










前言
RAG的兴起,越来越多的人开始关注文档结构化解析的效果,这个赛道变得非常的同质化。
关于文档智能解析过程中的每个技术环节的技术点,前期文章详细介绍了很多内容:
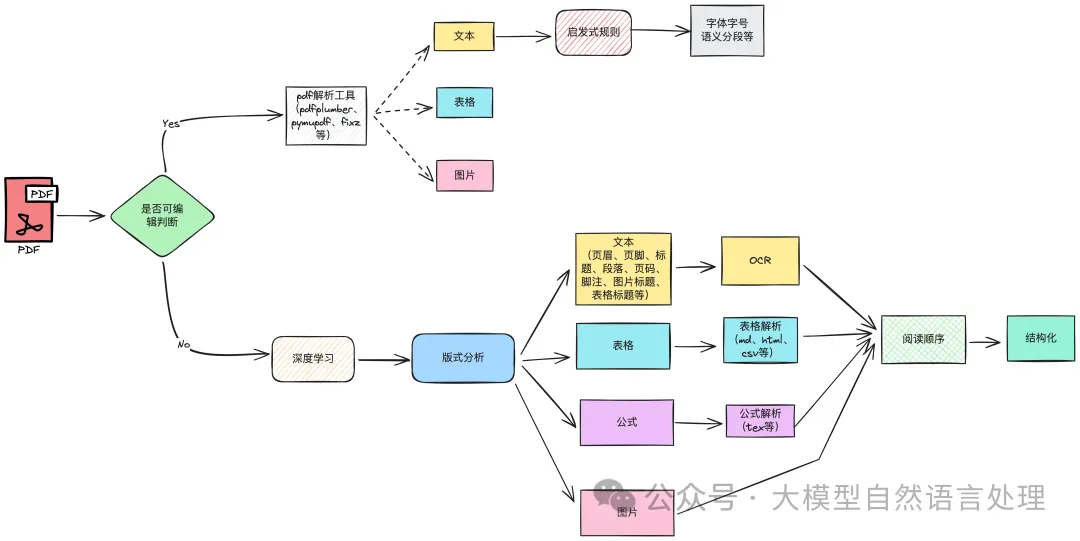
下面我们简单的看看Docling这个PDF文档解析框架里面都有什么技术。
方法
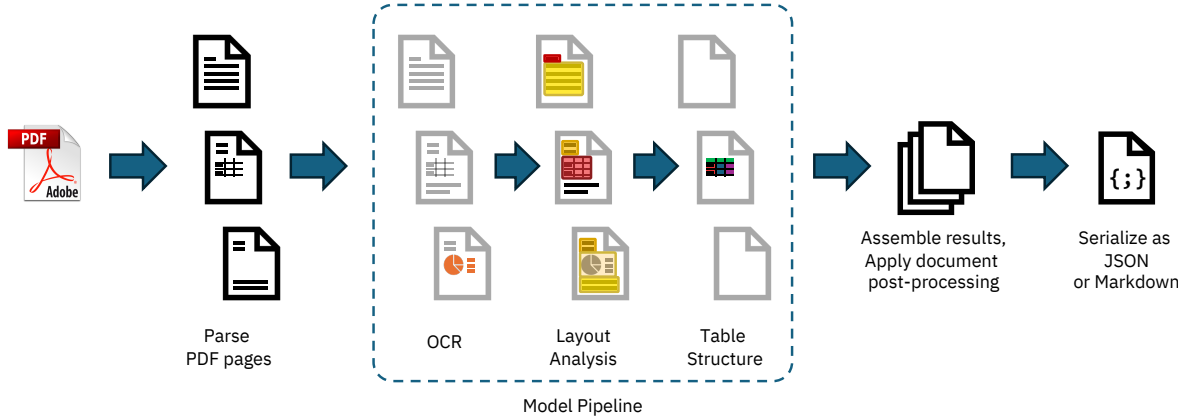
-
布局分析模型
首先,Docling使用一个布局分析模型,这是一个对象检测器,用于预测给定页面图像上各种元素的边界框和类别。其架构源自RT-DETR,并在DocLayNet数据集上重新训练。推理依赖于onnxruntime。笔者在前面的文章也提到过,版式分析非常依赖于场景数据,因此,该模型仅在DocLayNet数据集上进行训练,无法满足一些常见的中文场景诉求,并且采用RT-DETR进行训练,模型参数较大。这一块的替代可以采用之前开源的轻量版式分析模型。支持包含段落信息等研报、论文等中文场景的细粒度布局检测。
地址:https://github.com/360AILAB-NLP/360LayoutAnalysis

-
表格结构识别模型:其次,Docling使用TableFormer表格结构识别模型模型。它可以根据输入图像预测给定表格的逻辑行和列结构。推理依赖于PyTorch。
-
OCR文字识别:Docling还提供了可选的OCR支持,例如用于扫描件PDF。默认情况下,Docling使用EasyOCR引擎,该引擎以高分辨率(216 dpi)页面图像进行OCR,以捕获小字体细节。
-
处理管道:Docling实现了一个线性处理管道,按顺序对每个文档执行操作。每个文档首先由PDF后端解析,以检索程序化文本标记和渲染每页的位图图像。然后,标准模型管道独立应用于文档中的每一页,以提取特征和内容,如布局和表格结构。最后,所有页面的结果汇总并通过后处理阶段传递,以增强元数据、检测文档语言、推断阅读顺序并最终组装一个可序列化为JSON或Markdown的类型化文档对象。
结果
-
处理速度:在MacBook Pro M3 Max上,使用4个线程时,Docling的解决方案时间为177秒,吞吐量为每秒1.27页,峰值内存使用量为6.20 GB。使用16个线程时,解决方案时间为167秒,吞吐量为每秒1.34页,峰值内存使用量为未记录。
-
OCR性能:默认情况下,OCR引擎以高分辨率页面图像进行OCR,但运行速度较慢(每页超过30秒)。
-
资源效率:在Intel Xeon E5-2690上,使用4个线程时,解决方案时间为375秒,吞吐量为每秒0.60页,峰值内存使用量为未记录。使用16个线程时,解决方案时间为244秒,吞吐量为每秒0.92页,峰值内存使用量为6.16 GB。
总结
文档智能解析现在非常同质化,实际上能解决自己场景文档解析的实用工具很少,不过可以参考下Docling工程上的具体优化,如多线程等。结合一些其他较强的开源或者自研的小模型,进行替换,打造自己的文档解析工具。
参考文献
https://github.com/DS4SD/docling

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









