










来源: AINLPer 微信公众号(每日论文干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2021-11-16
论文信息:REBEL: RelationExtraction By End-to-end Language generation
源码地址:https://github.com/Babelscape/rebel
今天给大家分享一篇关于关系抽取的文章,关系抽取是自然语言处理中信息抽取(EI)的重要组成部分。如果您对信息抽取、关系抽取、实体抽取、事件抽取还不是很了解可以阅读以下几篇文章:
必看!一文了解信息抽取(Information Extraction)【事件抽取】
必看!一文了解信息抽取(Information Extraction)【关系抽取】
前言介绍
传统情况下,关系抽取这项任务被视为两个问题。首先要在文本中抽取实体,如命名实体识别 (NER),然后进行关系分类(RC),检查提取的实体之间是否存在关联关系。但是确定哪些实体真正共存在关系是一件比较有挑战的事情,它需要额外的处理步骤,例如负采样和昂贵的标注过程。
最近,端到端方法已被用于同时处理这两项任务。此任务通常称为关系提取或端到端关系提取 (RE)。在这种情况下,模型同时针对两个目标进行训练。模型可以分配特定的管道来处理的不同任务,例如一方面是 NER,另一方面是对预测实体 (RC) 之间的关系进行分类。尽管采用这种方式效果比较好,但是这些模型通常很复杂,以任务为中心的元素需要适应关系或实体类型的数量,并且它们不够灵活,无法处理不同性质(句子与文档级别)或领域的文本 . 此外,它们通常需要很长的训练时间才能对新数据进行微调。
在本文中,我们提出了 REBEL(Relation Extraction By End-to-end Language generation),一种自回归方法,将关系提取作为一项seq2seq任务,与REBEL数据集(一个大型远程监控数据集)结合使用并且该数据集是通过利用自然语言推理模型获得的。由于我们采用了简单的三元组分解成文本序列,本文的方法比以前的端到端方法有一些优势。通过使用本文的新数据集对编码器-解码器转换器(BART)进行预训练,REBEL在几次微调期间在一系列关系提取(RE)基线上实现了最好的结果。它的简单性使它能够高度灵活地适应新的域或更长的文档。由于在预训练阶段之后仍然使用相同的模型权重,因此无需从头开始训练特定于模型的组件,从而提高训练效率。
