







一、FP16是什么?
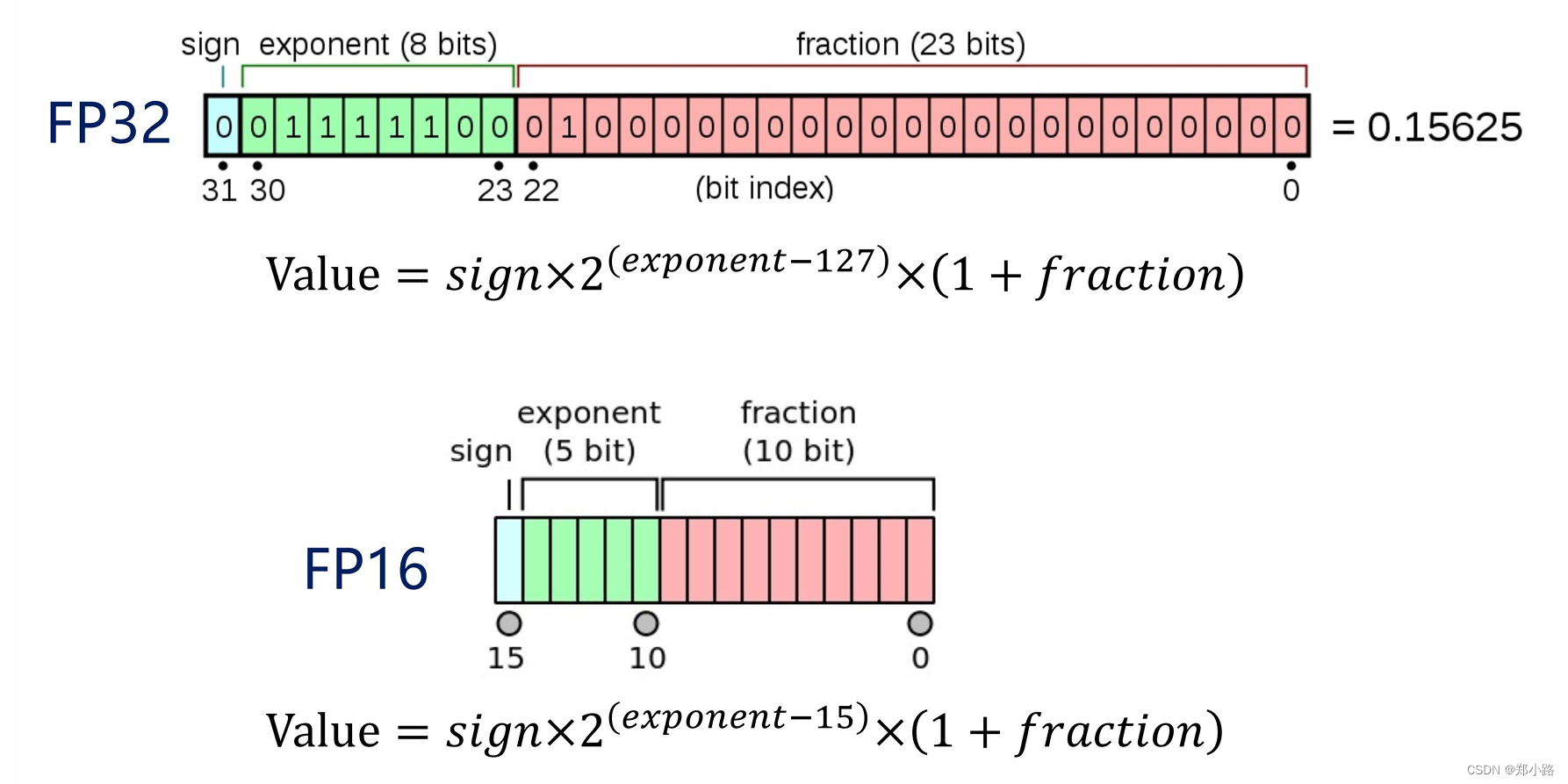
在介绍FP16之前,我们先简单介绍一下FP32,FP32是深度学习模型训练与部署的默认精度类型,FP32包括1位符号位、8位指数位、23位小数位,其中指数位影响数值可表示范围,小数位影响精度。在学习C语言时,我们接触到了单精度浮点数、双精度浮点数、INT型整数等,这里的单精度浮点数Float,它在机内占4个字节、有效数字8位、表示范围:-3.40E+38 ~ +3.40E+38,其实它的精度类型就是FP32。
所以这里的FP16也是一种精度类型,只不过它的位数只有16位,被称为半精度浮点数,它包括1位符号位、5位指数位、10位小数位,由于位数的减少,所以FP16的表示范围和精度都比FP32低,但是对于模型部署来说,数据位数的减少可以让计算复杂度降低,加速模型推理速度。
下面是FP32和FP16的直观表示图以及相应的转换公式:
详细的精度解析可以参考:
模型精度问题(FP16,FP32,TF32,INT8)精简版
二、FP16设置
1.设置FP16 Flag
在TensorRT中设置FP16其实特别简单,只需要我们在构建期设置一个FP16的flag,即可开启FP16的模型构建与推理。
相应代码如下:
