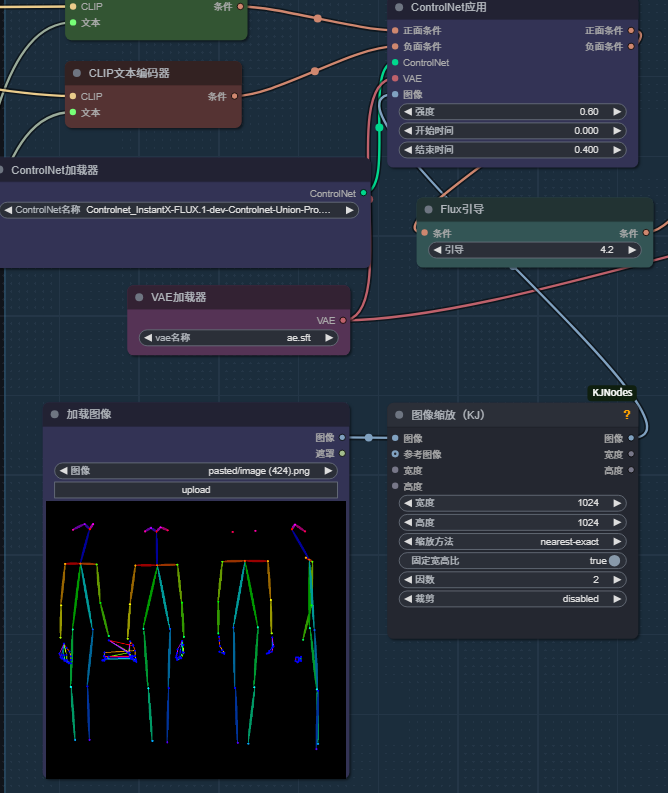
flux模型使用的是 Controlnet_InstantX-FLUX.1-dev-Controlnet-Union-Pro.safetensors cn控制模型。
输入提示词:lang:zh 一个美丽的亚洲女人,皮肤白皙,穿着黄色外套和黑色牛仔裤,大约 24 岁,马尾辫,


这份完整版的模型已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

Controlnet_InstantX-FLUX.1-dev-Controlnet-Union-Pro:多控制模式的AI图像生成工具
Controlnet_InstantX-FLUX.1-dev-Controlnet-Union-Pro 是由 InstantX 团队和 Shakker Labs 联合推出的一款先进的 AI 图像生成模型。该模型专为 InstantX-FLUX.1 开发版设计,集成了多种控制模式,包括边缘检测(Canny)、瓦片(Tile)、深度图(Depth)、模糊(Blur)、人体姿态估计(Pose)、灰度图像(Gray)和低分辨率图像(LQ)。这些控制模式使得用户可以在生成图像时实现更精确的控制,从而满足不同场景下的需求。