此外,虽然该模型是为关系提取而设计的,但同样的方法可以推广到关系分类,仍然能够获得不错的效果。我们使REBEL既可以作为一个独立的模型使用,能够提取200多种不同的关系类型,也可以作为一个经过预训练的RE模型使用,可以轻松地在新的RE和RC数据集上进行微调。我们还提供REBEL数据集,以及管道用于从任何 Wikipedia 转储中提取高质量的 RE 数据集。
REBEL模型介绍
我们将关系提取和分类作为生成任务处理:我们使用自回归模型输出输入文本中存在的每个三元组。 为此,我们采用 BART-large[1]作为基本模型。在我们的方法中,我们将包含实体的原始输入语句以及它们之间的隐式关系转换为一组显式引用这些关系的三元组。因此,我们需要将三元组表示为模型解码的令牌序列。我们设计了一种使用特殊标记的可逆线性化,使模型能够以三元组的形式输出文本中的关系,同时最小化需要解码的标记数量。
对于 REBEL,我们将数据集中的文本作为输入,并将线性化的三元组作为输出。 如果 x 是我们的输入句子,y 是 x 中关系线性化的结果,如第 3.1 节所述,REBEL 的任务是在给定 x 的情况下自回归生成 y:
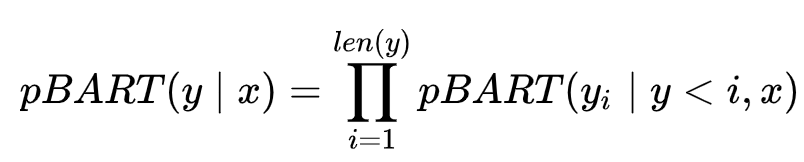
通过在这样的任务上微调BART,使用摘要或机器翻译中的交叉熵损失,我们最大化了在给定输入文本的情况下生成线性化三元组的对数可能性。
三元组线性化
对于 RE,我们希望将三元组表示为一系列标记,以便我们可以检索原始关系并最小化要生成的标记数量,从而使解码更有效。我们引入了一组新的标记作为标记,以实现上述线性化。 用新的头部实体标记新三元组的开始,然后是输入文本中该实体的表面形式。 标记头部实体的结束和尾部实体表面形式的开始。 以表面形式标记尾部实体的结束和头部和尾部实体之间关系的开始。为了在解码的三元组中获得一致的顺序,我们按实体在输入文本中的出现顺序对实体进行排序,并按照该顺序线性化三元组。三元组也将按头部实体分组。因此,第一个三元组将是第一个出现头部实体的那个,接下来的关系将是与该头部实体相关的第一个出现的尾部实体,然后是具有相同头部实体的其余三元组。无需每次都指定头部实体,减少解码后的文本长度。一旦与该头实体不再有关系,就会开始一组新的关系,第二个头实体出现在文本中,重复相同的过程,直到没有更多的三元组需要线性化。如下图所示:

图 中显示了关系列表和输入句子的线性化过程示例。 请注意 This Must Be the Place 如何作为主题出现两次,但它作为主题实体仅在输出中出现一次。 通过考虑特殊标记,可以轻松检索原始三元组。 在 RE 数据集中,实体类型也存在于三元组中,需要由模型进行预测。 在这种情况下,我们对上面算法做相应的修改,而不是 和 ,我们为每个实体类型添加新的标记,例如 或 ,分别用于个人或组织,并使用 它们以相同的方式,指示它们跟随的实体的类型。
REBEL数据集