logger = trt.Logger(trt.Logger.ERROR)
builder = trt.Builder(logger)
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
profile = builder.create_optimization_profile()
config = builder.create_builder_config()
config.set_flag(trt.BuilderFlag.FP16)
2.查看是否支持FP16
代码如下:
if builder.platform_has_fast_fp16:
builder_config.set_flag(trt.BuilderFlag.FP16)
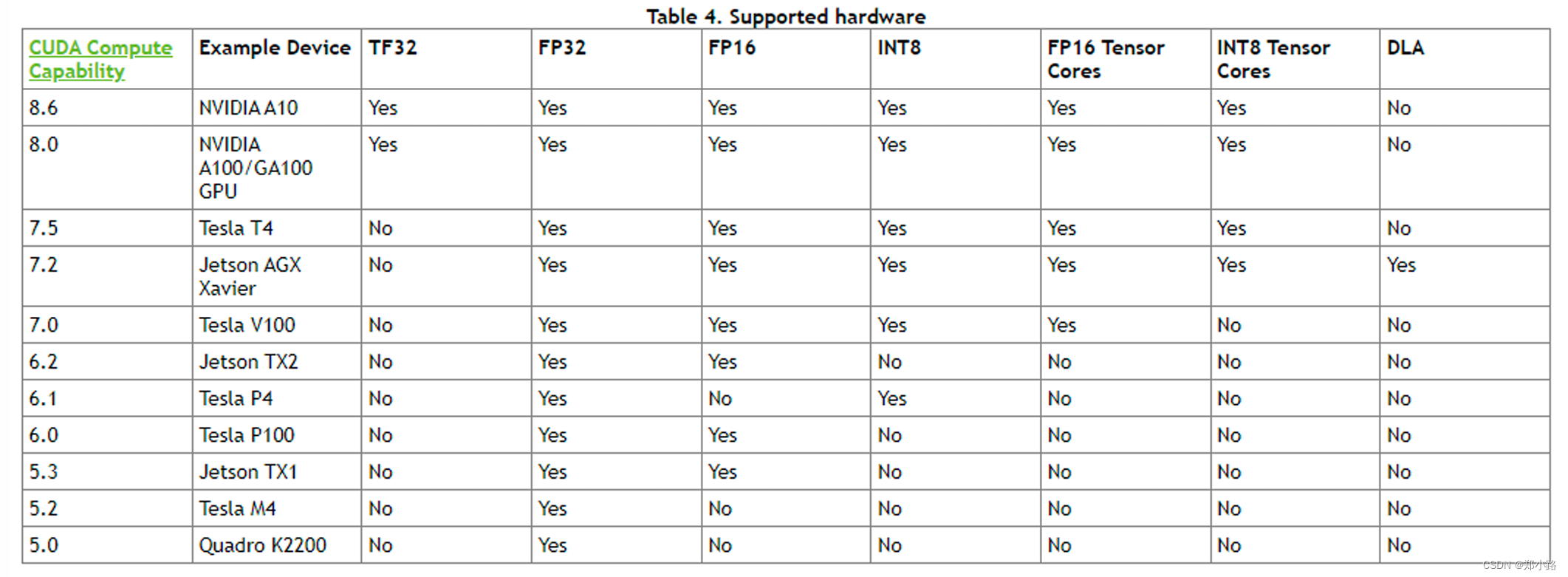
注意:不同版本的TensorRT查看是否支持FP16的方法可能不同,可查阅官方API文档
总结
FP16优化加速的原理和实际设置都相对简单,大家在用TensorRT进行模型推理时可以尝试打开FP16模式进行实际推理。

















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