边缘检测(Canny) :通过边缘检测技术,生成具有清晰边缘的图像,适用于需要突出物体轮廓的场景。
瓦片(Tile) :将图像分割成多个小块,每个小块可以独立生成,适用于需要局部细节增强的图像。
深度图(Depth) :基于深度信息生成图像,适用于需要模拟三维效果的场景。
模糊(Blur) :通过模糊处理,生成柔和或朦胧效果的图像,适用于需要艺术化处理的场景。
人体姿态估计(Pose) :根据输入的姿态图生成相应的图像,适用于需要精确人体姿态控制的场景。
灰度图像(Gray) :生成灰度图像,适用于需要黑白效果或简化视觉效果的场景。
低分辨率图像(LQ) :生成低分辨率图像,适用于需要快速生成大量图像的场景。
多控制模式集成:FLUX.1-dev-Controlnet-Union-Pro 支持多种控制模式的同时使用,用户可以根据需求灵活选择和组合不同的控制模式,实现更复杂的图像生成任务。
高性能和高效率:该模型在训练过程中使用了更多的数据和步骤,相比之前的版本更加专业和高效。它可以在短时间内生成高质量的图像,适用于需要快速迭代的项目。
灵活性和可扩展性:用户可以通过调整控制参数(如 control_mode 和 controlnet_conditioning_scale)来微调生成效果,满足不同场景的需求。
根据多项测试结果,FLUX.1-dev-Controlnet-Union-Pro 在准确率、召回率和资源消耗指标上表现出色。基准测试、压力测试和对比测试均显示该模型在多控制模式下具有优异的性能。
Controlnet_InstantX-FLUX.1-dev-Controlnet-Union-Pro 是一款功能强大且灵活的 AI 图像生成工具,适用于多种复杂场景。其多控制模式的设计不仅提高了生成图像的质量和效率,还为用户提供了更多的创作自由度。随着技术的不断进步,该模型的性能将进一步提升,为用户提供更加丰富的图像生成体验。
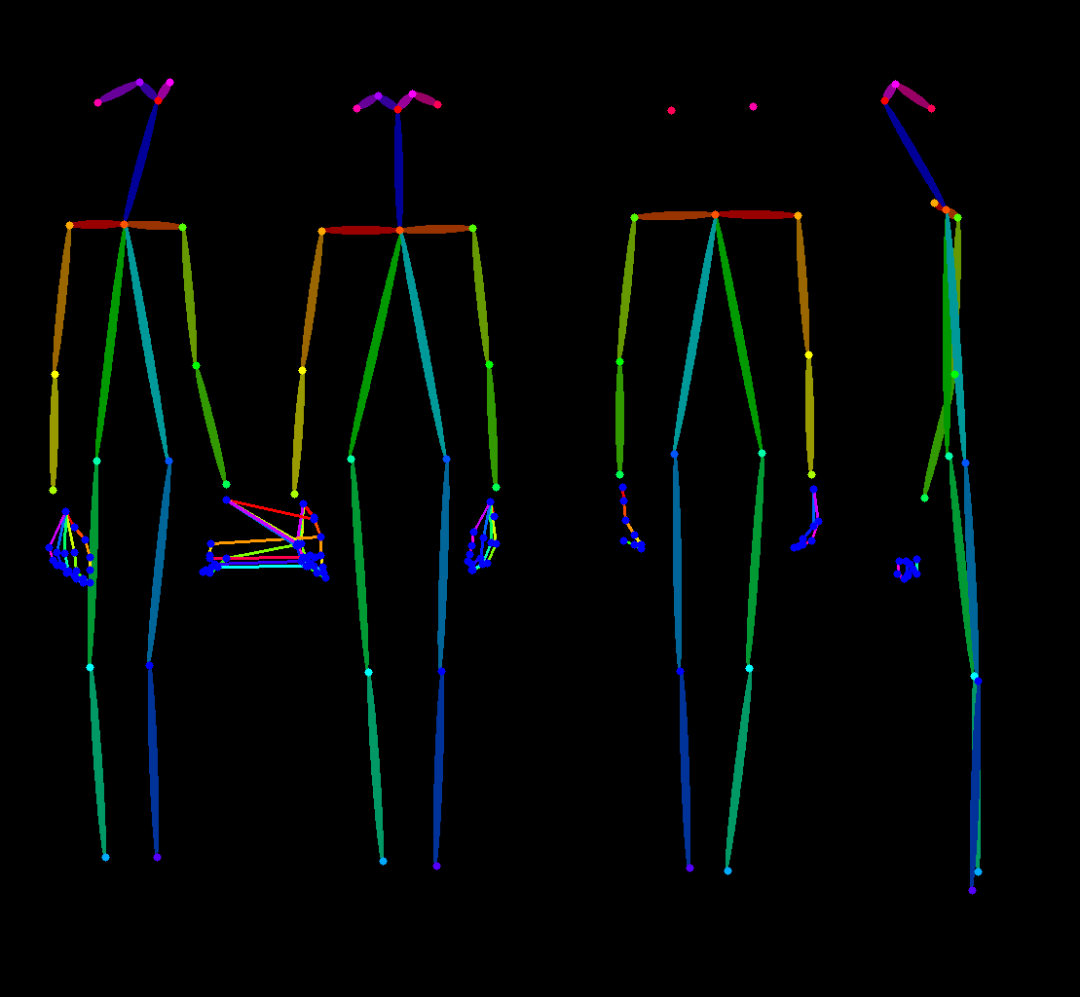



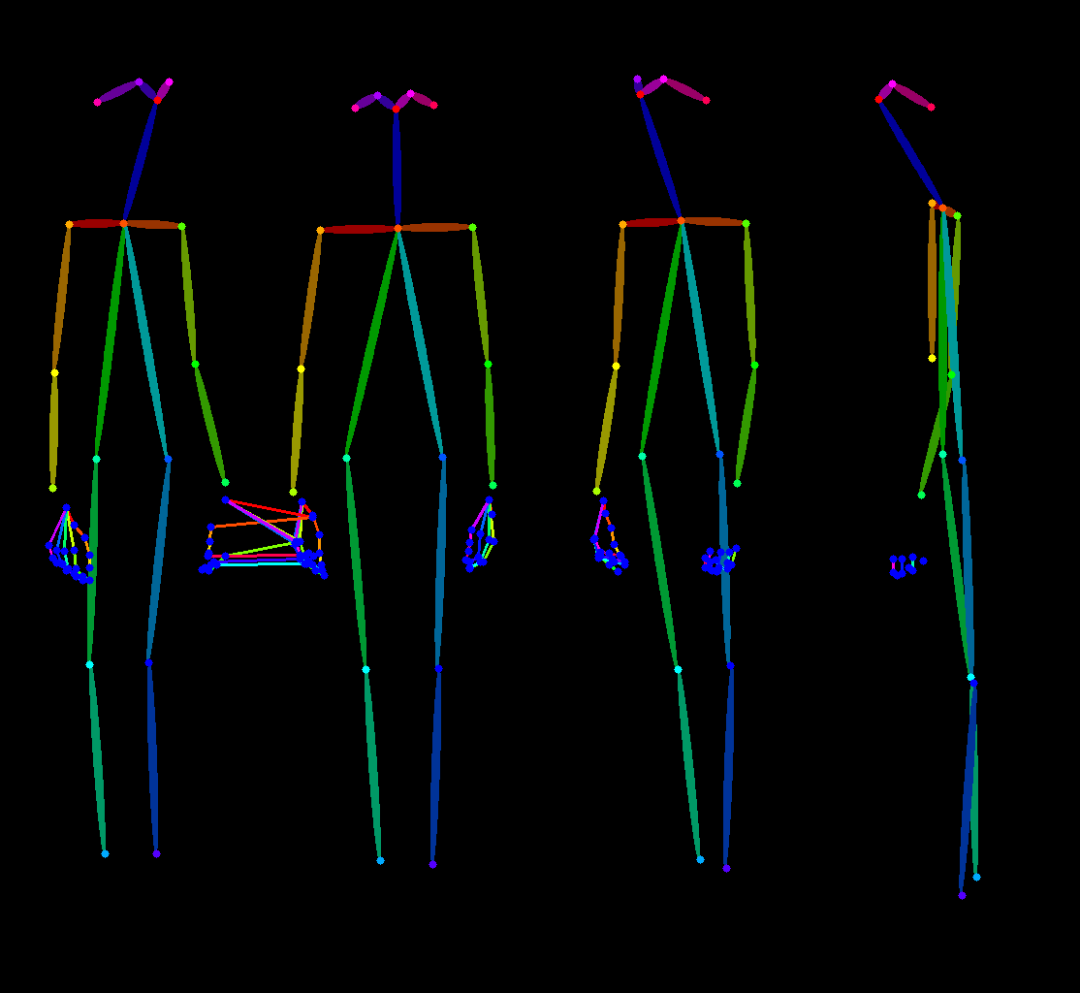


这份完整版的模型已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 3066
3066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