自回归转换器模型(如 BARTor T5)已被证明在不同的生成任务(如翻译或摘要)上表现良好,但它们确实需要大量数据进行训练。 另一方面,端到端关系提取数据集很少,而且通常很小。在Elsahar 等人的研究中, (2018) T-REx 数据集是通过设计一个从 DBpedia 摘要中提取实体和关系的管道来创建的,以克服缺乏大型 RE 数据集的问题。 虽然结果是一个大型数据集,但注释的质量存在一些问题。 首先,使用有点旧的实体链接工具(Daiber 等人,2013 年)会导致实体被错误地消除歧义。 由于关系是通过使用这些实体提取的,因此会导致关系缺失或错误。 此外,大多数关系是通过假设提取的,因此,如果这两个实体存在于文本中,那么这种关系就必然存在。
为此我们通过扩展他们的管道来创建一个大型银数据集来克服这些问题,用作 REBEL 的预训练。 我们使用 Wikipedia2 摘要,即每个 Wikipedia 页面在目录之前的部分,使用 wikiextractor (Attardi, 2015) 提取。 然后,我们使用 wikimapper3 将文本中存在的实体作为超链接以及日期和值链接到 Wikidata 实体。 由此,我们提取了维基数据中这些实体之间存在的所有关系。 我们的系统可以与多种语言的任何维基百科转储一起使用,使用多核进程和 SQL 实现轻松快速的提取,以避免维基数据转储的内存问题。
实验结果
与基线结果进行对比:
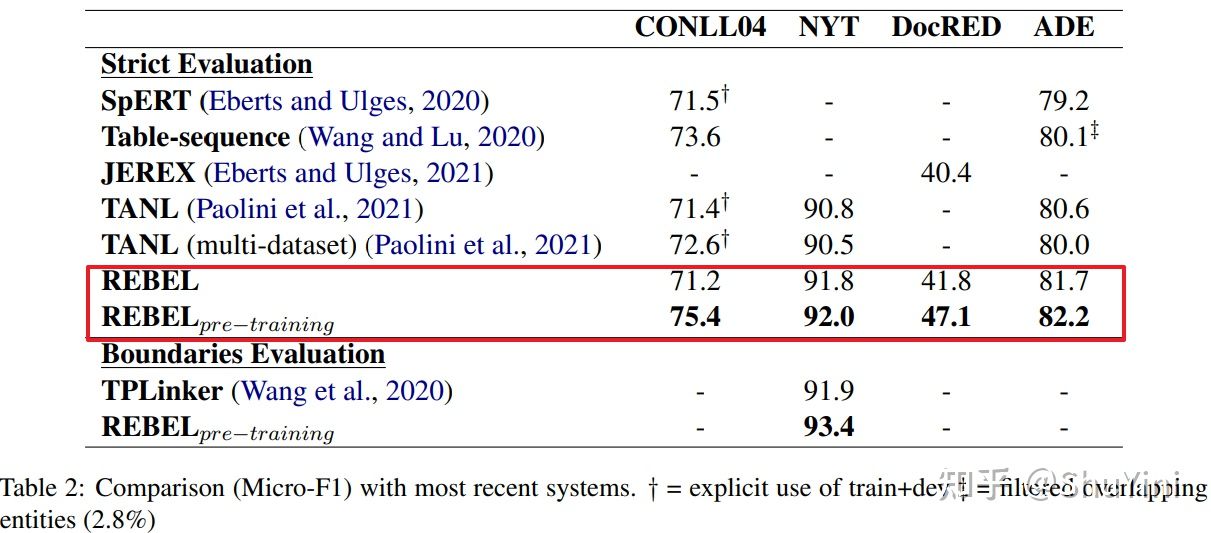
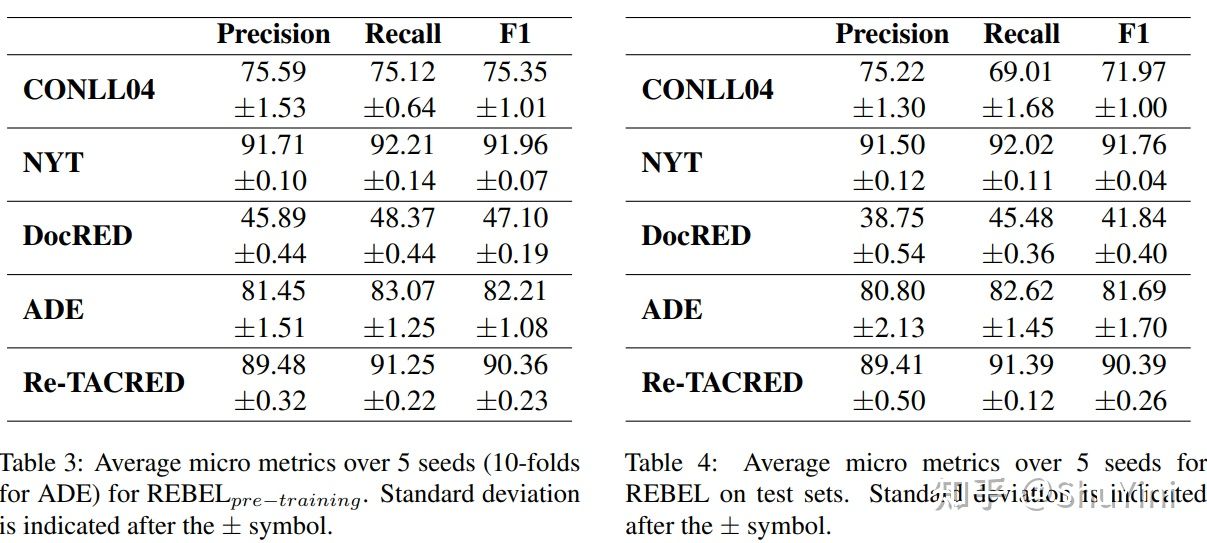
模型在关系分类(RC)上表现

推荐阅读
1、【南洋理工&&含源码】鲁棒问答的内省蒸馏(IntroD)
2、【NLP论文速递】邮件主题生成 && 舆论检测及立场分类
3、【英国谢菲尔德大学&&含源码】社交媒体舆论控制(RP-DNN)
4、【硬核干货,请拿走!!】历年IJCAI顶会论文整理(2016-2021)
6、必看!!【AINLPer】自然语言处理(NLP)领域知识&&资料大分享
7、收藏!「自然语言处理(NLP)」你可能用到的数据集(一)
8、收藏!「自然语言处理(NLP)」你可能用到的数据集(二)
9、重磅!「自然语言处理(NLP)」一千多万公司企业注册数据集
10、收藏!!「自然语言处理(NLP)」学术界全球知名学者教授信息大盘点(全)!
11、「自然语言处理(NLP)论文推送」清华大学XQA数据集(含源码)!
最后不是最后
关注 AINLPer 微信公众号(每日都有最新的论文推荐给你!!)

















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









